Too Big to Fail: Larger Language Models are Disproportionately Resilient to Induction of Dementia-Related Linguistic Anomalies

0
Sign in to get full access
Overview
- This paper investigates how the size of language models affects their resilience to linguistic anomalies associated with dementia.
- The researchers found that larger language models were more resistant to the induction of these dementia-related linguistic changes compared to smaller models.
- This suggests that as language models grow in scale, they may become disproportionately robust to certain types of cognitive impairment.
Plain English Explanation
The paper examines how the size of language models, which are AI systems trained on vast amounts of text data, impacts their ability to handle linguistic patterns associated with dementia. Dementia is a general term for cognitive decline that can affect a person's language and communication.
The researchers discovered that larger language models, those with more parameters and training data, were significantly more resilient to the introduction of these dementia-related linguistic anomalies compared to smaller models. This means the larger models were better able to maintain coherent and grammatically correct language output even when exposed to the types of linguistic patterns seen in dementia patients.
This finding suggests that as language models continue to grow in scale, they may become disproportionately resistant to certain types of cognitive impairment. In other words, the biggest language models may be the "too big to fail" when it comes to handling language challenges associated with conditions like dementia.
Technical Explanation
The researchers used a technique called "induction" to deliberately introduce linguistic anomalies characteristic of dementia into the text inputs of language models. This allowed them to assess how well different sized models could maintain coherent and grammatically correct language generation in the face of these dementia-like distortions.
They tested language models ranging from small (< 100M parameters) to very large (> 100B parameters), including popular models like GPT-2 and GPT-3. The results showed that larger models were significantly more robust to these dementia-related linguistic anomalies compared to their smaller counterparts.
The researchers hypothesize that the increased parameter count and training data of larger models allows them to build more comprehensive and resilient representations of language, which in turn enables them to better handle the types of linguistic irregularities associated with cognitive decline.
Critical Analysis
The paper provides a valuable contribution by highlighting an important capability of large language models that has not been extensively studied - their disproportionate resilience to certain types of cognitive impairment. This has implications for the potential use of these models in assistive technologies or applications targeting populations affected by dementia.
However, the researchers acknowledge that this study is limited to a specific set of linguistic anomalies induced in a controlled experiment. More research is needed to understand how language models would perform in real-world interactions with individuals experiencing the full range of cognitive and communicative challenges associated with dementia.
Additionally, the paper does not explore potential ethical concerns around the use of large language models in sensitive healthcare applications without proper safeguards and oversight. As these models become more capable, it will be crucial to consider the implications and develop appropriate guidelines and policies.
Conclusion
This paper demonstrates that as language models grow in scale, they exhibit a disproportionate resilience to the induction of linguistic anomalies associated with dementia. This finding suggests that the largest language models may be particularly well-suited for applications targeting populations affected by cognitive decline, though more research is needed to fully understand the real-world implications.
