Performance is not enough: the story told by a Rashomon quartet

0
🚀
Sign in to get full access
Overview
- The paper explores the idea that equally effective machine learning models can provide very different explanations of the underlying relationships in the data.
- Inspired by Anscombe's quartet, the authors introduce a "Rashomon Quartet" - a set of four synthetic models with nearly identical predictive performance but distinct visual explanations.
- The goal is to encourage the use of model visualization techniques to go beyond simply comparing model performance and instead understand the different perspectives these models offer.
Plain English Explanation
The typical goal of supervised machine learning is to find the best model - the one that performs the best on a particular metric. However, what if you have multiple models that all perform equally well, but they explain the underlying relationships in the data in very different ways?
The authors were inspired by the classic Anscombe's quartet - a set of four datasets with nearly identical summary statistics, but very different visual patterns. They wanted to see if a similar phenomenon could occur with machine learning models.
To test this, they created a synthetic dataset and trained four different models on it. All four models had practically identical predictive performance, but when the authors visually explored the models' explanations, they found that each one highlighted quite different relationships in the data.
The key takeaway is that model performance alone doesn't tell the whole story. Even if multiple models achieve similar scores, they may be capturing fundamentally different patterns in the underlying data. The authors argue that using visualization techniques to compare model explanations can provide valuable additional insights beyond just optimizing for predictive accuracy.
Technical Explanation
The paper introduces the concept of a "Rashomon Quartet" - a set of four machine learning models trained on the same synthetic dataset that have nearly identical predictive performance, but distinct visual explanations of the relationships in the data.
The authors first generated a 2D dataset with 100 data points, where the true underlying relationship was a non-linear function with added noise. They then trained four different models on this dataset:
- A linear regression model
- A spline regression model
- A random forest model
- A neural network model
Despite all four models achieving very similar R-squared values (around 0.94), the visual representations of their explanations were dramatically different. The linear model showed a simple linear trend, the spline model captured the non-linearity, the random forest displayed a more complex nonlinear shape, and the neural network revealed an intricate, wavelike pattern.
The authors argue that this "Rashomon Quartet" illustrates how multiple, equally accurate models can shed light on different aspects of the data-generating process. They suggest that solely optimizing for predictive performance can obscure these nuanced differences in model explanations.
Critical Analysis
The key strength of this paper is its clear, illustrative example that demonstrates how models with similar predictive power can provide divergent explanations of the underlying data. This aligns with the growing recognition in machine learning that model interpretability and transparency are just as important as raw performance metrics.
One limitation acknowledged by the authors is that their example uses a synthetic dataset, rather than real-world data. Applying this "Rashomon Quartet" concept to more complex, real-world problems would be a valuable next step to further validate the practical implications.
Additionally, the paper does not provide guidance on how to systematically identify and compare these alternative model explanations in practice. Developing principled frameworks or toolkits for model visualization and explanation comparison would enhance the accessibility and actionability of this research.
Lastly, the authors could have delved deeper into the potential risks or downsides of relying on a single model's explanation, even if it performs well. Exploring scenarios where ignoring alternative perspectives could lead to missed insights or even harmful decision-making would strengthen the paper's real-world relevance.
Overall, this work serves as a compelling proof-of-concept that encourages the machine learning community to look beyond just optimizing predictive accuracy and to also consider the diversity of explanations that different models can provide. Expanding on these ideas could yield important advancements in model interpretability, robust estimation, and model selection.
Conclusion
This paper introduces the intriguing concept of a "Rashomon Quartet" - a set of machine learning models with nearly identical predictive performance but starkly different visual explanations of the underlying data relationships. By highlighting this phenomenon, the authors encourage the use of model visualization and comparison techniques to gain a richer understanding of complex datasets, beyond just optimizing for predictive accuracy.
