Physics of Language Models: Part 2.1, Grade-School Math and the Hidden Reasoning Process

0
💬
Sign in to get full access
Overview
- Recent advancements in language models have enabled them to solve mathematical reasoning problems with near-perfect accuracy on grade-school level benchmarks like GSM8K.
- This paper aims to formally study how language models solve these problems, addressing fundamental questions about their reasoning capabilities and process.
- The researchers designed a series of controlled experiments to gain insights that extend beyond the current understanding of large language models (LLMs).
Plain English Explanation
The paper explores how large language models are able to solve complex mathematical reasoning problems, often with near-perfect accuracy on tests typically given to elementary school students. The researchers wanted to better understand the underlying mechanisms and reasoning skills that allow these models to perform so well.
To do this, they set up a variety of experiments to investigate several key questions:
- Can the models truly develop genuine reasoning skills, or are they simply memorizing templates and patterns?
- What is the "mental" process the models use to arrive at the solutions?
- Are the models' reasoning skills similar to or different from how humans solve these types of math problems?
- Do the models developed more general reasoning abilities beyond just solving the specific problems in the training data?
- What causes the models to make mistakes in their reasoning?
- How large or complex does a language model need to be in order to effectively solve grade-school level math questions?
By carefully examining the inner workings of these language models, the researchers hoped to uncover new insights that go beyond the current understanding of how these powerful AI systems operate.
Technical Explanation
The paper presents a series of controlled experiments designed to study how language models are able to solve mathematical reasoning problems, often achieving near-perfect accuracy on benchmarks like the GSM8K dataset.
The researchers wanted to address several fundamental questions:
- Can language models truly develop reasoning skills, or do they simply memorize templates?
- What is the model's hidden (mental) reasoning process when solving these problems?
- Do models solve math questions using skills similar to or different from humans?
- Do models trained on GSM8K-like datasets develop reasoning skills beyond those necessary for solving GSM8K problems?
- What mental process causes models to make reasoning mistakes?
- How large or deep must a model be to effectively solve GSM8K-level math questions?
Through these carefully designed experiments, the paper uncovers many hidden mechanisms by which language models solve mathematical questions. The insights gained extend beyond the current understanding of how large language models (LLMs) operate.
Critical Analysis
The paper provides a thorough and thoughtful examination of the reasoning capabilities of language models when it comes to solving mathematical problems. The researchers acknowledge several potential limitations and areas for further research:
- The experiments were conducted on a relatively limited set of mathematical problems (GSM8K), and it's unclear if the insights would generalize to more complex reasoning tasks.
- The paper does not delve into the specific architectural details or training procedures of the language models, which could provide additional insights into their reasoning process.
- The analysis focuses on the models' performance, but does not explore the potential ethical implications or societal impacts of such advanced reasoning capabilities in language models.
Additionally, one could argue that the paper could have benefited from a more critical perspective, challenging certain assumptions or questioning aspects of the research methodology. A more balanced discussion of the limitations and potential drawbacks of the language models' mathematical reasoning abilities could have provided a more well-rounded analysis.
Overall, the paper makes a valuable contribution to our understanding of how language models approach and solve complex reasoning tasks. However, further research and a more diverse range of perspectives would be needed to fully elucidate the nuances and implications of this emerging capability.
Conclusion
This paper represents an important step forward in understanding the reasoning skills of large language models when it comes to solving mathematical problems. By carefully designing a series of experiments, the researchers were able to uncover many hidden mechanisms and insights that go beyond the current understanding of these powerful AI systems.
The findings suggest that language models can develop genuine reasoning capabilities, rather than simply memorizing templates or patterns. The models' mental process for solving math problems appears to be similar in some ways to human reasoning, but also differs in important ways. Additionally, the models may be developing more generalized reasoning skills beyond just the specific problems they were trained on.
