Picturing Ambiguity: A Visual Twist on the Winograd Schema Challenge

0

Sign in to get full access
Overview
- The paper proposes a "Picturing Ambiguity" approach to the Winograd Schema Challenge, a benchmark for testing language understanding
- The method involves presenting ambiguous visual scenes instead of text-based prompts, requiring models to understand the context and relationships between objects to resolve the ambiguity
- The authors develop a dataset of over 2,000 visually ambiguous images and evaluate several large language models on this new "Visual Winograd" task
Plain English Explanation
The Picturing Ambiguity paper presents a novel way to test the language understanding capabilities of AI models. Instead of using written word puzzles, the researchers create ambiguous visual scenes that require the model to grasp the context and relationships between objects to resolve the ambiguity.
For example, an image might show two people, one holding a bat and the other holding a ball. The question could be "Who is going to hit the ball?" The correct answer depends on understanding that the person holding the bat is more likely to hit the ball, even though the wording is ambiguous.
By using visuals instead of text, the "Visual Winograd" task assesses the model's ability to combine visual and language understanding, which is an important step towards more natural and human-like AI reasoning.
Technical Explanation
The paper first provides background on the Winograd Schema Challenge, a widely used benchmark for evaluating language understanding in AI systems. The authors then describe their "Picturing Ambiguity" approach, where they create a dataset of over 2,000 visually ambiguous images along with corresponding questions that rely on contextual understanding to answer correctly.
To generate the dataset, the researchers used crowdsourcing to create images with two or more plausible interpretations, and then crafted questions that would test the model's ability to resolve the ambiguity. They then evaluated several large language models, including GPT-3, CLIP, and BLIP, on this new "Visual Winograd" task.
The results showed that the language models struggled to match human-level performance on the task, highlighting the challenges of multimodal reasoning compared to text-based language understanding. The authors suggest that this new benchmark can help drive progress in building AI systems that can truly understand the nuances of language and visual context.
Critical Analysis
While the "Picturing Ambiguity" approach is a novel and interesting way to test language understanding, the paper acknowledges several limitations. The dataset is relatively small, and the authors note that more diverse and challenging visual scenes may be needed to fully stress test model capabilities.
Additionally, the paper does not delve deeply into the specific reasons why the language models struggled on the Visual Winograd task. Further analysis of the model's strengths, weaknesses, and failure modes could provide valuable insights for improving multimodal reasoning in AI systems.
It would also be interesting to see how the performance of these models compares to humans on the same task, and whether there are any systematic biases or errors that the models exhibit that could inform future research.
Conclusion
The "Picturing Ambiguity" paper presents a creative and thought-provoking approach to evaluating language understanding in AI systems. By shifting the focus from text-based puzzles to visually ambiguous scenes, the researchers have highlighted the challenges of multimodal reasoning and the need for more holistic language understanding capabilities in AI.
While the current results show that large language models still have room for improvement, this new benchmark could serve as a valuable tool for driving progress in the field of artificial intelligence, ultimately leading to systems that can better comprehend and interact with the world around them.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Picturing Ambiguity: A Visual Twist on the Winograd Schema Challenge
Brendan Park, Madeline Janecek, Naser Ezzati-Jivan, Yifeng Li, Ali Emami
Large Language Models (LLMs) have demonstrated remarkable success in tasks like the Winograd Schema Challenge (WSC), showcasing advanced textual common-sense reasoning. However, applying this reasoning to multimodal domains, where understanding text and images together is essential, remains a substantial challenge. To address this, we introduce WinoVis, a novel dataset specifically designed to probe text-to-image models on pronoun disambiguation within multimodal contexts. Utilizing GPT-4 for prompt generation and Diffusion Attentive Attribution Maps (DAAM) for heatmap analysis, we propose a novel evaluation framework that isolates the models' ability in pronoun disambiguation from other visual processing challenges. Evaluation of successive model versions reveals that, despite incremental advancements, Stable Diffusion 2.0 achieves a precision of 56.7% on WinoVis, only marginally surpassing random guessing. Further error analysis identifies important areas for future research aimed at advancing text-to-image models in their ability to interpret and interact with the complex visual world.
Read more6/4/2024

0
New!Can visual language models resolve textual ambiguity with visual cues? Let visual puns tell you!
Jiwan Chung, Seungwon Lim, Jaehyun Jeon, Seungbeen Lee, Youngjae Yu
Humans possess multimodal literacy, allowing them to actively integrate information from various modalities to form reasoning. Faced with challenges like lexical ambiguity in text, we supplement this with other modalities, such as thumbnail images or textbook illustrations. Is it possible for machines to achieve a similar multimodal understanding capability? In response, we present Understanding Pun with Image Explanations (UNPIE), a novel benchmark designed to assess the impact of multimodal inputs in resolving lexical ambiguities. Puns serve as the ideal subject for this evaluation due to their intrinsic ambiguity. Our dataset includes 1,000 puns, each accompanied by an image that explains both meanings. We pose three multimodal challenges with the annotations to assess different aspects of multimodal literacy; Pun Grounding, Disambiguation, and Reconstruction. The results indicate that various Socratic Models and Visual-Language Models improve over the text-only models when given visual context, particularly as the complexity of the tasks increases.
Read more10/3/2024

