On-Policy Fine-grained Knowledge Feedback for Hallucination Mitigation

0

Sign in to get full access
Overview
- This paper proposes a novel on-policy fine-grained knowledge feedback approach to mitigate hallucination in large vision-language models.
- The key idea is to provide the model with detailed feedback on its outputs, allowing it to learn to avoid hallucination and generate more faithful and truthful responses.
- The approach is evaluated on several visual question answering benchmarks, demonstrating its effectiveness in reducing hallucination while maintaining high performance.
Plain English Explanation
On-Policy Fine-grained Knowledge Feedback for Hallucination Mitigation addresses a significant challenge in large vision-language models - the tendency to produce fabricated or inaccurate responses, known as hallucination. The researchers developed a new technique to help these models learn to avoid hallucination and provide more truthful and reliable outputs.
The key idea is to give the model detailed feedback on its responses, pointing out when it has hallucinated or provided inaccurate information. This on-policy feedback allows the model to learn from its mistakes and improve its behavior over time. The researchers evaluate this approach on visual question answering tasks, where the model must answer questions about images, and show that it can significantly reduce hallucination while maintaining high performance.
This work builds on prior research on aligning large vision-language models to ground-truth knowledge and mitigating hallucination through faithful fine-tuning. By providing fine-grained, real-time feedback to the model, this approach helps it learn to generate more truthful and reliable responses, which is crucial for building trustworthy AI systems.
Technical Explanation
On-Policy Fine-grained Knowledge Feedback for Hallucination Mitigation presents a novel technique to address the problem of hallucination in large vision-language models. Hallucination refers to the tendency of these models to generate fabricated or inaccurate outputs that do not align with the ground truth.
The key innovation is the use of on-policy fine-grained knowledge feedback, where the model receives detailed information about the correctness of its outputs during inference. This feedback is used to update the model's parameters, allowing it to learn to avoid hallucination and generate more faithful responses.
The approach is evaluated on several visual question answering benchmarks, including VQAv2 and OKVQA. The results demonstrate that the fine-grained feedback can significantly reduce hallucination while maintaining high performance on the tasks.
The proposed architecture consists of a vision-language model, a hallucination detection module, and a feedback module. During inference, the model generates an answer, which is then analyzed by the hallucination detection module. If hallucination is detected, the feedback module provides detailed information about the nature of the error, which is used to update the model's parameters.
This work builds on previous research on aligning large vision-language models to ground-truth knowledge and mitigating hallucination through faithful fine-tuning. By providing fine-grained, real-time feedback to the model, this approach helps it learn to generate more truthful and reliable responses, which is crucial for building trustworthy AI systems.
Critical Analysis
The paper presents a compelling approach to mitigating hallucination in large vision-language models, but there are a few potential limitations and areas for further research.
One concern is the generalization of the hallucination detection module. The authors mention that it was trained on a specific dataset, and it's unclear how well it would perform on a broader range of inputs or in real-world deployment scenarios. Further research could explore more robust and generalizable hallucination detection methods.
Additionally, the paper does not address the potential for the feedback mechanism to introduce new biases or errors into the model. It's possible that the feedback could steer the model towards overly conservative or risk-averse behavior, which could also impact its performance. Investigating the long-term effects of the feedback loop on model behavior would be an important area for future work.
Despite these caveats, the core idea of using fine-grained, on-policy feedback to mitigate hallucination is a promising approach that could have significant implications for the development of trustworthy and reliable AI systems. Further research in this direction could lead to important advancements in the field.
Conclusion
On-Policy Fine-grained Knowledge Feedback for Hallucination Mitigation presents a novel technique to address the problem of hallucination in large vision-language models. By providing the model with detailed, real-time feedback on the accuracy of its outputs, the approach helps it learn to avoid generating fabricated or inaccurate responses and instead produce more truthful and reliable outputs.
The evaluation results on visual question answering benchmarks demonstrate the effectiveness of this approach in reducing hallucination while maintaining high performance. This work builds on and complements prior research on aligning large vision-language models to ground-truth knowledge and mitigating hallucination through faithful fine-tuning.
Overall, this research represents an important step towards developing more trustworthy and reliable AI systems, which is crucial for their widespread adoption and beneficial impact on society. Further work is needed to address potential limitations and explore the broader implications of this approach, but the core ideas presented in this paper have significant potential to advance the field of large-scale vision-language modeling.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
On-Policy Fine-grained Knowledge Feedback for Hallucination Mitigation
Xueru Wen, Xinyu Lu, Xinyan Guan, Yaojie Lu, Hongyu Lin, Ben He, Xianpei Han, Le Sun
Hallucination occurs when large language models (LLMs) exhibit behavior that deviates from the boundaries of their knowledge during the response generation process. Previous learning-based methods focus on detecting knowledge boundaries and finetuning models with instance-level feedback, but they suffer from inaccurate signals due to off-policy data sampling and coarse-grained feedback. In this paper, we introduce textit{b{R}einforcement b{L}earning b{f}or b{H}allucination} (RLFH), a fine-grained feedback-based online reinforcement learning method for hallucination mitigation. Unlike previous learning-based methods, RLFH enables LLMs to explore the boundaries of their internal knowledge and provide on-policy, fine-grained feedback on these explorations. To construct fine-grained feedback for learning reliable generation behavior, RLFH decomposes the outcomes of large models into atomic facts, provides statement-level evaluation signals, and traces back the signals to the tokens of the original responses. Finally, RLFH adopts the online reinforcement algorithm with these token-level rewards to adjust model behavior for hallucination mitigation. For effective on-policy optimization, RLFH also introduces an LLM-based fact assessment framework to verify the truthfulness and helpfulness of atomic facts without human intervention. Experiments on HotpotQA, SQuADv2, and Biography benchmarks demonstrate that RLFH can balance their usage of internal knowledge during the generation process to eliminate the hallucination behavior of LLMs.
Read more6/19/2024
0
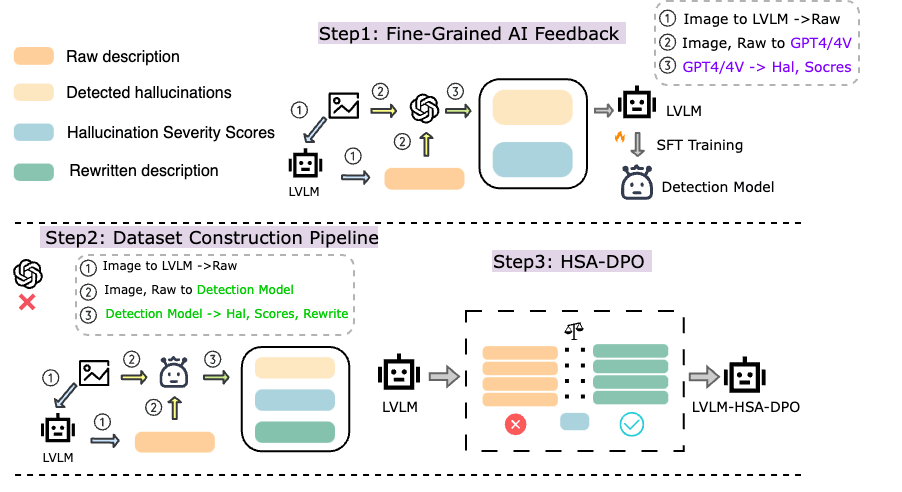
Detecting and Mitigating Hallucination in Large Vision Language Models via Fine-Grained AI Feedback
Wenyi Xiao, Ziwei Huang, Leilei Gan, Wanggui He, Haoyuan Li, Zhelun Yu, Hao Jiang, Fei Wu, Linchao Zhu
The rapidly developing Large Vision Language Models (LVLMs) have shown notable capabilities on a range of multi-modal tasks, but still face the hallucination phenomena where the generated texts do not align with the given contexts, significantly restricting the usages of LVLMs. Most previous work detects and mitigates hallucination at the coarse-grained level or requires expensive annotation (e.g., labeling by proprietary models or human experts). To address these issues, we propose detecting and mitigating hallucinations in LVLMs via fine-grained AI feedback. The basic idea is that we generate a small-size sentence-level hallucination annotation dataset by proprietary models, whereby we train a hallucination detection model which can perform sentence-level hallucination detection, covering primary hallucination types (i.e., object, attribute, and relationship). Then, we propose a detect-then-rewrite pipeline to automatically construct preference dataset for training hallucination mitigating model. Furthermore, we propose differentiating the severity of hallucinations, and introducing a Hallucination Severity-Aware Direct Preference Optimization (HSA-DPO) for mitigating hallucination in LVLMs by incorporating the severity of hallucinations into preference learning. Extensive experiments demonstrate the effectiveness of our method.
Read more4/23/2024

