Permutation Decision Trees
2306.02617
0
0
🖼️
Abstract
Decision Tree is a well understood Machine Learning model that is based on minimizing impurities in the internal nodes. The most common impurity measures are Shannon entropy and Gini impurity. These impurity measures are insensitive to the order of training data and hence the final tree obtained is invariant to any permutation of the data. This is a limitation in terms of modeling when there are temporal order dependencies between data instances. In this research, we propose the adoption of Effort-To-Compress (ETC) - a complexity measure, for the first time, as an alternative impurity measure. Unlike Shannon entropy and Gini impurity, structural impurity based on ETC is able to capture order dependencies in the data, thus obtaining potentially different decision trees for different permutations of the same data instances, a concept we term as Permutation Decision Trees (PDT). We then introduce the notion of Permutation Bagging achieved using permutation decision trees without the need for random feature selection and sub-sampling. We conduct a performance comparison between Permutation Decision Trees and classical decision trees across various real-world datasets, including Appendicitis, Breast Cancer Wisconsin, Diabetes Pima Indian, Ionosphere, Iris, Sonar, and Wine. Our findings reveal that PDT demonstrates comparable performance to classical decision trees across most datasets. Remarkably, in certain instances, PDT even slightly surpasses the performance of classical decision trees. In comparing Permutation Bagging with Random Forest, we attain comparable performance to Random Forest models consisting of 50 to 1000 trees, using merely 21 trees. This highlights the efficiency and effectiveness of Permutation Bagging in achieving comparable performance outcomes with significantly fewer trees.
Create account to get full access
Overview
- Decision trees are a well-understood machine learning model that aim to minimize impurities in internal nodes
- Commonly used impurity measures are Shannon entropy and Gini impurity, which are insensitive to the order of training data
- This research proposes using Effort-To-Compress (ETC) as an alternative impurity measure that can capture order dependencies in the data
- The resulting Permutation Decision Trees (PDT) can produce different decision trees for different permutations of the same data instances
- Permutation Bagging is introduced to leverage the order-aware nature of PDT without the need for random feature selection and sub-sampling
Plain English Explanation
Decision trees are a type of machine learning model that make predictions by following a series of if-then rules. These rules are determined by repeatedly splitting the data into purer and purer subsets, based on the most informative features. The most common ways to measure the "purity" or "impurity" of these subsets are Shannon entropy and Gini impurity.
However, these impurity measures have a limitation - they don't care about the order of the training data. This means that if you shuffle the data, you'll get the same decision tree. But in some real-world situations, the order of the data instances can be important, like when modeling temporal dependencies.
To address this, the researchers in this paper propose using a different impurity measure called Effort-To-Compress (ETC). ETC is a complexity measure that can capture order dependencies in the data. This means that the resulting Permutation Decision Trees (PDT) can produce different decision trees for different permutations of the same data instances.
The researchers also introduce a new technique called Permutation Bagging, which combines multiple PDTs to get more robust and accurate predictions. Interestingly, they find that Permutation Bagging can achieve comparable performance to Random Forest models with 50 to 1000 trees, but using only 21 trees. This suggests that the Permutation Bagging approach is an efficient and effective way to leverage the order-aware nature of PDTs.
Technical Explanation
The key technical contributions of this research are:
-
Effort-To-Compress (ETC) as an Impurity Measure: Unlike Shannon entropy and Gini impurity, which are insensitive to the order of training data, the researchers propose using ETC as an alternative impurity measure that can capture order dependencies in the data.
-
Permutation Decision Trees (PDT): By using ETC as the impurity measure, the researchers developed Permutation Decision Trees (PDT), which can produce different decision trees for different permutations of the same data instances.
-
Permutation Bagging: The researchers introduce a new ensemble technique called Permutation Bagging, which combines multiple PDTs without the need for random feature selection and sub-sampling. This allows them to leverage the order-aware nature of PDTs to achieve comparable performance to Random Forest with significantly fewer trees.
The researchers evaluated the performance of PDT and Permutation Bagging on several real-world datasets, including Appendicitis, Breast Cancer Wisconsin, Diabetes Pima Indian, Ionosphere, Iris, Sonar, and Wine. Their findings show that PDT demonstrates comparable performance to classical decision trees across most datasets, and in certain instances, even slightly surpasses the performance of classical decision trees.
Critical Analysis
One potential limitation of this research is that the use of ETC as an impurity measure may not always be beneficial, especially in cases where the order of the data instances is not crucial to the problem at hand. The researchers acknowledge this and suggest that the choice of impurity measure should depend on the specific characteristics of the dataset and the problem being solved.