0
ViP-LLaVA: Making Large Multimodal Models Understand Arbitrary Visual Prompts
Mu Cai, Haotian Liu, Dennis Park, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Yong Jae Lee
While existing large vision-language multimodal models focus on whole image understanding, there is a prominent gap in achieving region-specific comprehension. Current approaches that use textual coordinates or spatial encodings often fail to provide a user-friendly interface for visual prompting. To address this challenge, we introduce a novel multimodal model capable of decoding arbitrary visual prompts. This allows users to intuitively mark images and interact with the model using natural cues like a red bounding box or pointed arrow. Our simple design directly overlays visual markers onto the RGB image, eliminating the need for complex region encodings, yet achieves state-of-the-art performance on region-understanding tasks like Visual7W, PointQA, and Visual Commonsense Reasoning benchmark. Furthermore, we present ViP-Bench, a comprehensive benchmark to assess the capability of models in understanding visual prompts across multiple dimensions, enabling future research in this domain. Code, data, and model are publicly available.
Read more4/30/2024
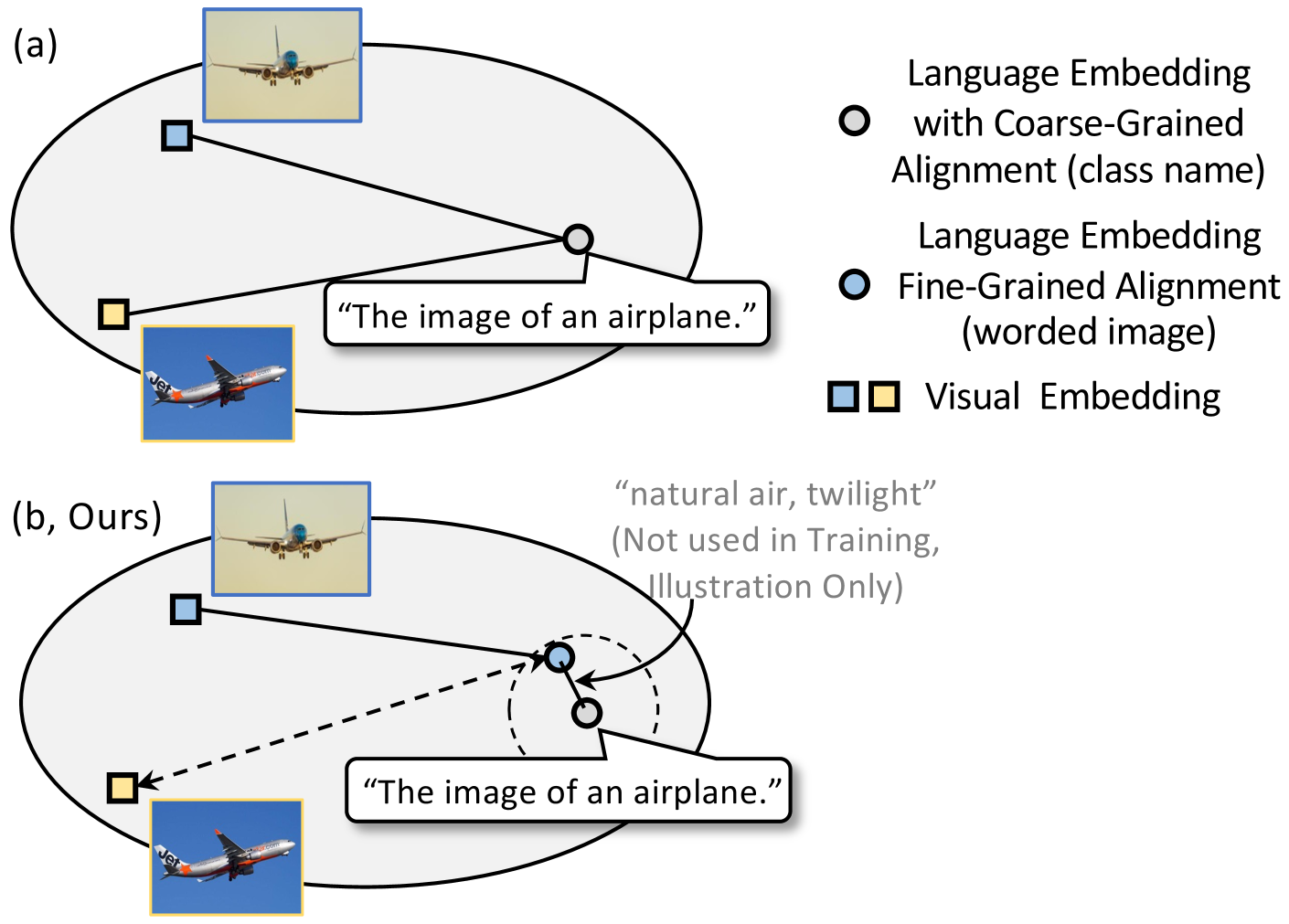
0
WIDIn: Wording Image for Domain-Invariant Representation in Single-Source Domain Generalization
Jiawei Ma, Yulei Niu, Shiyuan Huang, Guangxing Han, Shih-Fu Chang
Language has been useful in extending the vision encoder to data from diverse distributions without empirical discovery in training domains. However, as the image description is mostly at coarse-grained level and ignores visual details, the resulted embeddings are still ineffective in overcoming complexity of domains at inference time. We present a self-supervision framework WIDIn, Wording Images for Domain-Invariant representation, to disentangle discriminative visual representation, by only leveraging data in a single domain and without any test prior. Specifically, for each image, we first estimate the language embedding with fine-grained alignment, which can be consequently used to adaptively identify and then remove domain-specific counterpart from the raw visual embedding. WIDIn can be applied to both pretrained vision-language models like CLIP, and separately trained uni-modal models like MoCo and BERT. Experimental studies on three domain generalization datasets demonstrate the effectiveness of our approach.
Read more5/29/2024