Perturbed examples reveal invariances shared by language models

0
💬
Sign in to get full access
Overview
- The paper introduces a novel framework to compare the linguistic capabilities of natural language processing (NLP) models by examining their invariance to interpretable input perturbations.
- This framework offers insights into how changes in models (e.g., distillation, size increase) affect their linguistic capabilities, and enables evaluation of invariances between commercial black-box models and better-understood models.
- The authors observe that large language models share many invariances encoded by models of various sizes, whereas the invariances of large models are only shared by other large models.
- Possessing a wide variety of invariances may be key to the recent successes of large language models, and this framework can shed light on the types of invariances retained or emerging in new models.
Plain English Explanation
As the field of natural language processing (NLP) has rapidly advanced, researchers have developed many new models that are quickly outpacing our understanding of how they compare to established models. This is partly due to saturating benchmarks, which may not accurately reflect a model's performance in real-world situations.
To address this challenge, the researchers in this paper have created a novel framework that allows them to compare the linguistic capabilities of different NLP models. The key idea is to look at how the models respond to small, interpretable changes (or "perturbations") to the input text. By analyzing the models' "invariance" - or lack thereof - to these perturbations, the researchers can gain insights into the specific language skills each model has learned.
For example, if two models show the same invariance to a perturbation that tests their understanding of negation, then the researchers can conclude that those models have similar capabilities when it comes to negation. This approach allows the researchers to "peek under the hood" of the models and understand their linguistic strengths and weaknesses, even for commercial black-box models that are not fully transparent.
Interestingly, the researchers found that large language models tend to share many of the same linguistic invariances, even when compared to smaller models. However, the invariances unique to the largest models are only shared by other large models. This suggests that possessing a wide variety of linguistic invariances may be a key factor in the impressive performance of today's large language models.
By making their framework publicly available, the researchers hope to enable others to better understand the linguistic capabilities of different NLP models, which could lead to more informed model selection and development.
Technical Explanation
The paper introduces a novel framework, called RUPBench, to compare the linguistic capabilities of natural language processing (NLP) models. The key idea is to analyze the models' "invariance" to interpretable input perturbations that target specific linguistic phenomena, such as negation, modality, or tense.
The authors conduct experiments on models from both the same and different architecture families (e.g., GPT-2 and InstructGPT). By examining the shared and unique invariances between these models, the framework provides insights into how changes in model architecture, size, or training (e.g., distillation) affect their linguistic capabilities.
For example, the authors find that large language models share many invariances encoded by models of various sizes, suggesting that possessing a wide variety of linguistic skills may be a key factor in the recent success of large models. However, the invariances unique to the largest models are only shared by other large models, highlighting the potential for new linguistic capabilities to emerge as models scale up.
The framework also enables the evaluation of invariances between commercial black-box models (e.g., InstructGPT) and models that are better understood (e.g., GPT-2), providing insights into the linguistic capabilities of these opaque models.
Overall, the RUPBench framework offers a novel approach to benchmarking and understanding the linguistic capabilities of NLP models, which could lead to more informed model selection and development.
Critical Analysis
The paper presents a valuable and novel framework for comparing the linguistic capabilities of NLP models. By focusing on model invariance to interpretable input perturbations, the researchers have developed a unique approach that complements traditional benchmarking methods, which may not fully capture differences in model performance in real-world scenarios.
One potential limitation of the framework is that it relies on a pre-defined set of linguistic perturbations, which may not capture the full breadth of language skills that are important in different applications. The authors acknowledge this and suggest that the framework could be extended to include a wider range of perturbations in the future.
Additionally, while the experiments provide interesting insights into the linguistic capabilities of large language models, the paper does not delve deeply into the potential reasons behind the observed patterns of shared and unique invariances. Further research could explore the underlying architectural or training factors that contribute to these phenomena.
It's also worth noting that the evaluation of commercial black-box models, while valuable, is inherently limited by the lack of transparency into the models' internals. The authors recognize this and suggest that their framework could be particularly useful for understanding the linguistic capabilities of such opaque models.
Overall, the RUPBench framework represents a significant contribution to the field of NLP, offering a novel approach to benchmarking and comparing models that could lead to more informed model selection and development. As the authors make the code publicly available, it will be interesting to see how the framework is adopted and extended by the broader research community.
Conclusion
This paper introduces a novel framework, called RUPBench, that allows researchers to compare the linguistic capabilities of natural language processing (NLP) models by examining their invariance to interpretable input perturbations. The key insights from this work include:
- Large language models share many linguistic invariances with models of various sizes, suggesting that possessing a wide variety of linguistic skills may be a key factor in their recent success.
