InstructionCP: A fast approach to transfer Large Language Models into target language
2405.20175
0
0

Abstract
The rapid development of large language models (LLMs) in recent years has largely focused on English, resulting in models that respond exclusively in English. To adapt these models to other languages, continual pre-training (CP) is often employed, followed by supervised fine-tuning (SFT) to maintain conversational abilities. However, CP and SFT can reduce a model's ability to filter harmful content. We propose Instruction Continual Pre-training (InsCP), which integrates instruction tags into the CP process to prevent loss of conversational proficiency while acquiring new languages. Our experiments demonstrate that InsCP retains conversational and Reinforcement Learning from Human Feedback (RLHF) abilities. Empirical evaluations on language alignment, reliability, and knowledge benchmarks confirm the efficacy of InsCP. Notably, this approach requires only 0.1 billion tokens of high-quality instruction-following data, thereby reducing resource consumption.
Create account to get full access
Overview
- This paper presents a new approach called "InstructionCP" for quickly transferring large language models to target languages.
- The method uses instruction tuning, which aligns the model to follow specific task instructions, to enable fast and effective cross-lingual transfer.
- The authors demonstrate the effectiveness of InstructionCP on a range of tasks, showing it can outperform other cross-lingual transfer techniques.
Plain English Explanation
The paper discusses a new way to adapt large language models, like those used in chatbots and virtual assistants, to work in different languages quickly and effectively. The key idea is to "instruct" the model on how to perform specific tasks, like answering questions or summarizing text, and then use this instruction-following ability to transfer the model to a new language.
This is useful because training large language models from scratch in a new language can be very time-consuming and resource-intensive. InstructionCP provides a faster way to get the model working in the target language by leveraging the knowledge it has already learned. By training the model to follow instructions, it can more easily adapt to the new language and perform well on a variety of tasks.
The researchers show that InstructionCP outperforms other cross-lingual transfer techniques, making it a promising approach for efficiently deploying large language models in low-resource languages. This could help make advanced AI capabilities more accessible to a wider range of users around the world.
Technical Explanation
The paper introduces a new method called "InstructionCP" for rapidly transferring large language models to target languages. The key innovation is the use of instruction tuning, where the model is fine-tuned to follow specific task instructions.
The authors hypothesize that this instruction-following ability can enable effective cross-lingual transfer to new languages. To test this, they evaluate InstructionCP on a range of tasks, including text generation, question answering, and code understanding, across multiple language pairs.
The results show that InstructionCP outperforms other cross-lingual transfer techniques, such as multilingual pretraining and direct fine-tuning. The authors attribute this success to the model's ability to quickly adapt its instruction-following behavior to the target language, leveraging the knowledge it has already acquired.
The paper also introduces a novel synthetic data generation technique to further boost the cross-lingual transfer performance of InstructionCP. This involves creating task-specific training data in the target language to better align the model's instruction-following capabilities.
Critical Analysis
The InstructionCP approach presents a promising direction for enabling efficient cross-lingual transfer of large language models. The authors provide a thorough evaluation, demonstrating the method's effectiveness across a range of tasks and language pairs.
One potential limitation is that the performance of InstructionCP may depend on the quality and coverage of the instruction-following training data. If the instructions do not adequately capture the full range of desired behaviors, the model's adaptation to the target language may be impaired.
Additionally, the paper does not explore the potential negative societal impacts of deploying large language models in low-resource languages. There are concerns around the spread of disinformation, biases, and the disruption of local linguistic and cultural norms that should be carefully considered.
Further research could investigate the robustness of InstructionCP to different types of linguistic and cultural variation, as well as ways to mitigate potential harms. Exploring the translation abilities of large language models could also complement the InstructionCP approach and enable even more effective cross-lingual transfer.
Conclusion
The InstructionCP method presented in this paper offers a novel and efficient approach for transferring large language models to target languages. By leveraging instruction-following abilities, the model can quickly adapt to new languages and perform well on a variety of tasks.