While the paper provides valuable insights, it also highlights the need for further research to fully understand the limits and implications of language models' mathematical reasoning abilities. Exploring more complex reasoning tasks, delving into architectural details, and considering ethical concerns will be important next steps in this rapidly evolving field of AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Physics of Language Models: Part 2.1, Grade-School Math and the Hidden Reasoning Process
Tian Ye, Zicheng Xu, Yuanzhi Li, Zeyuan Allen-Zhu
Recent advances in language models have demonstrated their capability to solve mathematical reasoning problems, achieving near-perfect accuracy on grade-school level math benchmarks like GSM8K. In this paper, we formally study how language models solve these problems. We design a series of controlled experiments to address several fundamental questions: (1) Can language models truly develop reasoning skills, or do they simply memorize templates? (2) What is the model's hidden (mental) reasoning process? (3) Do models solve math questions using skills similar to or different from humans? (4) Do models trained on GSM8K-like datasets develop reasoning skills beyond those necessary for solving GSM8K problems? (5) What mental process causes models to make reasoning mistakes? (6) How large or deep must a model be to effectively solve GSM8K-level math questions? Our study uncovers many hidden mechanisms by which language models solve mathematical questions, providing insights that extend beyond current understandings of LLMs.
Read more7/31/2024
💬
0
Logic Contrastive Reasoning with Lightweight Large Language Model for Math Word Problems
Ding Kai, Ma Zhenguo, Yan Xiaoran
This study focuses on improving the performance of lightweight Large Language Models (LLMs) in mathematical reasoning tasks. We introduce a novel method for measuring mathematical logic similarity and design an automatic screening mechanism to construct a set of reference problems that integrate both semantic and logical similarity. By employing carefully crafted positive and negative example prompts, we guide the model towards adopting sound reasoning logic. To the best of our knowledge, this is the first attempt to utilize retrieval-enhanced generation for mathematical problem-solving. Experimental results demonstrate that our method achieves a 15.8% improvement over the Chain of Thought approach on the SVAMP dataset and a 21.5 % improvement on the GSM8K dataset. Further application of this method to a large-scale model with 175 billion parameters yields performance comparable to the best results on both aforementioned datasets. Finally, we conduct an analysis of errors during the reasoning process, providing valuable insights and directions for future research on reasoning tasks using large language models.