- However, the invariances unique to the largest models are only shared by other large models, highlighting the potential for new linguistic capabilities to emerge as models scale up.
- The framework enables the evaluation of linguistic capabilities in commercial black-box models, providing valuable insights into their inner workings.
By making the RUPBench framework publicly available, the researchers hope to enable the broader NLP community to better understand and compare the linguistic capabilities of different models, ultimately leading to more informed model selection and development. This work represents an important step forward in the ongoing effort to understand the strengths and limitations of large language models and advance the field of natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Perturbed examples reveal invariances shared by language models
Ruchit Rawal, Mariya Toneva
The rapid growth in natural language processing (NLP) research has led to numerous new models, outpacing our understanding of how they compare to established ones. One major reason for this difficulty is saturating benchmarks, which may not well reflect differences in model performance in the wild. In this work, we introduce a novel framework to compare two NLP models by revealing their shared invariance to interpretable input perturbations targeting a specific linguistic capability. Via experiments on models from the same and different architecture families, this framework offers insights about how changes in models (e.g., distillation, size increase) affect linguistic capabilities. Furthermore, our framework enables evaluation of invariances between commercial black-box models (e.g., InstructGPT family) and models that are better understood (e.g., GPT-2). Across experiments, we observe that large language models share many invariances encoded by models of various sizes, whereas the invariances by large models are only shared by other large models. Possessing a wide variety of invariances may be key to the recent successes of large language models, and our framework can shed light on the types of invariances retained or emerging in new models. We make the code publicly available.
Read more6/18/2024
💬
0
Evaluating Concurrent Robustness of Language Models Across Diverse Challenge Sets
Vatsal Gupta, Pranshu Pandya, Tushar Kataria, Vivek Gupta, Dan Roth
Language models, characterized by their black-box nature, often hallucinate and display sensitivity to input perturbations, causing concerns about trust. To enhance trust, it is imperative to gain a comprehensive understanding of the model's failure modes and develop effective strategies to improve their performance. In this study, we introduce a methodology designed to examine how input perturbations affect language models across various scales, including pre-trained models and large language models (LLMs). Utilizing fine-tuning, we enhance the model's robustness to input perturbations. Additionally, we investigate whether exposure to one perturbation enhances or diminishes the model's performance with respect to other perturbations. To address robustness against multiple perturbations, we present three distinct fine-tuning strategies. Furthermore, we broaden the scope of our methodology to encompass large language models (LLMs) by leveraging a chain of thought (CoT) prompting approach augmented with exemplars. We employ the Tabular-NLI task to showcase how our proposed strategies adeptly train a robust model, enabling it to address diverse perturbations while maintaining accuracy on the original dataset.
Read more7/17/2024

0
RUPBench: Benchmarking Reasoning Under Perturbations for Robustness Evaluation in Large Language Models
Yuqing Wang, Yun Zhao
With the increasing use of large language models (LLMs), ensuring reliable performance in diverse, real-world environments is essential. Despite their remarkable achievements, LLMs often struggle with adversarial inputs, significantly impacting their effectiveness in practical applications. To systematically understand the robustness of LLMs, we present RUPBench, a comprehensive benchmark designed to evaluate LLM robustness across diverse reasoning tasks. Our benchmark incorporates 15 reasoning datasets, categorized into commonsense, arithmetic, logical, and knowledge-intensive reasoning, and introduces nine types of textual perturbations at lexical, syntactic, and semantic levels. By examining the performance of state-of-the-art LLMs such as GPT-4o, Llama3, Phi-3, and Gemma on both original and perturbed datasets, we provide a detailed analysis of their robustness and error patterns. Our findings highlight that larger models tend to exhibit greater robustness to perturbations. Additionally, common error types are identified through manual inspection, revealing specific challenges faced by LLMs in different reasoning contexts. This work provides insights into areas where LLMs need further improvement to handle diverse and noisy inputs effectively.