This work has the potential to help make advanced AI capabilities more accessible to a wider range of users globally, but it also raises important considerations around the responsible deployment of such technologies. Continued research and careful implementation will be crucial to ensure the benefits of InstructionCP are realized while mitigating potential negative impacts.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
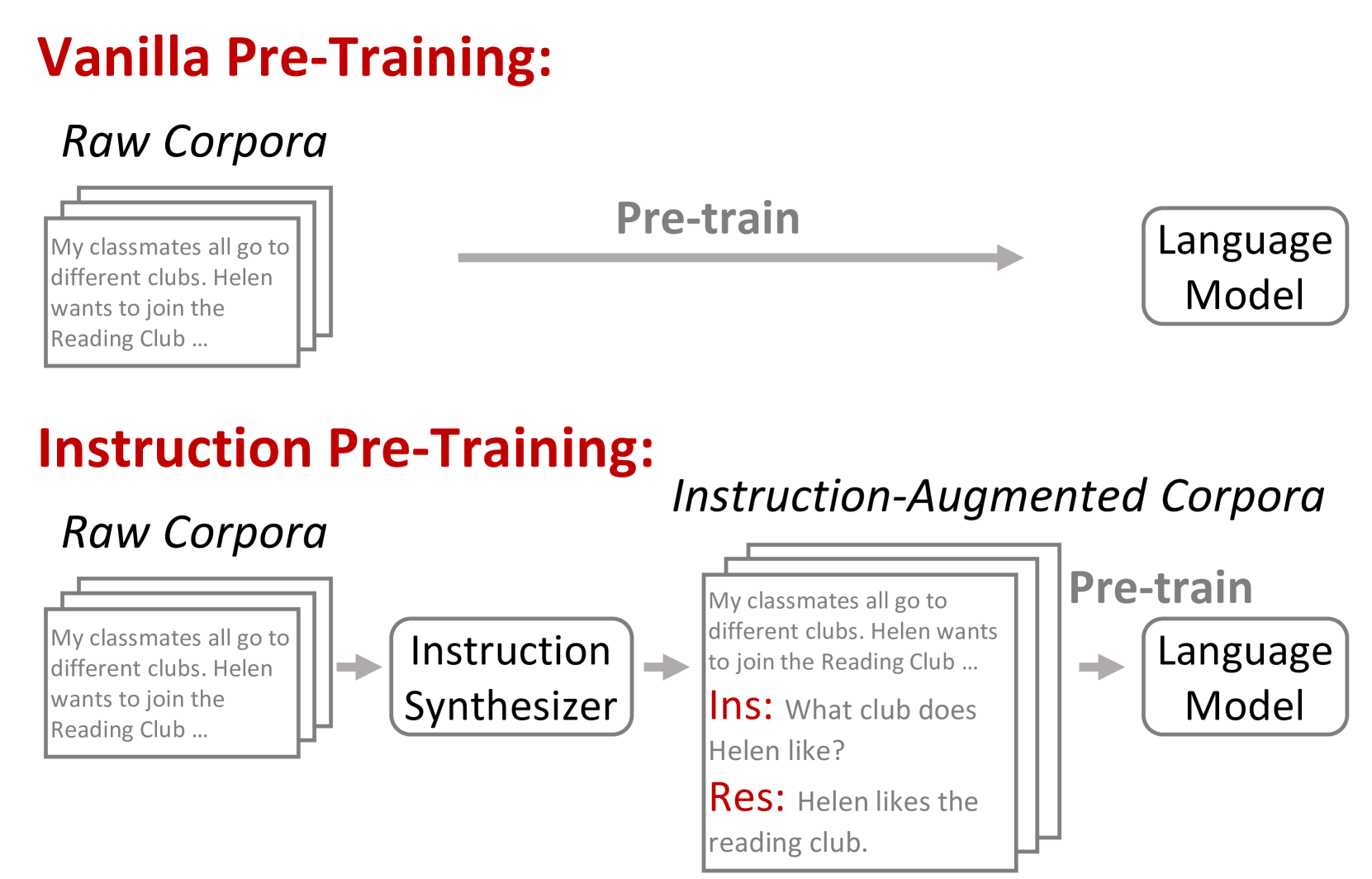
Instruction Pre-Training: Language Models are Supervised Multitask Learners
Daixuan Cheng, Yuxian Gu, Shaohan Huang, Junyu Bi, Minlie Huang, Furu Wei
0
0
Unsupervised multitask pre-training has been the critical method behind the recent success of language models (LMs). However, supervised multitask learning still holds significant promise, as scaling it in the post-training stage trends towards better generalization. In this paper, we explore supervised multitask pre-training by proposing Instruction Pre-Training, a framework that scalably augments massive raw corpora with instruction-response pairs to pre-train LMs. The instruction-response pairs are generated by an efficient instruction synthesizer built on open-source models. In our experiments, we synthesize 200M instruction-response pairs covering 40+ task categories to verify the effectiveness of Instruction Pre-Training. In pre-training from scratch, Instruction Pre-Training not only consistently enhances pre-trained base models but also benefits more from further instruction tuning. In continual pre-training, Instruction Pre-Training enables Llama3-8B to be comparable to or even outperform Llama3-70B. Our model, code, and data are available at https://github.com/microsoft/LMOps.
