Empowering Whisper as a Joint Multi-Talker and Target-Talker Speech Recognition System

0

Sign in to get full access
Overview
- Presents a method to improve the Whisper speech recognition model to handle multi-talker and target-talker scenarios
- Introduces techniques to enable Whisper to recognize speech from multiple speakers and focus on a specific target speaker
- Aims to enhance the versatility and performance of the Whisper model in real-world speech recognition applications
Plain English Explanation
The research paper describes a way to enhance the capabilities of the Whisper speech recognition model. Whisper is a popular AI model that can transcribe speech into text, but it was originally designed to work with a single speaker. The researchers wanted to make Whisper better at handling more complex, real-world scenarios where there might be multiple people speaking at the same time.
To do this, they developed several techniques to enable Whisper to recognize speech from multiple talkers and also focus on a specific "target" talker of interest. This could be useful in applications like conference calls, interviews, or recordings with background noise, where you want the AI to accurately transcribe the speech of a particular person.
The paper explains the details of how they modified Whisper to achieve these multi-talker and target-talker capabilities. The key ideas involve using additional neural network components to isolate the target speaker's voice and filter out other voices or background sounds. The researchers also describe how they trained the model on diverse datasets to improve its performance in these challenging scenarios.
Ultimately, the goal is to make Whisper more versatile and effective for real-world speech recognition tasks, where having the ability to handle multiple speakers and focus on a specific person's voice can be very important.
Technical Explanation
The researchers propose a method to empower Whisper as a joint multi-talker and target-talker speech recognition system.
They introduce several techniques to enable Whisper to recognize speech from multiple speakers and focus on a specific "target" speaker of interest:
-
Speaker Isolation: The researchers add a speaker isolation module to the Whisper model, which uses an attention mechanism to isolate the target speaker's voice from the other speakers.
-
Speaker Conditioning: They also incorporate speaker conditioning, where information about the target speaker is provided as an additional input to the model to help it focus on that individual.
-
Multi-Talker Training: To train the model to handle multi-talker scenarios, the researchers use a diverse dataset that includes recordings with multiple speakers.
These modifications allow the enhanced Whisper model to perform well in real-world situations with background noise, overlapping speech, and a need to transcribe a specific person's voice. The paper also discusses techniques like simultaneous transcription and incremental adaptation to further improve the model's performance.
Additionally, the researchers explore multi-task training approaches and prompt-based fine-tuning to enhance the Whisper model's capabilities in specific domains or tasks.
Critical Analysis
The paper presents a well-designed approach to extend the Whisper model's capabilities, but there are a few potential limitations and areas for further research:
-
Dataset Diversity: While the researchers used a diverse dataset for multi-talker training, the performance of the model may still be constrained by the available data. Expanding the dataset, especially with more challenging real-world scenarios, could further improve the model's robustness.
-
Real-Time Performance: The paper does not provide detailed information about the computational complexity or latency of the proposed techniques. Ensuring that the enhanced Whisper model can operate in real-time scenarios may require additional optimization.
-
Generalization to Other Tasks: The focus of this research is on speech recognition, but it would be interesting to explore whether the speaker isolation and conditioning techniques could also benefit other speech-related tasks, such as speaker diarization or voice conversion.
-
Ethical Considerations: While the proposed methods can be useful in many applications, there may be concerns about privacy and the potential misuse of these capabilities, such as in surveillance or eavesdropping. The researchers should discuss potential ethical implications and mitigation strategies.
Conclusion
The research presented in this paper is a significant step towards enhancing the Whisper speech recognition model to handle more complex, real-world scenarios involving multiple speakers and target-specific transcription. The proposed techniques for speaker isolation, speaker conditioning, and multi-talker training demonstrate the potential to make Whisper a more versatile and practical tool for a wide range of speech recognition applications.
The improvements to Whisper's capabilities could have important implications for fields like remote conferencing, interview transcription, and assistive technologies, where the ability to focus on a specific speaker's voice is crucial. As the researchers continue to refine and expand on this work, it will be important to also consider the ethical implications and ensure that these advancements are used responsibly and for the benefit of society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Empowering Whisper as a Joint Multi-Talker and Target-Talker Speech Recognition System