Read more9/4/2024
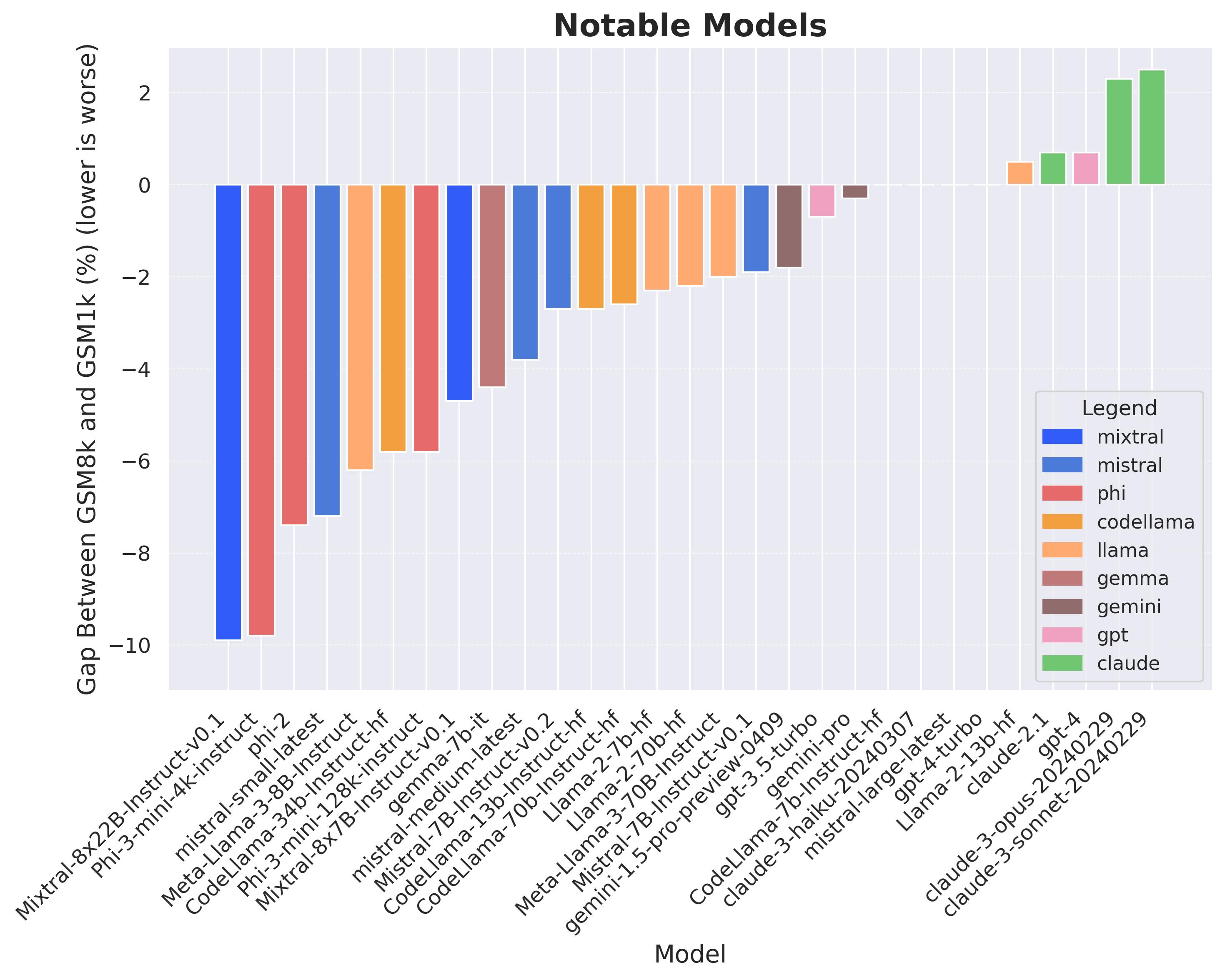
5
A Careful Examination of Large Language Model Performance on Grade School Arithmetic
Hugh Zhang, Jeff Da, Dean Lee, Vaughn Robinson, Catherine Wu, Will Song, Tiffany Zhao, Pranav Raja, Dylan Slack, Qin Lyu, Sean Hendryx, Russell Kaplan, Michele Lunati, Summer Yue
Large language models (LLMs) have achieved impressive success on many benchmarks for mathematical reasoning. However, there is growing concern that some of this performance actually reflects dataset contamination, where data closely resembling benchmark questions leaks into the training data, instead of true reasoning ability. To investigate this claim rigorously, we commission Grade School Math 1000 (GSM1k). GSM1k is designed to mirror the style and complexity of the established GSM8k benchmark, the gold standard for measuring elementary mathematical reasoning. We ensure that the two benchmarks are comparable across important metrics such as human solve rates, number of steps in solution, answer magnitude, and more. When evaluating leading open- and closed-source LLMs on GSM1k, we observe accuracy drops of up to 13%, with several families of models (e.g., Phi and Mistral) showing evidence of systematic overfitting across almost all model sizes. At the same time, many models, especially those on the frontier, (e.g., Gemini/GPT/Claude) show minimal signs of overfitting. Further analysis suggests a positive relationship (Spearman's r^2=0.32) between a model's probability of generating an example from GSM8k and its performance gap between GSM8k and GSM1k, suggesting that many models may have partially memorized GSM8k.
Read more5/6/2024

0
Evaluating Language Model Math Reasoning via Grounding in Educational Curricula
Li Lucy, Tal August, Rose E. Wang, Luca Soldaini, Courtney Allison, Kyle Lo
Our work presents a novel angle for evaluating language models' (LMs) mathematical abilities, by investigating whether they can discern skills and concepts enabled by math content. We contribute two datasets: one consisting of 385 fine-grained descriptions of K-12 math skills and concepts, or standards, from Achieve the Core (ATC), and another of 9.9K problems labeled with these standards (MathFish). Working with experienced teachers, we find that LMs struggle to tag and verify standards linked to problems, and instead predict labels that are close to ground truth, but differ in subtle ways. We also show that LMs often generate problems that do not fully align with standards described in prompts. Finally, we categorize problems in GSM8k using math standards, allowing us to better understand why some problems are more difficult to solve for models than others.
Read more8/13/2024