6/21/2024

Phased Instruction Fine-Tuning for Large Language Models
Wei Pang, Chuan Zhou, Xiao-Hua Zhou, Xiaojie Wang
0
0
Instruction Fine-Tuning enhances pre-trained language models from basic next-word prediction to complex instruction-following. However, existing One-off Instruction Fine-Tuning (One-off IFT) method, applied on a diverse instruction, may not effectively boost models' adherence to instructions due to the simultaneous handling of varying instruction complexities. To improve this, Phased Instruction Fine-Tuning (Phased IFT) is proposed, based on the idea that learning to follow instructions is a gradual process. It assesses instruction difficulty using GPT-4, divides the instruction data into subsets of increasing difficulty, and uptrains the model sequentially on these subsets. Experiments with Llama-2 7B/13B/70B, Llama3 8/70B and Mistral-7B models using Alpaca data show that Phased IFT significantly outperforms One-off IFT, supporting the progressive alignment hypothesis and providing a simple and efficient way to enhance large language models. Codes and datasets from our experiments are freely available at https://github.com/xubuvd/PhasedSFT.
6/18/2024

Contrastive Instruction Tuning
Tianyi Lorena Yan, Fei Wang, James Y. Huang, Wenxuan Zhou, Fan Yin, Aram Galstyan, Wenpeng Yin, Muhao Chen
0
0
Instruction tuning has been used as a promising approach to improve the performance of large language models (LLMs) on unseen tasks. However, current LLMs exhibit limited robustness to unseen instructions, generating inconsistent outputs when the same instruction is phrased with slightly varied forms or language styles. This behavior indicates LLMs' lack of robustness to textual variations and generalizability to unseen instructions, potentially leading to trustworthiness issues. Accordingly, we propose Contrastive Instruction Tuning, which maximizes the similarity between the hidden representations of semantically equivalent instruction-instance pairs while minimizing the similarity between semantically different ones. To facilitate this approach, we augment the existing FLAN collection by paraphrasing task instructions. Experiments on the PromptBench benchmark show that CoIN consistently improves LLMs' robustness to unseen instructions with variations across character, word, sentence, and semantic levels by an average of +2.5% in accuracy. Code is available at https://github.com/luka-group/CoIN.