As language AI continues to advance, it will be important to carefully consider the ethical and societal impacts of deploying these powerful technologies, especially in sensitive domains like healthcare. Ongoing collaboration between researchers, policymakers, and domain experts will be crucial to ensuring these systems are developed and deployed responsibly and equitably.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Too Big to Fail: Larger Language Models are Disproportionately Resilient to Induction of Dementia-Related Linguistic Anomalies
Changye Li, Zhecheng Sheng, Trevor Cohen, Serguei Pakhomov
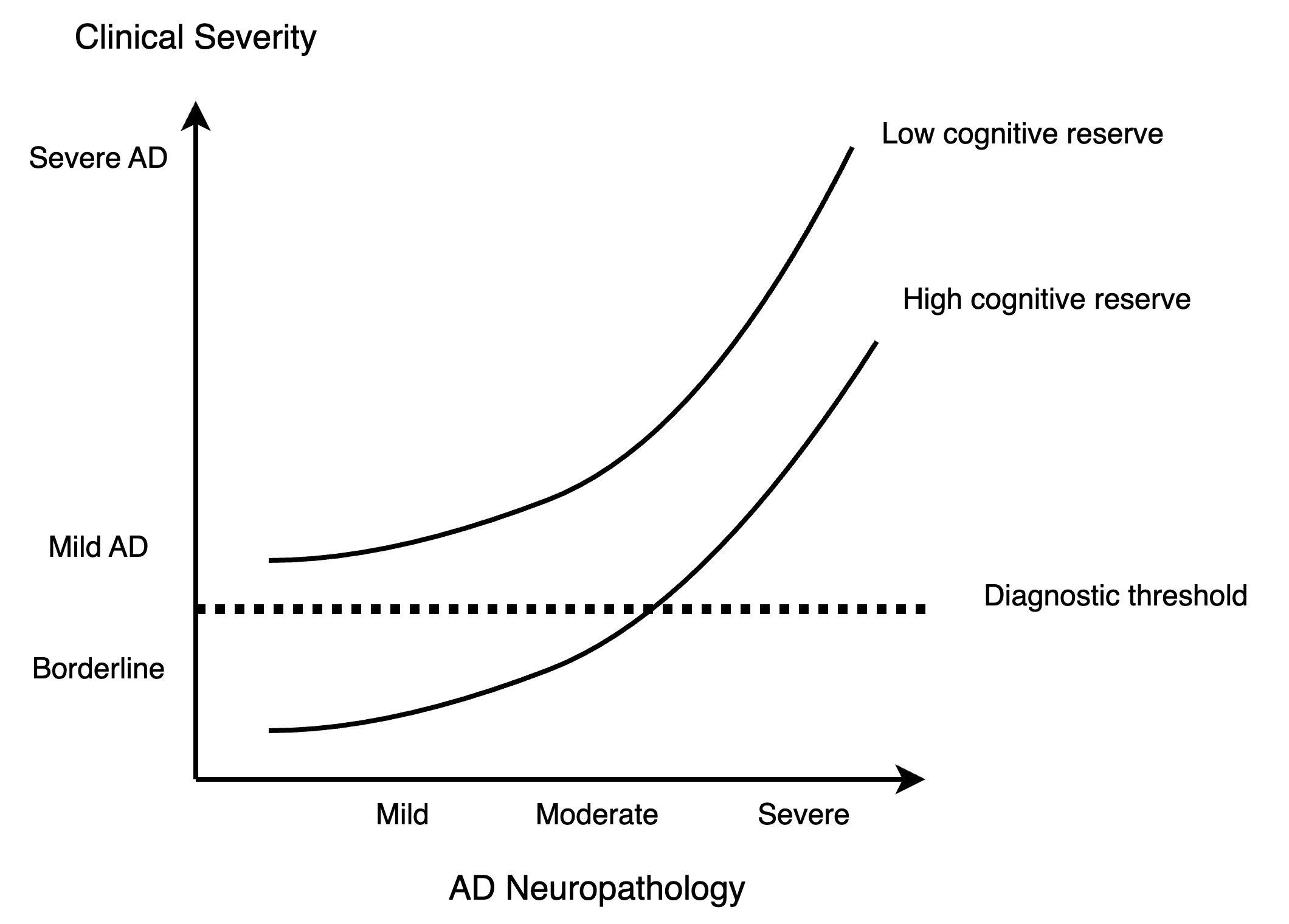
As artificial neural networks grow in complexity, understanding their inner workings becomes increasingly challenging, which is particularly important in healthcare applications. The intrinsic evaluation metrics of autoregressive neural language models (NLMs), perplexity (PPL), can reflect how surprised an NLM model is at novel input. PPL has been widely used to understand the behavior of NLMs. Previous findings show that changes in PPL when masking attention layers in pre-trained transformer-based NLMs reflect linguistic anomalies associated with Alzheimer's disease dementia. Building upon this, we explore a novel bidirectional attention head ablation method that exhibits properties attributed to the concepts of cognitive and brain reserve in human brain studies, which postulate that people with more neurons in the brain and more efficient processing are more resilient to neurodegeneration. Our results show that larger GPT-2 models require a disproportionately larger share of attention heads to be masked/ablated to display degradation of similar magnitude to masking in smaller models. These results suggest that the attention mechanism in transformer models may present an analogue to the notions of cognitive and brain reserve and could potentially be used to model certain aspects of the progression of neurodegenerative disorders and aging.