Additionally, the researchers did not provide a detailed analysis of the computational complexity and training time of the Permutation Bagging approach compared to other ensemble methods like Random Forest. This information would be valuable for understanding the practical implications and trade-offs of using this technique.
It would also be interesting to see the researchers explore the interpretability of the Permutation Decision Trees, as decision tree models are often valued for their ability to provide transparent and explainable predictions. Comparing the interpretability of PDT and classical decision trees could be a fruitful area for further research.
Conclusion
This research proposes a novel approach to decision tree-based machine learning by introducing Effort-To-Compress (ETC) as an alternative impurity measure that can capture order dependencies in the data. The resulting Permutation Decision Trees (PDT) and Permutation Bagging technique demonstrate the potential to achieve comparable performance to classical decision trees and Random Forest models, while potentially offering additional insights into the order-dependent patterns in the data. As machine learning continues to be applied to an ever-widening range of real-world problems, techniques like these that can adapt to the unique characteristics of the data may become increasingly valuable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Learning accurate and interpretable decision trees
Maria-Florina Balcan, Dravyansh Sharma
0
0
Decision trees are a popular tool in machine learning and yield easy-to-understand models. Several techniques have been proposed in the literature for learning a decision tree classifier, with different techniques working well for data from different domains. In this work, we develop approaches to design decision tree learning algorithms given repeated access to data from the same domain. We propose novel parameterized classes of node splitting criteria in top-down algorithms, which interpolate between popularly used entropy and Gini impurity based criteria, and provide theoretical bounds on the number of samples needed to learn the splitting function appropriate for the data at hand. We also study the sample complexity of tuning prior parameters in Bayesian decision tree learning, and extend our results to decision tree regression. We further consider the problem of tuning hyperparameters in pruning the decision tree for classical pruning algorithms including min-cost complexity pruning. We also study the interpretability of the learned decision trees and introduce a data-driven approach for optimizing the explainability versus accuracy trade-off using decision trees. Finally, we demonstrate the significance of our approach on real world datasets by learning data-specific decision trees which are simultaneously more accurate and interpretable.
5/28/2024

Online Learning of Decision Trees with Thompson Sampling
Ayman Chaouki, Jesse Read, Albert Bifet
0
0
Decision Trees are prominent prediction models for interpretable Machine Learning. They have been thoroughly researched, mostly in the batch setting with a fixed labelled dataset, leading to popular algorithms such as C4.5, ID3 and CART. Unfortunately, these methods are of heuristic nature, they rely on greedy splits offering no guarantees of global optimality and often leading to unnecessarily complex and hard-to-interpret Decision Trees. Recent breakthroughs addressed this suboptimality issue in the batch setting, but no such work has considered the online setting with data arriving in a stream. To this end, we devise a new Monte Carlo Tree Search algorithm, Thompson Sampling Decision Trees (TSDT), able to produce optimal Decision Trees in an online setting. We analyse our algorithm and prove its almost sure convergence to the optimal tree. Furthermore, we conduct extensive experiments to validate our findings empirically. The proposed TSDT outperforms existing algorithms on several benchmarks, all while presenting the practical advantage of being tailored to the online setting.
4/10/2024
🗣️
Decision Machines: An Extension of Decision Trees
Jinxiong Zhang
0
0
Here is a compact representation of binary decision trees. We can explicitly draw the dependencies between prediction and binary tests in decision trees and construct a procedure to guide the input instance from the root to its exit leaf. And we provided a connection between decision trees and error-correcting output codes. Then we built a bridge from tree-based models to attention mechanisms.
