Scaling Laws for Linear Complexity Language Models
2406.16690
0
0
Abstract
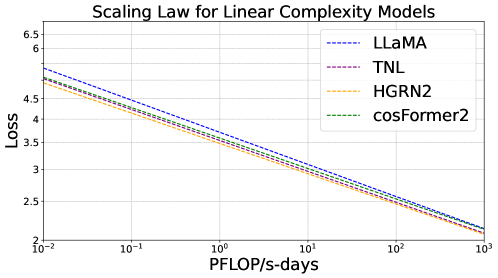
The interest in linear complexity models for large language models is on the rise, although their scaling capacity remains uncertain. In this study, we present the scaling laws for linear complexity language models to establish a foundation for their scalability. Specifically, we examine the scaling behaviors of three efficient linear architectures. These include TNL, a linear attention model with data-independent decay; HGRN2, a linear RNN with data-dependent decay; and cosFormer2, a linear attention model without decay. We also include LLaMA as a baseline architecture for softmax attention for comparison. These models were trained with six variants, ranging from 70M to 7B parameters on a 300B-token corpus, and evaluated with a total of 1,376 intermediate checkpoints on various downstream tasks. These tasks include validation loss, commonsense reasoning, and information retrieval and generation. The study reveals that existing linear complexity language models exhibit similar scaling capabilities as conventional transformer-based models while also demonstrating superior linguistic proficiency and knowledge retention.
Create account to get full access
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👨🏫
Scaling-laws for Large Time-series Models
Thomas D. P. Edwards, James Alvey, Justin Alsing, Nam H. Nguyen, Benjamin D. Wandelt
0
0
Scaling laws for large language models (LLMs) have provided useful guidance on how to train ever larger models for predictable performance gains. Time series forecasting shares a similar sequential structure to language, and is amenable to large-scale transformer architectures. Here we show that foundational decoder-only time series transformer models exhibit analogous scaling-behavior to LLMs, while architectural details (aspect ratio and number of heads) have a minimal effect over broad ranges. We assemble a large corpus of heterogenous time series data on which to train, and establish, for the first time, power-law scaling relations with respect to parameter count, dataset size, and training compute, spanning five orders of magnitude.
5/24/2024
Temporal Scaling Law for Large Language Models
Yizhe Xiong, Xiansheng Chen, Xin Ye, Hui Chen, Zijia Lin, Haoran Lian, Zhenpeng Su, Jianwei Niu, Guiguang Ding
0
0
Recently, Large Language Models (LLMs) have been widely adopted in a wide range of tasks, leading to increasing attention towards the research on how scaling LLMs affects their performance. Existing works, termed Scaling Laws, have discovered that the final test loss of LLMs scales as power-laws with model size, computational budget, and dataset size. However, the temporal change of the test loss of an LLM throughout its pre-training process remains unexplored, though it is valuable in many aspects, such as selecting better hyperparameters textit{directly} on the target LLM. In this paper, we propose the novel concept of Temporal Scaling Law, studying how the test loss of an LLM evolves as the training steps scale up. In contrast to modeling the test loss as a whole in a coarse-grained manner, we break it down and dive into the fine-grained test loss of each token position, and further develop a dynamic hyperbolic-law. Afterwards, we derive the much more precise temporal scaling law by studying the temporal patterns of the parameters in the dynamic hyperbolic-law. Results on both in-distribution (ID) and out-of-distribution (OOD) validation datasets demonstrate that our temporal scaling law accurately predicts the test loss of LLMs across training steps. Our temporal scaling law has broad practical applications. First, it enables direct and efficient hyperparameter selection on the target LLM, such as data mixture proportions. Secondly, viewing the LLM pre-training dynamics from the token position granularity provides some insights to enhance the understanding of LLM pre-training.
6/18/2024
Unraveling the Mystery of Scaling Laws: Part I
Hui Su, Zhi Tian, Xiaoyu Shen, Xunliang Cai
0
0
Scaling law principles indicate a power-law correlation between loss and variables such as model size, dataset size, and computational resources utilized during training. These principles play a vital role in optimizing various aspects of model pre-training, ultimately contributing to the success of large language models such as GPT-4, Llama and Gemini. However, the original scaling law paper by OpenAI did not disclose the complete details necessary to derive the precise scaling law formulas, and their conclusions are only based on models containing up to 1.5 billion parameters. Though some subsequent works attempt to unveil these details and scale to larger models, they often neglect the training dependency of important factors such as the learning rate, context length and batch size, leading to their failure to establish a reliable formula for predicting the test loss trajectory. In this technical report, we confirm that the scaling law formulations proposed in the original OpenAI paper remain valid when scaling the model size up to 33 billion, but the constant coefficients in these formulas vary significantly with the experiment setup. We meticulously identify influential factors and provide transparent, step-by-step instructions to estimate all constant terms in scaling-law formulas by training on models with only 1M~60M parameters. Using these estimated formulas, we showcase the capability to accurately predict various attributes for models with up to 33B parameters before their training, including (1) the minimum possible test loss; (2) the minimum required training steps and processed tokens to achieve a specific loss; (3) the critical batch size with an optimal time/computation trade-off at any loss value; and (4) the complete test loss trajectory with arbitrary batch size.
4/8/2024

Language models scale reliably with over-training and on downstream tasks
Samir Yitzhak Gadre, Georgios Smyrnis, Vaishaal Shankar, Suchin Gururangan, Mitchell Wortsman, Rulin Shao, Jean Mercat, Alex Fang, Jeffrey Li, Sedrick Keh, Rui Xin, Marianna Nezhurina, Igor Vasiljevic, Jenia Jitsev, Luca Soldaini, Alexandros G. Dimakis, Gabriel Ilharco, Pang Wei Koh, Shuran Song, Thomas Kollar, Yair Carmon, Achal Dave, Reinhard Heckel, Niklas Muennighoff, Ludwig Schmidt
0
0
Scaling laws are useful guides for derisking expensive training runs, as they predict performance of large models using cheaper, small-scale experiments. However, there remain gaps between current scaling studies and how language models are ultimately trained and evaluated. For instance, scaling is usually studied in the compute-optimal training regime (i.e., Chinchilla optimal regime). In contrast, models are often over-trained to reduce inference costs. Moreover, scaling laws mostly predict loss on next-token prediction, but models are usually compared on downstream task performance. To address both shortcomings, we create a testbed of 104 models with 0.011B to 6.9B parameters trained with various numbers of tokens on three data distributions. First, we fit scaling laws that extrapolate in both the amount of over-training and the number of model parameters. This enables us to predict the validation loss of a 1.4B parameter, 900B token run (i.e., 32$times$ over-trained) and a 6.9B parameter, 138B token run (i.e., a compute-optimal run)$unicode{x2014}$each from experiments that take 300$times$ less compute. Second, we relate the perplexity of a language model to its downstream task performance by proposing a power law. We use this law to predict top-1 error averaged over downstream tasks for the two aforementioned models, using experiments that take 20$times$ less compute. Our experiments are available at https://github.com/mlfoundations/scaling.
6/18/2024