Read more6/6/2024
1
Large language models surpass human experts in predicting neuroscience results
Xiaoliang Luo, Akilles Rechardt, Guangzhi Sun, Kevin K. Nejad, Felipe Y'a~nez, Bati Yilmaz, Kangjoo Lee, Alexandra O. Cohen, Valentina Borghesani, Anton Pashkov, Daniele Marinazzo, Jonathan Nicholas, Alessandro Salatiello, Ilia Sucholutsky, Pasquale Minervini, Sepehr Razavi, Roberta Rocca, Elkhan Yusifov, Tereza Okalova, Nianlong Gu, Martin Ferianc, Mikail Khona, Kaustubh R. Patil, Pui-Shee Lee, Rui Mata, Nicholas E. Myers, Jennifer K Bizley, Sebastian Musslick, Isil Poyraz Bilgin, Guiomar Niso, Justin M. Ales, Michael Gaebler, N Apurva Ratan Murty, Leyla Loued-Khenissi, Anna Behler, Chloe M. Hall, Jessica Dafflon, Sherry Dongqi Bao, Bradley C. Love
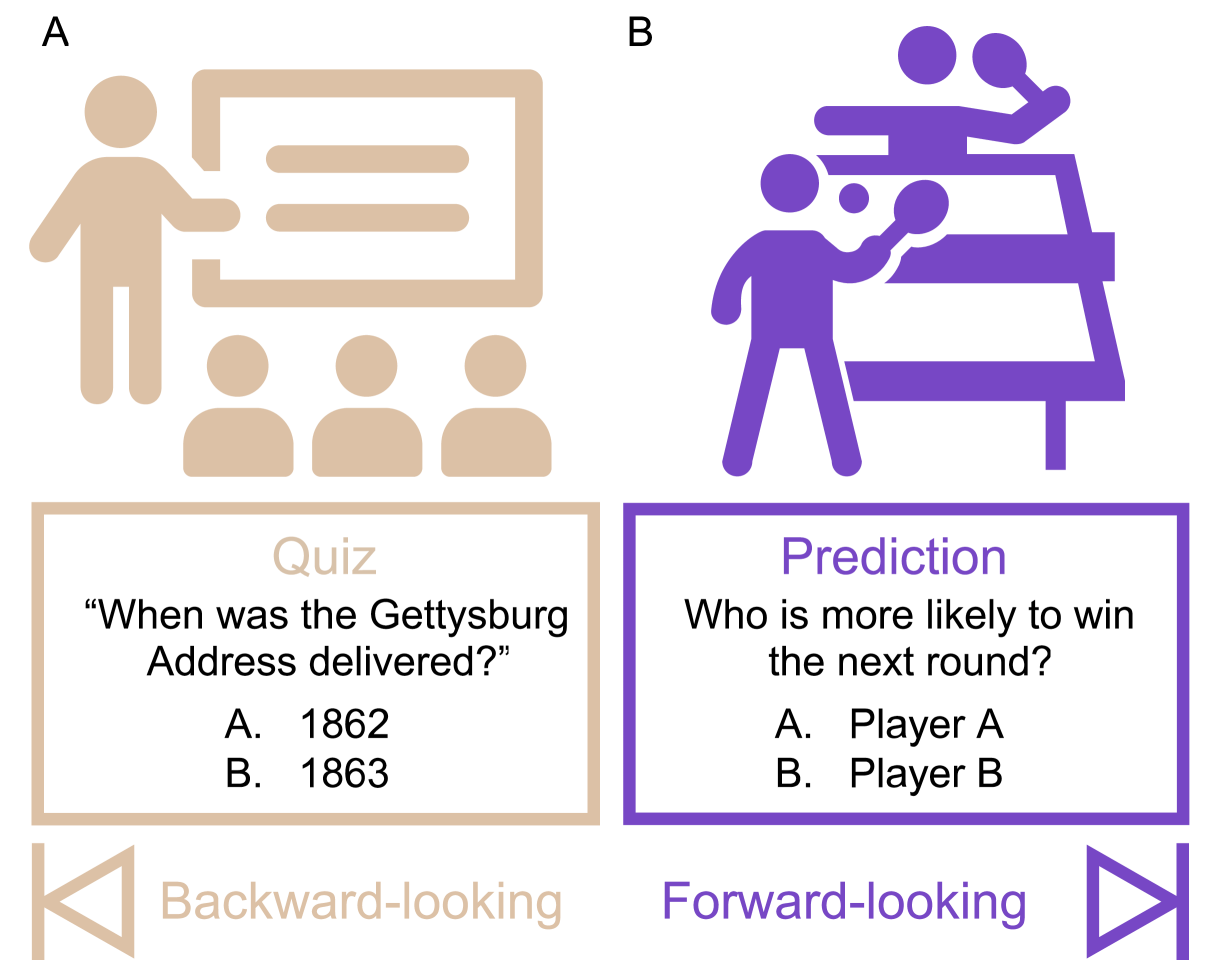
Scientific discoveries often hinge on synthesizing decades of research, a task that potentially outstrips human information processing capacities. Large language models (LLMs) offer a solution. LLMs trained on the vast scientific literature could potentially integrate noisy yet interrelated findings to forecast novel results better than human experts. To evaluate this possibility, we created BrainBench, a forward-looking benchmark for predicting neuroscience results. We