Read more6/18/2024
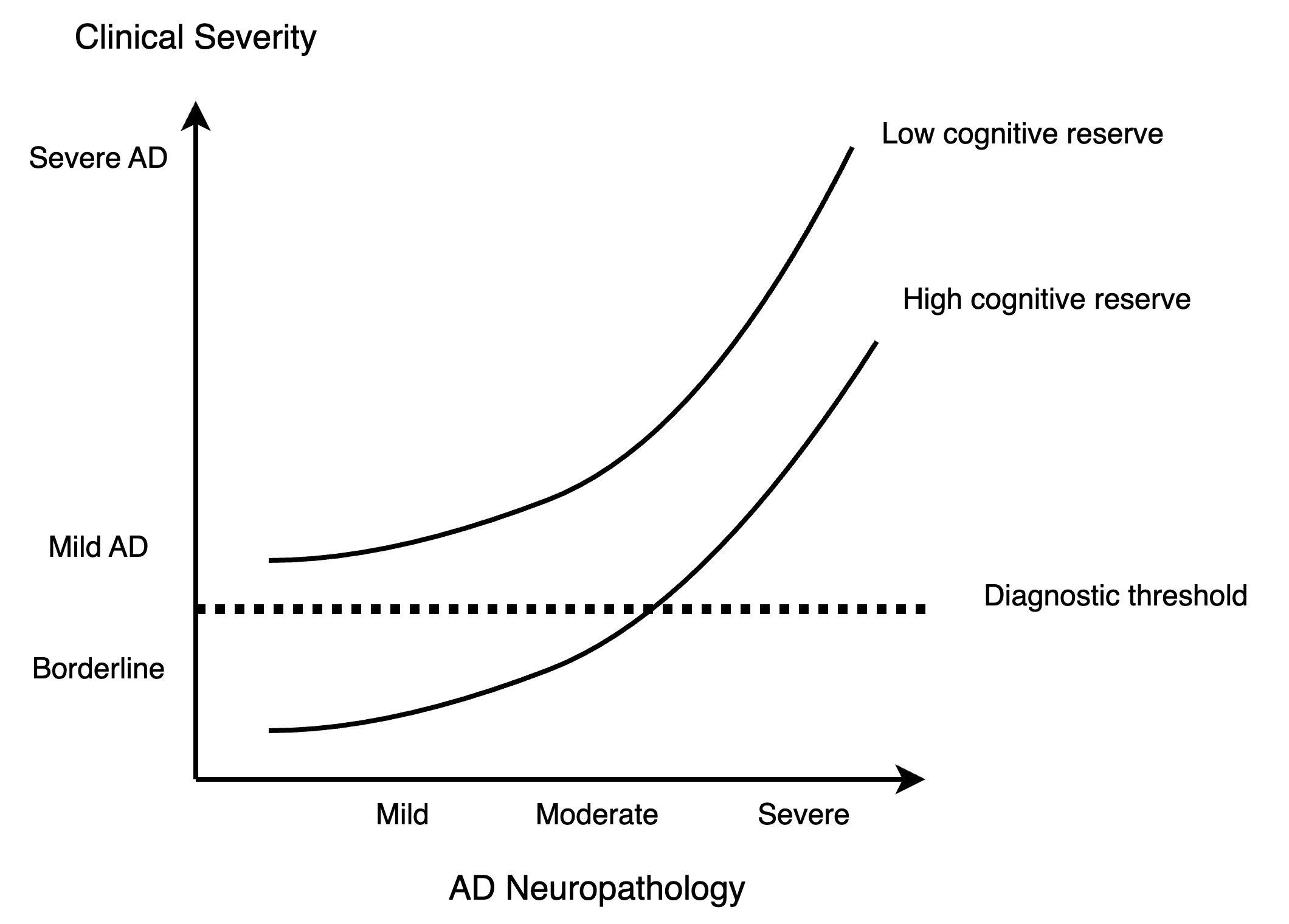
0
Too Big to Fail: Larger Language Models are Disproportionately Resilient to Induction of Dementia-Related Linguistic Anomalies
Changye Li, Zhecheng Sheng, Trevor Cohen, Serguei Pakhomov
As artificial neural networks grow in complexity, understanding their inner workings becomes increasingly challenging, which is particularly important in healthcare applications. The intrinsic evaluation metrics of autoregressive neural language models (NLMs), perplexity (PPL), can reflect how surprised an NLM model is at novel input. PPL has been widely used to understand the behavior of NLMs. Previous findings show that changes in PPL when masking attention layers in pre-trained transformer-based NLMs reflect linguistic anomalies associated with Alzheimer's disease dementia. Building upon this, we explore a novel bidirectional attention head ablation method that exhibits properties attributed to the concepts of cognitive and brain reserve in human brain studies, which postulate that people with more neurons in the brain and more efficient processing are more resilient to neurodegeneration. Our results show that larger GPT-2 models require a disproportionately larger share of attention heads to be masked/ablated to display degradation of similar magnitude to masking in smaller models. These results suggest that the attention mechanism in transformer models may present an analogue to the notions of cognitive and brain reserve and could potentially be used to model certain aspects of the progression of neurodegenerative disorders and aging.
Read more6/6/2024