6/4/2024
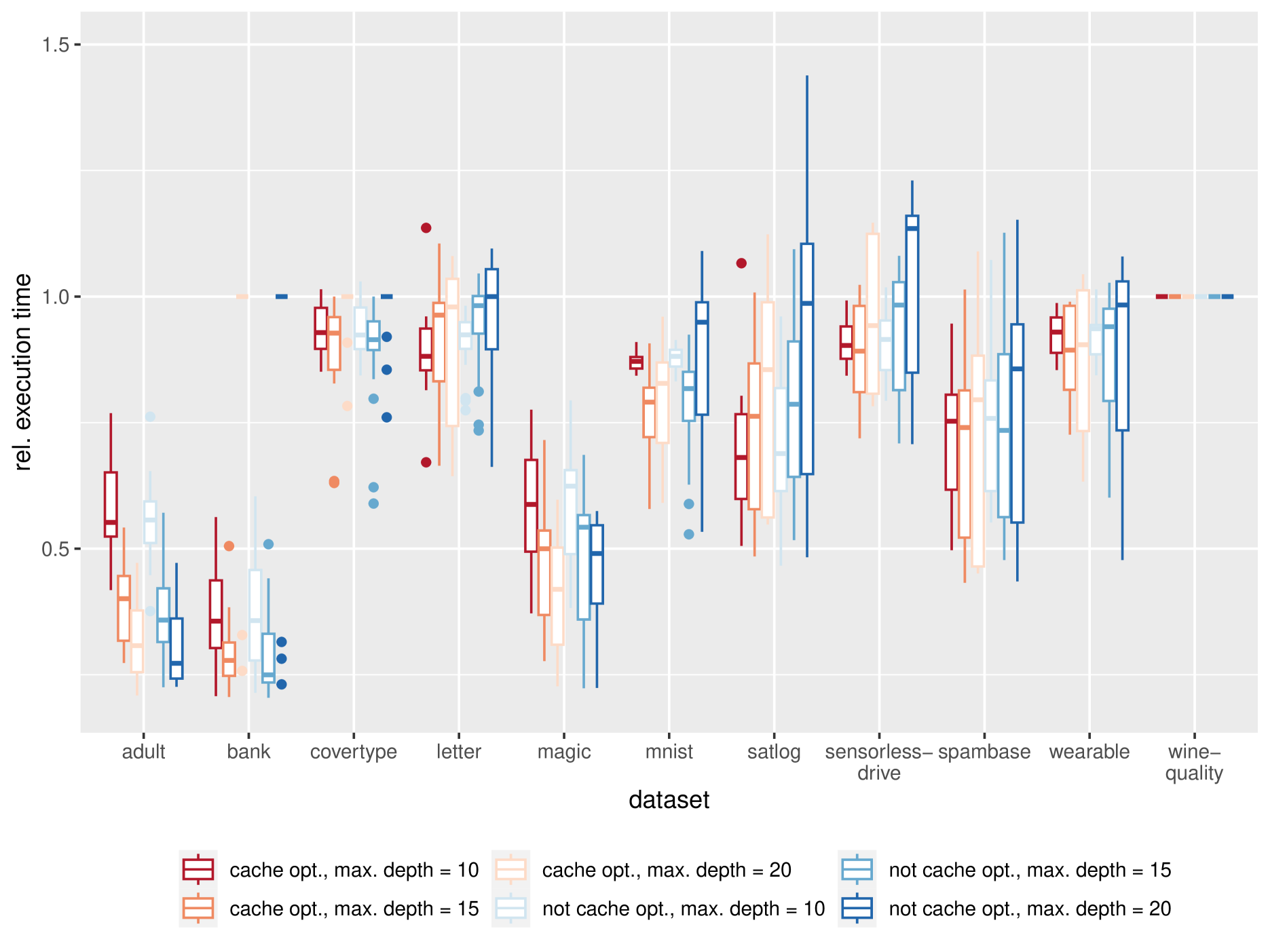
TREE: Tree Regularization for Efficient Execution
Lena Schmid, Daniel Biebert, Christian Hakert, Kuan-Hsun Chen, Michel Lang, Markus Pauly, Jian-Jia Chen
0
0
The rise of machine learning methods on heavily resource constrained devices requires not only the choice of a suitable model architecture for the target platform, but also the optimization of the chosen model with regard to execution time consumption for inference in order to optimally utilize the available resources. Random forests and decision trees are shown to be a suitable model for such a scenario, since they are not only heavily tunable towards the total model size, but also offer a high potential for optimizing their executions according to the underlying memory architecture. In addition to the straightforward strategy of enforcing shorter paths through decision trees and hence reducing the execution time for inference, hardware-aware implementations can optimize the execution time in an orthogonal manner. One particular hardware-aware optimization is to layout the memory of decision trees in such a way, that higher probably paths are less likely to be evicted from system caches. This works particularly well when splits within tree nodes are uneven and have a high probability to visit one of the child nodes. In this paper, we present a method to reduce path lengths by rewarding uneven probability distributions during the training of decision trees at the cost of a minimal accuracy degradation. Specifically, we regularize the impurity computation of the CART algorithm in order to favor not only low impurity, but also highly asymmetric distributions for the evaluation of split criteria and hence offer a high optimization potential for a memory architecture-aware implementation. We show that especially for binary classification data sets and data sets with many samples, this form of regularization can lead to an reduction of up to approximately four times in the execution time with a minimal accuracy degradation.
6/19/2024