find that LLMs surpass experts in predicting experimental outcomes. BrainGPT, an LLM we tuned on the neuroscience literature, performed better yet. Like human experts, when LLMs were confident in their predictions, they were more likely to be correct, which presages a future where humans and LLMs team together to make discoveries. Our approach is not neuroscience-specific and is transferable to other knowledge-intensive endeavors.
Read more6/24/2024
0
Brain-Like Language Processing via a Shallow Untrained Multihead Attention Network
Badr AlKhamissi, Greta Tuckute, Antoine Bosselut, Martin Schrimpf
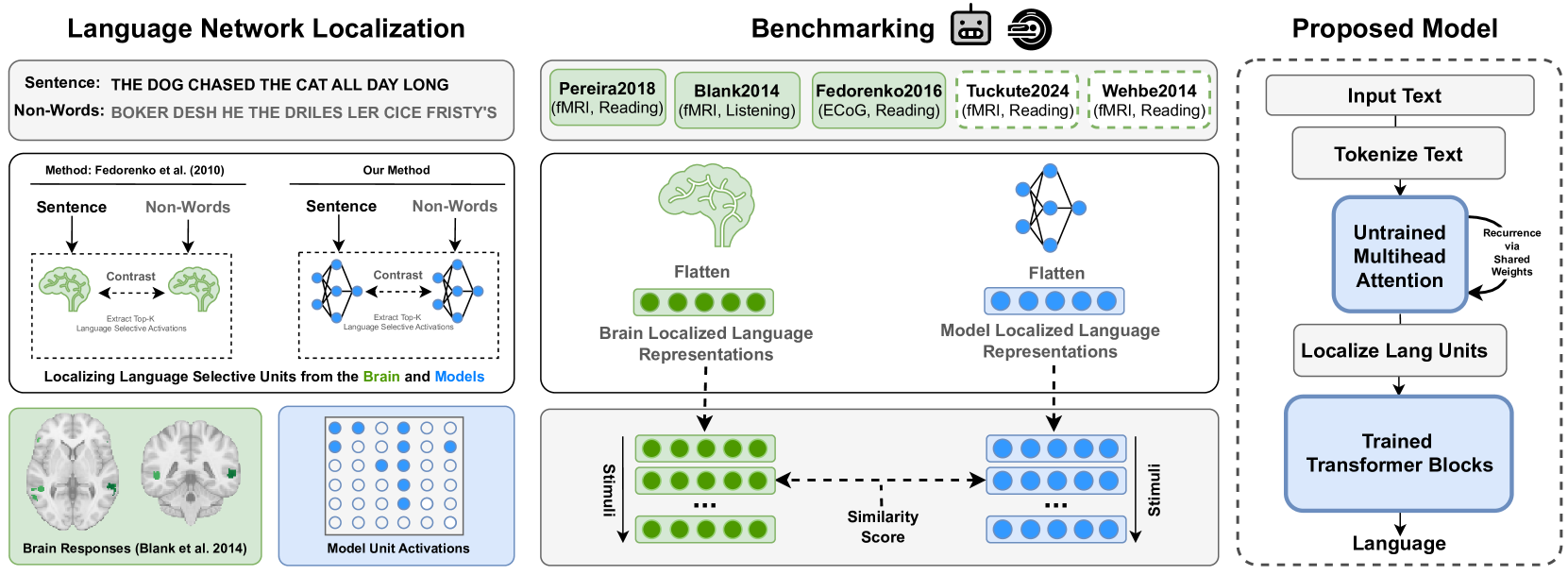
Large Language Models (LLMs) have been shown to be effective models of the human language system, with some models predicting most explainable variance of brain activity in current datasets. Even in untrained models, the representations induced by architectural priors can exhibit reasonable alignment to brain data. In this work, we investigate the key architectural components driving the surprising alignment of untrained models. To estimate LLM-to-brain similarity, we first select language-selective units within an LLM, similar to how neuroscientists identify the language network in the human brain. We then benchmark the brain alignment of these LLM units across five different brain recording datasets. By isolating critical components of the Transformer architecture, we identify tokenization strategy and multihead attention as the two major components driving brain alignment. A simple form of recurrence further improves alignment. We further demonstrate this quantitative brain alignment of our model by reproducing landmark studies in the language neuroscience field, showing that localized model units -- just like language voxels measured empirically in the human brain -- discriminate more reliably between lexical than syntactic differences, and exhibit similar response profiles under the same experimental conditions. Finally, we demonstrate the utility of our model's representations for language modeling, achieving improved sample and parameter efficiency over comparable architectures. Our model's estimates of surprisal sets a new state-of-the-art in the behavioral alignment to human reading times. Taken together, we propose a highly brain- and behaviorally-aligned model that conceptualizes the human language system as an untrained shallow feature encoder, with structural priors, combined with a trained decoder to achieve efficient and performant language processing.