6/7/2024
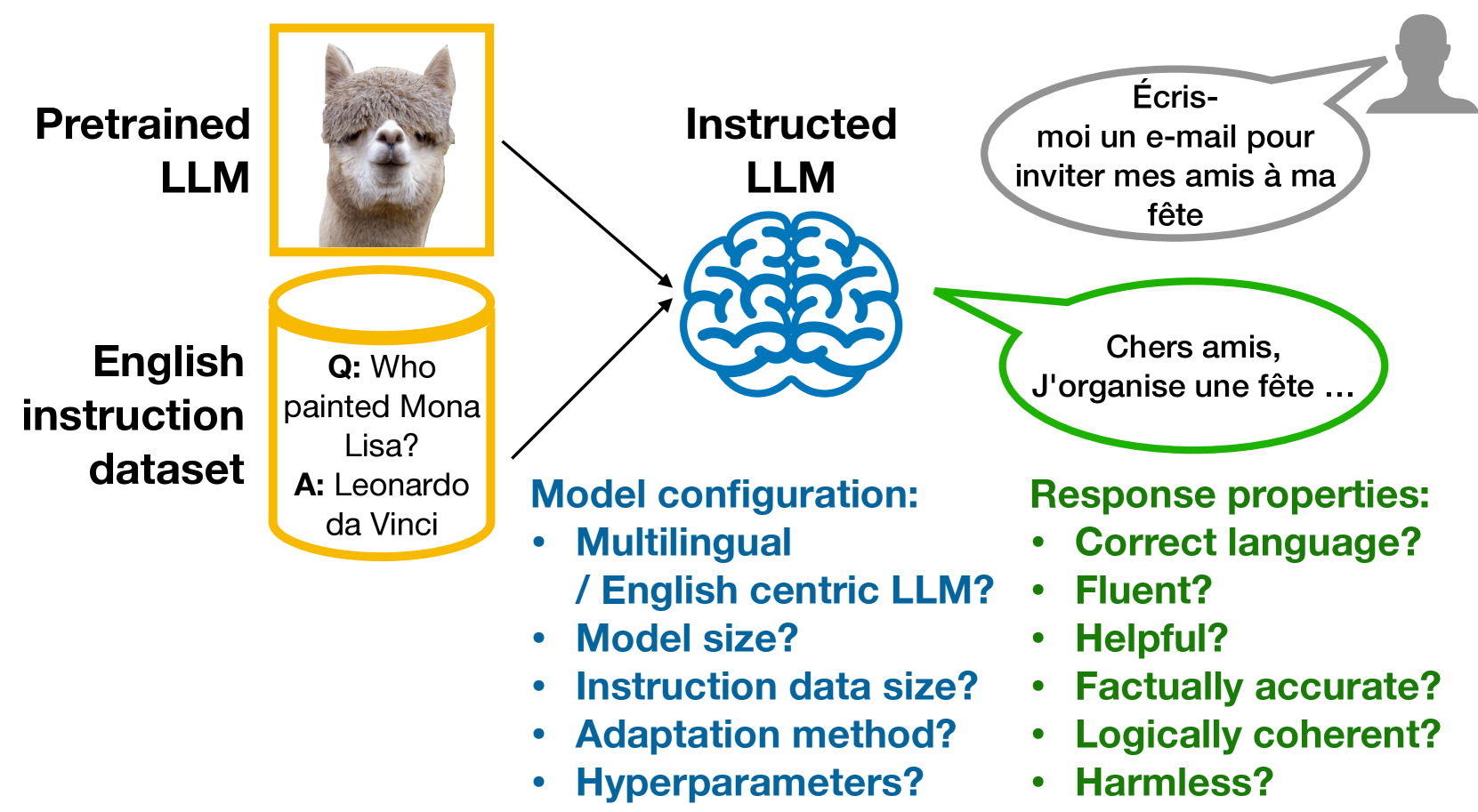
Zero-shot cross-lingual transfer in instruction tuning of large language models
Nadezhda Chirkova, Vassilina Nikoulina
0
0
Instruction tuning (IT) is widely used to teach pretrained large language models (LLMs) to follow arbitrary instructions, but is under-studied in multilingual settings. In this work, we conduct a systematic study of zero-shot cross-lingual transfer in IT, when an LLM is instruction-tuned on English-only data and then tested on user prompts in other languages. We advocate for the importance of evaluating various aspects of model responses in multilingual instruction following and investigate the influence of different model configuration choices. We find that cross-lingual transfer does happen successfully in IT even if all stages of model training are English-centric, but only if multiliguality is taken into account in hyperparameter tuning and with large enough IT data. English-trained LLMs are capable of generating correct-language, comprehensive and helpful responses in other languages, but suffer from low factuality and may occasionally have fluency errors.
4/23/2024