0
FGAIF: Aligning Large Vision-Language Models with Fine-grained AI Feedback
Liqiang Jing, Xinya Du
Large Vision-Language Models (LVLMs) have demonstrated proficiency in tackling a variety of visual-language tasks. However, current LVLMs suffer from misalignment between text and image modalities which causes three kinds of hallucination problems, i.e., object existence, object attribute, and object relationship. To tackle this issue, existing methods mainly utilize Reinforcement Learning (RL) to align modalities in LVLMs. However, they still suffer from three main limitations: (1) General feedback can not indicate the hallucination type contained in the response; (2) Sparse rewards only give the sequence-level reward for the whole response; and (3)Annotation cost is time-consuming and labor-intensive. To handle these limitations, we propose an innovative method to align modalities in LVLMs through Fine-Grained Artificial Intelligence Feedback (FGAIF), which mainly consists of three steps: AI-based Feedback Collection, Fine-grained Reward Model Training, and Reinforcement Learning with Fine-grained Reward. Specifically, We first utilize AI tools to predict the types of hallucination for each segment in the response and obtain a collection of fine-grained feedback. Then, based on the collected reward data, three specialized reward models are trained to produce dense rewards. Finally, a novel fine-grained feedback module is integrated into the Proximal Policy Optimization (PPO) algorithm. Extensive experiments are conducted on hallucination and general benchmarks, demonstrating the superior performance of our proposed method. Notably, compared with previous models trained with the RL-based aligning method, our proposed method is effective even with fewer parameters.
Read more4/9/2024

0
Mitigating Large Language Model Hallucination with Faithful Finetuning
Minda Hu, Bowei He, Yufei Wang, Liangyou Li, Chen Ma, Irwin King
Large language models (LLMs) have demonstrated remarkable performance on various natural language processing tasks. However, they are prone to generating fluent yet untruthful responses, known as hallucinations. Hallucinations can lead to the spread of misinformation and cause harm in critical applications. Mitigating hallucinations is challenging as they arise from factors such as noisy data, model overconfidence, lack of knowledge, and the generation process itself. Recent efforts have attempted to address this issue through representation editing and decoding algorithms, reducing hallucinations without major structural changes or retraining. However, these approaches either implicitly edit LLMs' behavior in latent space or suppress the tendency to output unfaithful results during decoding instead of explicitly modeling on hallucination. In this work, we introduce Faithful Finetuning (F2), a novel method that explicitly models the process of faithful question answering through carefully designed loss functions during fine-tuning. We conduct extensive experiments on popular datasets and demonstrate that F2 achieves significant improvements over vanilla models and baselines.
Read more6/18/2024