Perseus: Reducing Energy Bloat in Large Model Training

1

Sign in to get full access
Overview
- Concise bullet points summarizing the key ideas:
- The paper introduces Perseus, a technique to reduce energy consumption during large language model training.
- Perseus aims to remove "energy bloat" - the excessive energy usage that can occur in large model training.
- The technique involves modifying the model's architecture and training process to be more energy-efficient.
- Experiments show Perseus can significantly reduce energy consumption without compromising model performance.
Plain English Explanation
The paper discusses a new method called Perseus that helps make the training of large AI language models more energy-efficient. Large models, like those used for tasks such as natural language processing, can be very computationally intensive and consume a lot of energy during the training process.
This "energy bloat" can be problematic, both in terms of the environmental impact and the cost of running these models. Perseus aims to address this by modifying the model architecture and training process to be more energy-efficient, without sacrificing the model's performance.
The key ideas involve things like selectively pruning parts of the model, adjusting the training hyperparameters, and using more efficient hardware. Through experiments, the researchers show that Perseus can significantly reduce energy consumption - sometimes by more than 50% - while still maintaining the model's accuracy and capabilities.
This work is important because as AI systems continue to grow in scale and complexity, managing their energy usage will be crucial, both from an environmental standpoint and in terms of the practical costs of deploying and running these models. Techniques like Perseus could help make large AI models more sustainable and accessible.
Technical Explanation
The paper introduces a technique called Perseus that aims to reduce the energy consumption of training large language models without compromising their performance.
The key components of Perseus include:
-
Selective Pruning: The researchers identify parts of the model architecture that can be pruned or simplified without significant impact on the model's capabilities. This helps reduce the overall computational workload.
-
Training Hyperparameter Tuning: The training process is optimized by adjusting hyperparameters like learning rate, batch size, and gradient clipping. This can help improve energy efficiency.
-
Hardware-Aware Optimization: The researchers consider the energy characteristics of different hardware platforms and adapt the model and training process accordingly. For example, leveraging hardware features like reduced precision or specialized accelerators.
Through extensive experiments, the authors demonstrate that Perseus can achieve significant reductions in energy consumption, often more than 50%, while maintaining the model's performance on a variety of benchmark tasks.
Critical Analysis
The paper provides a thorough and well-designed study of techniques to improve the energy efficiency of large language model training. A key strength is the focus on practical, implementable methods that can be readily applied to production systems.
However, the paper does not delve deeply into the underlying reasons why the proposed techniques are effective. A more detailed analysis of the energy profiles and bottlenecks in large model training could provide additional insights.
Additionally, the paper only evaluates the techniques on a limited set of model architectures and tasks. Further research is needed to understand how Perseus would generalize to a broader range of models and applications.
Finally, the paper does not address potential ethical or societal implications of making large AI models more energy-efficient and accessible. As these systems become more widely deployed, it will be important to consider the broader impacts, both positive and negative.
Conclusion
The Perseus technique introduced in this paper represents an important step towards making large language model training more energy-efficient and sustainable. By reducing the "energy bloat" associated with these models, the authors have demonstrated a practical approach to improving their environmental and economic viability.
As AI systems continue to grow in scale and complexity, managing their energy footprint will be crucial. Techniques like Perseus could help make large AI models more accessible and deployable, with positive implications for a wide range of applications and industries.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
1
Perseus: Reducing Energy Bloat in Large Model Training
Jae-Won Chung, Yile Gu, Insu Jang, Luoxi Meng, Nikhil Bansal, Mosharaf Chowdhury
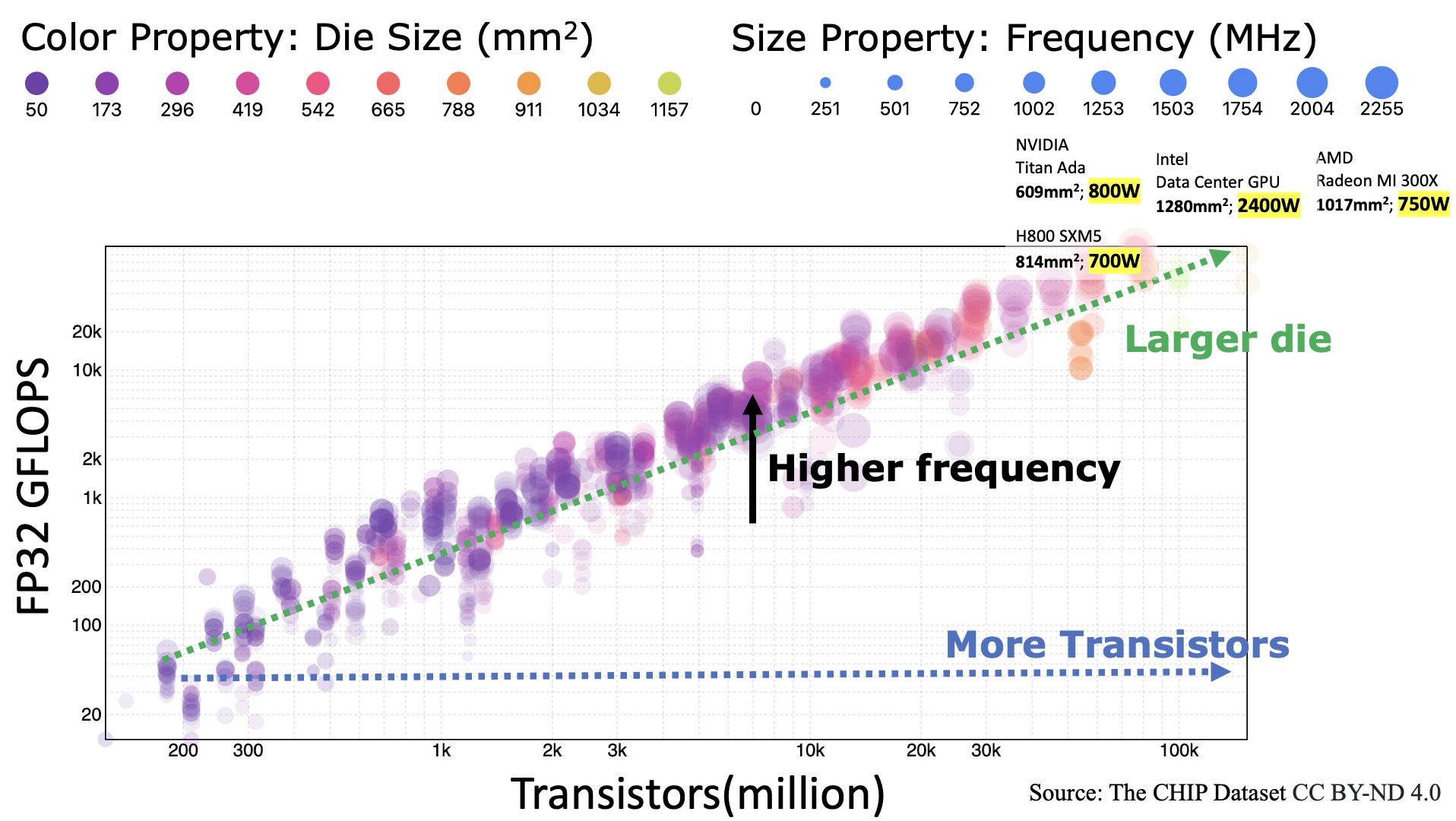
Training large AI models on numerous GPUs consumes a massive amount of energy, making power delivery one of the largest limiting factors in building and operating datacenters for AI workloads. However, we observe that not all energy consumed during training directly contributes to end-to-end throughput, and a significant portion can be removed without slowing down training, which we call energy bloat. In this work, we identify two independent sources of energy bloat in large model training and propose Perseus, a training system that mitigates both. To do this, Perseus obtains the iteration time-energy Pareto frontier of any large model training job using an efficient graph cut-based algorithm and schedules the energy consumption of computations across time to remove both types of energy bloat. Evaluation on large models including GPT-3 and Bloom shows that Perseus reduces the energy consumption of large model training by up to 30% without any throughput loss or hardware modification, enabling energy reduction -- and therefore cost savings -- otherwise unattainable before.
Read more8/15/2024
🧠
0
Toward Cross-Layer Energy Optimizations in Machine Learning Systems
Jae-Won Chung, Nishil Talati, Mosharaf Chowdhury
The AI for Science, Energy, and Security report from DOE outlines a significant focus on developing and optimizing artificial intelligence workflows for a foundational impact on a broad range of DOE missions. With the pervasive usage of artificial intelligence (AI) and machine learning (ML) tools and techniques, their energy efficiency is likely to become the gating factor toward adoption. This is because generative AI (GenAI) models are massive energy hogs: for instance, training a 200-billion parameter large language model (LLM) at Amazon is estimated to have taken 11.9 GWh, which is enough to power more than a thousand average U.S. households for a year. Inference consumes even more energy, because a model trained once serve millions. Given this scale, high energy efficiency is key to addressing the power delivery problem of constructing and operating new supercomputers and datacenters specialized for AI workloads. In that regard, we outline software- and architecture-level research challenges and opportunities, setting the stage for creating cross-layer energy optimizations in AI systems.
Read more8/7/2024