Lingwei Meng, Jiawen Kang, Yuejiao Wang, Zengrui Jin, Xixin Wu, Xunying Liu, Helen Meng
Multi-talker speech recognition and target-talker speech recognition, both involve transcription in multi-talker contexts, remain significant challenges. However, existing methods rarely attempt to simultaneously address both tasks. In this study, we propose a pioneering approach to empower Whisper, which is a speech foundation model, to tackle joint multi-talker and target-talker speech recognition tasks. Specifically, (i) we freeze Whisper and plug a Sidecar separator into its encoder to separate mixed embedding for multiple talkers; (ii) a Target Talker Identifier is introduced to identify the embedding flow of the target talker on the fly, requiring only three-second enrollment speech as a cue; (iii) soft prompt tuning for decoder is explored for better task adaptation. Our method outperforms previous methods on two- and three-talker LibriMix and LibriSpeechMix datasets for both tasks, and delivers acceptable zero-shot performance on multi-talker ASR on AishellMix Mandarin dataset.
Read more8/27/2024
0
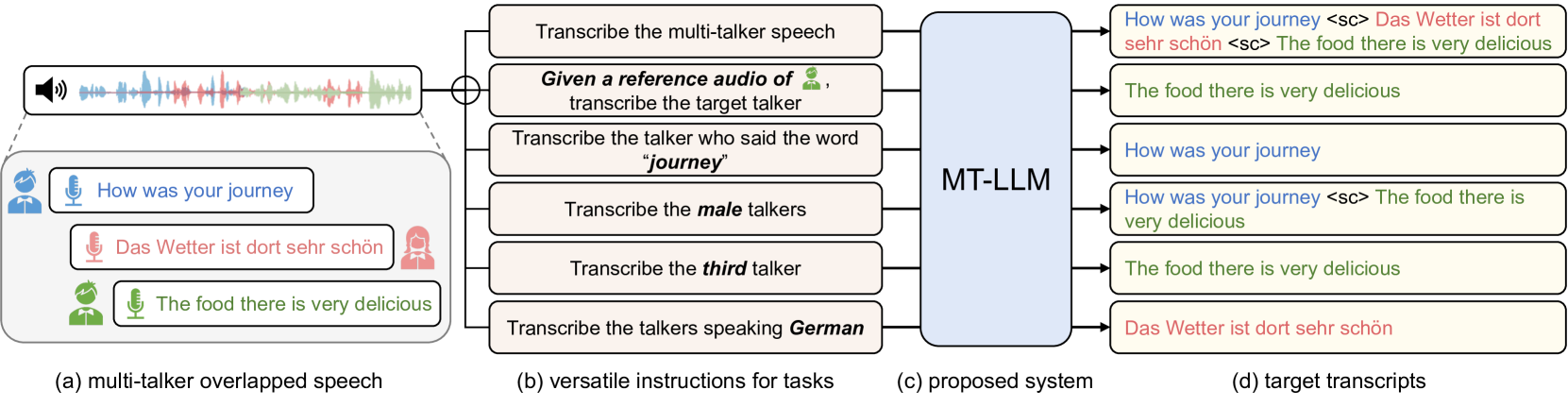
New!Large Language Model Can Transcribe Speech in Multi-Talker Scenarios with Versatile Instructions
Lingwei Meng, Shujie Hu, Jiawen Kang, Zhaoqing Li, Yuejiao Wang, Wenxuan Wu, Xixin Wu, Xunying Liu, Helen Meng
Recent advancements in large language models (LLMs) have revolutionized various domains, bringing significant progress and new opportunities. Despite progress in speech-related tasks, LLMs have not been sufficiently explored in multi-talker scenarios. In this work, we present a pioneering effort to investigate the capability of LLMs in transcribing speech in multi-talker environments, following versatile instructions related to multi-talker automatic speech recognition (ASR), target talker ASR, and ASR based on specific talker attributes such as sex, occurrence order, language, and keyword spoken. Our approach utilizes WavLM and Whisper encoder to extract multi-faceted speech representations that are sensitive to speaker characteristics and semantic context. These representations are then fed into an LLM fine-tuned using LoRA, enabling the capabilities for speech comprehension and transcription. Comprehensive experiments reveal the promising performance of our proposed system, MT-LLM, in cocktail party scenarios, highlighting the potential of LLM to handle speech-related tasks based on user instructions in such complex settings.
Read more9/16/2024
0
Efficient Compression of Multitask Multilingual Speech Models
Thomas Palmeira Ferraz
Whisper is a multitask and multilingual speech model covering 99 languages. It yields commendable automatic speech recognition (ASR) results in a subset of its covered languages, but the model still underperforms on a non-negligible number of under-represented languages, a problem exacerbated in smaller model versions. In this work, we examine its limitations, demonstrating the presence of speaker-related (gender, age) and model-related (resourcefulness and model size) bias. Despite that, we show that only model-related bias are amplified by quantization, impacting more low-resource languages and smaller models. Searching for a better compression approach, we propose DistilWhisper, an approach that is able to bridge the performance gap in ASR for these languages while retaining the advantages of multitask and multilingual capabilities. Our approach involves two key strategies: lightweight modular ASR fine-tuning of whisper-small using language-specific experts, and knowledge distillation from whisper-large-v2. This dual approach allows us to effectively boost ASR performance while keeping the robustness inherited from the multitask and multilingual pre-training. Results demonstrate that our approach is more effective than standard fine-tuning or LoRA adapters, boosting performance in the targeted languages for both in- and out-of-domain test sets, while introducing only a negligible parameter overhead at inference.
Read more5/3/2024

0
Simul-Whisper: Attention-Guided Streaming Whisper with Truncation Detection
Haoyu Wang, Guoqiang Hu, Guodong Lin, Wei-Qiang Zhang, Jian Li
As a robust and large-scale multilingual speech recognition model, Whisper has demonstrated impressive results in many low-resource and out-of-distribution scenarios. However, its encoder-decoder structure hinders its application to streaming speech recognition. In this paper, we introduce Simul-Whisper, which uses the time alignment embedded in Whisper's cross-attention to guide auto-regressive decoding and achieve chunk-based streaming ASR without any fine-tuning of the pre-trained model. Furthermore, we observe the negative effect of the truncated words at the chunk boundaries on the decoding results and propose an integrate-and-fire-based truncation detection model to address this issue. Experiments on multiple languages and Whisper architectures show that Simul-Whisper achieves an average absolute word error rate degradation of only 1.46% at a chunk size of 1 second, which significantly outperforms the current state-of-the-art baseline.
Read more6/17/2024