Embracing this more holistic view of model evaluation could lead to important advances in areas like model interpretability, robust estimation, and model selection. Ultimately, this research underscores the value of going beyond singular model explanations and considering the diversity of perspectives that multiple, equally effective models can provide.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🚀
0
Performance is not enough: the story told by a Rashomon quartet
Przemyslaw Biecek, Hubert Baniecki, Mateusz Krzyzinski, Dianne Cook
The usual goal of supervised learning is to find the best model, the one that optimizes a particular performance measure. However, what if the explanation provided by this model is completely different from another model and different again from another model despite all having similarly good fit statistics? Is it possible that the equally effective models put the spotlight on different relationships in the data? Inspired by Anscombe's quartet, this paper introduces a Rashomon Quartet, i.e. a set of four models built on a synthetic dataset which have practically identical predictive performance. However, the visual exploration reveals distinct explanations of the relations in the data. This illustrative example aims to encourage the use of methods for model visualization to compare predictive models beyond their performance.
Read more4/12/2024

0
Amazing Things Come From Having Many Good Models
Cynthia Rudin, Chudi Zhong, Lesia Semenova, Margo Seltzer, Ronald Parr, Jiachang Liu, Srikar Katta, Jon Donnelly, Harry Chen, Zachery Boner
The Rashomon Effect, coined by Leo Breiman, describes the phenomenon that there exist many equally good predictive models for the same dataset. This phenomenon happens for many real datasets and when it does, it sparks both magic and consternation, but mostly magic. In light of the Rashomon Effect, this perspective piece proposes reshaping the way we think about machine learning, particularly for tabular data problems in the nondeterministic (noisy) setting. We address how the Rashomon Effect impacts (1) the existence of simple-yet-accurate models, (2) flexibility to address user preferences, such as fairness and monotonicity, without losing performance, (3) uncertainty in predictions, fairness, and explanations, (4) reliable variable importance, (5) algorithm choice, specifically, providing advanced knowledge of which algorithms might be suitable for a given problem, and (6) public policy. We also discuss a theory of when the Rashomon Effect occurs and why. Our goal is to illustrate how the Rashomon Effect can have a massive impact on the use of machine learning for complex problems in society.
Read more7/11/2024

0
Efficient Exploration of the Rashomon Set of Rule Set Models
Martino Ciaperoni, Han Xiao, Aristides Gionis
Today, as increasingly complex predictive models are developed, simple rule sets remain a crucial tool to obtain interpretable predictions and drive high-stakes decision making. However, a single rule set provides a partial representation of a learning task. An emerging paradigm in interpretable machine learning aims at exploring the Rashomon set of all models exhibiting near-optimal performance. Existing work on Rashomon-set exploration focuses on exhaustive search of the Rashomon set for particular classes of models, which can be a computationally challenging task. On the other hand, exhaustive enumeration leads to redundancy that often is not necessary, and a representative sample or an estimate of the size of the Rashomon set is sufficient for many applications. In this work, we propose, for the first time, efficient methods to explore the Rashomon set of rule set models with or without exhaustive search. Extensive experiments demonstrate the effectiveness of the proposed methods in a variety of scenarios.