0
The Power of Training: How Different Neural Network Setups Influence the Energy Demand
Daniel Gei{ss}ler, Bo Zhou, Mengxi Liu, Sungho Suh, Paul Lukowicz
This work offers a heuristic evaluation of the effects of variations in machine learning training regimes and learning paradigms on the energy consumption of computing, especially HPC hardware with a life-cycle aware perspective. While increasing data availability and innovation in high-performance hardware fuels the training of sophisticated models, it also fosters the fading perception of energy consumption and carbon emission. Therefore, the goal of this work is to raise awareness about the energy impact of general training parameters and processes, from learning rate over batch size to knowledge transfer. Multiple setups with different hyperparameter configurations are evaluated on three different hardware systems. Among many results, we have found out that even with the same model and hardware to reach the same accuracy, improperly set training hyperparameters consume up to 5 times the energy of the optimal setup. We also extensively examined the energy-saving benefits of learning paradigms including recycling knowledge through pretraining and sharing knowledge through multitask training.
Read more5/9/2024
0
Beyond Efficiency: Scaling AI Sustainably
Carole-Jean Wu, Bilge Acun, Ramya Raghavendra, Kim Hazelwood
Barroso's seminal contributions in energy-proportional warehouse-scale computing launched an era where modern datacenters have become more energy efficient and cost effective than ever before. At the same time, modern AI applications have driven ever-increasing demands in computing, highlighting the importance of optimizing efficiency across the entire deep learning model development cycle. This paper characterizes the carbon impact of AI, including both operational carbon emissions from training and inference as well as embodied carbon emissions from datacenter construction and hardware manufacturing. We highlight key efficiency optimization opportunities for cutting-edge AI technologies, from deep learning recommendation models to multi-modal generative AI tasks. To scale AI sustainably, we must also go beyond efficiency and optimize across the life cycle of computing infrastructures, from hardware manufacturing to datacenter operations and end-of-life processing for the hardware.
Read more6/26/2024