Read more6/24/2024
0
Matching domain experts by training from scratch on domain knowledge
Xiaoliang Luo, Guangzhi Sun, Bradley C. Love
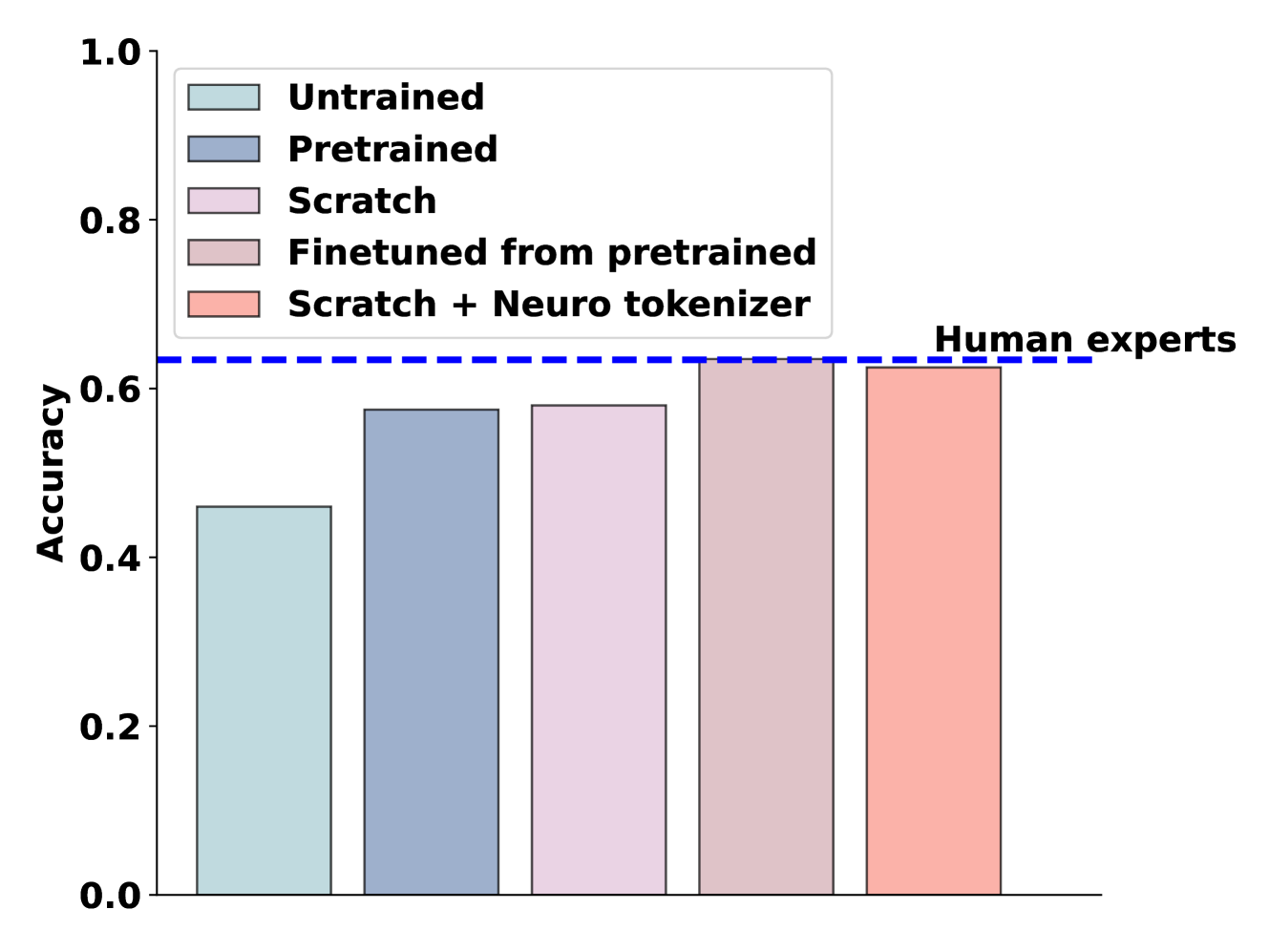
Recently, large language models (LLMs) have outperformed human experts in predicting the results of neuroscience experiments (Luo et al., 2024). What is the basis for this performance? One possibility is that statistical patterns in that specific scientific literature, as opposed to emergent reasoning abilities arising from broader training, underlie LLMs' performance. To evaluate this possibility, we trained (next word prediction) a relatively small 124M-parameter GPT-2 model on 1.3 billion tokens of domain-specific knowledge. Despite being orders of magnitude smaller than larger LLMs trained on trillions of tokens, small models achieved expert-level performance in predicting neuroscience results. Small models trained on the neuroscience literature succeeded when they were trained from scratch using a tokenizer specifically trained on neuroscience text or when the neuroscience literature was used to finetune a pretrained GPT-2. Our results indicate that expert-level performance may be attained by even small LLMs through domain-specific, auto-regressive training approaches.
Read more5/16/2024