Read more6/6/2024
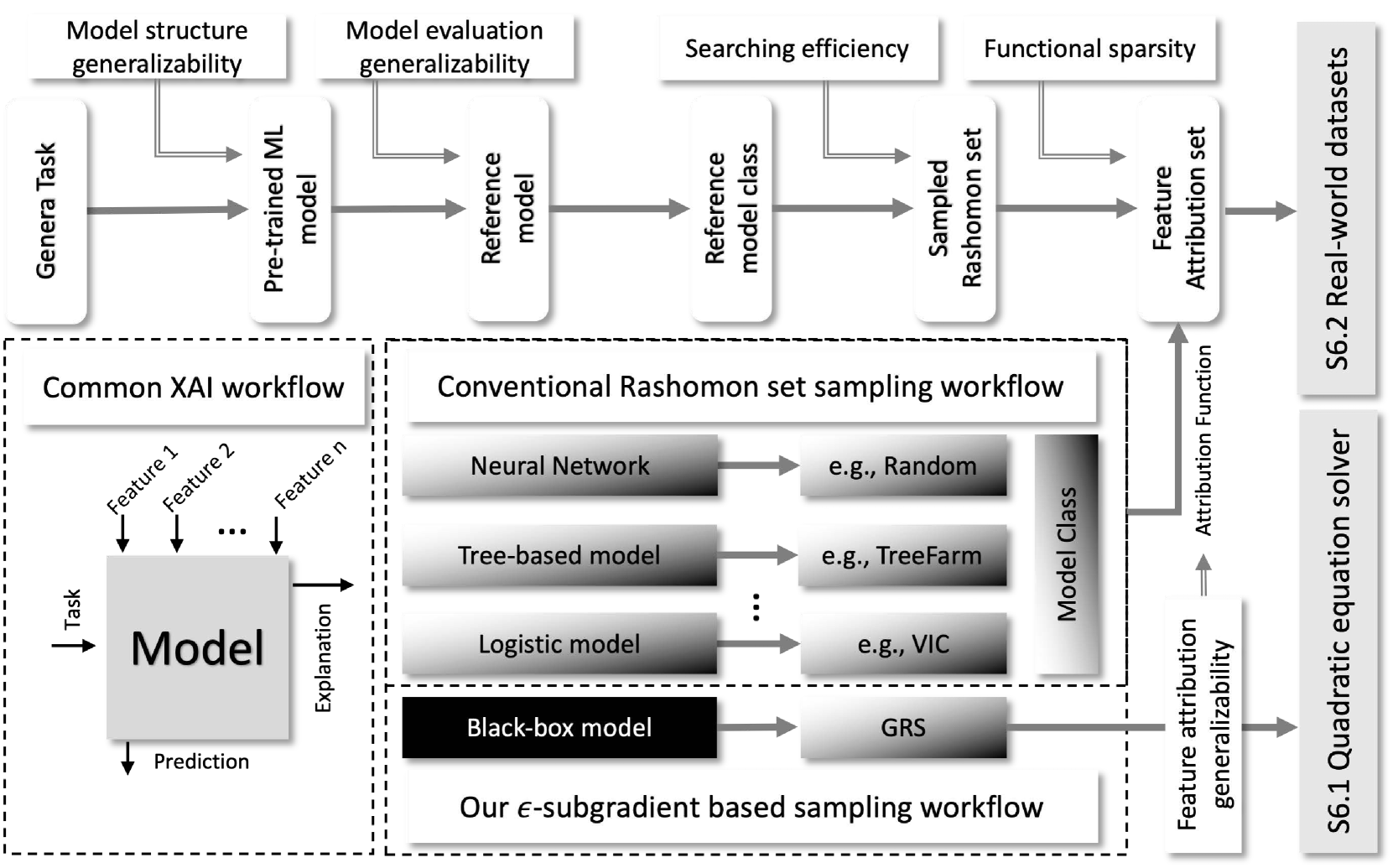
0
Practical Attribution Guidance for Rashomon Sets
Sichao Li, Amanda S. Barnard, Quanling Deng
Different prediction models might perform equally well (Rashomon set) in the same task, but offer conflicting interpretations and conclusions about the data. The Rashomon effect in the context of Explainable AI (XAI) has been recognized as a critical factor. Although the Rashomon set has been introduced and studied in various contexts, its practical application is at its infancy stage and lacks adequate guidance and evaluation. We study the problem of the Rashomon set sampling from a practical viewpoint and identify two fundamental axioms - generalizability and implementation sparsity that exploring methods ought to satisfy in practical usage. These two axioms are not satisfied by most known attribution methods, which we consider to be a fundamental weakness. We use the norms to guide the design of an $epsilon$-subgradient-based sampling method. We apply this method to a fundamental mathematical problem as a proof of concept and to a set of practical datasets to demonstrate its ability compared with existing sampling methods.
Read more7/29/2024