A policy gradient approach for Finite Horizon Constrained Markov Decision Processes

0
💬
Sign in to get full access
Overview
- The paper presents a novel algorithm for Constrained Reinforcement Learning (CRL) in the Finite Horizon setting.
- Finite horizon control problems, where the optimal policy is time-varying, are common in real-world scenarios.
- Previous CRL research has focused on the Infinite Horizon setting, where stationary policies are optimal.
- The proposed algorithm uses function approximation and policy gradient methods to find the constrained optimal policy, which can be non-stationary.
- This is the first policy gradient algorithm for CRL in the Finite Horizon setting.
Plain English Explanation
Reinforcement learning (RL) is a powerful technique for training artificial agents to make decisions and take actions in a given environment. In the infinite horizon setting, the agent's goal is to maximize its rewards over an unlimited time, which results in stationary (unchanging) optimal policies.
However, in many real-world situations, the agent's task has a finite duration, or "horizon." In these finite horizon problems, the optimal policy can change over time. Additionally, the agent may need to satisfy certain constraints, such as maintaining safety or resource limits, while maximizing its rewards. This is known as Constrained Reinforcement Learning (CRL).
Previous CRL research has focused on the infinite horizon setting, where stationary policies are optimal. In this paper, the authors present a novel algorithm for CRL in the finite horizon setting. Their approach uses function approximation and policy gradient methods to find the constrained optimal policy, which can be non-stationary (changing over time).
To illustrate, imagine a robot tasked with navigating a maze to collect as many valuable items as possible, while also conserving its battery life. In the infinite horizon setting, the robot might learn a fixed policy that balances reward collection and battery usage. But in the finite horizon setting, the optimal policy could change as the robot's battery level decreases, prioritizing battery conservation towards the end of the task.
The authors show that their algorithm can converge to the constrained optimal policy in the finite horizon setting, and demonstrate its performance advantages over other well-known algorithms through experiments. This research opens up new possibilities for applying RL to real-world problems with time-varying constraints and objectives.
Technical Explanation
The paper presents a policy gradient algorithm for Constrained Reinforcement Learning (CRL) in the Finite Horizon setting. In this setting, the agent's task has a fixed, finite duration, and the optimal policy can be time-varying, in contrast to the Infinite Horizon setting where stationary policies are optimal.
The authors use function approximation, such as neural networks, to represent the agent's policy. This is essential when the state and action spaces are large or continuous, as is common in real-world problems. They then employ policy gradient methods to find the constrained optimal policy, which can be non-stationary (changing over time) in the Finite Horizon setting.
The key steps of the algorithm are:
- Initialize the policy parameters.
- Compute the policy gradient with respect to the reward and constraint functions.
- Update the policy parameters using the gradient.
- Repeat steps 2-3 until convergence.
The authors prove the convergence of their algorithm to a constrained optimal policy in the Finite Horizon setting. They also compare the performance of their algorithm to other well-known algorithms, such as randomized algorithms for inverse reinforcement learning and the primal-dual approach for offline constrained RL, through extensive experiments. The results show that their algorithm outperforms these other methods in the Finite Horizon CRL setting.
Critical Analysis
The paper presents a novel and important contribution to the field of Constrained Reinforcement Learning, as it addresses the Finite Horizon setting, which is more common in real-world applications than the Infinite Horizon setting studied in previous CRL research.
One potential limitation of the approach is the use of function approximation, which can be sensitive to hyperparameter tuning and may struggle with high-dimensional state or action spaces. The authors acknowledge this and suggest that future research could explore alternative function approximation methods to improve the algorithm's robustness.
Additionally, the paper does not discuss the potential for the algorithm to become unstable or diverge, which is a common challenge in policy gradient methods. Further analysis of the algorithm's sensitivity to factors like initial conditions or constraint violations would be valuable.
Overall, this research represents an important step forward in applying Constrained Reinforcement Learning to more realistic, time-varying problems. The proposed algorithm and its demonstrated performance advantages suggest promising avenues for future work in this area.
Conclusion
This paper presents a novel policy gradient algorithm for Constrained Reinforcement Learning in the Finite Horizon setting, where the optimal policy can be time-varying. By using function approximation and policy gradient methods, the authors are able to find the constrained optimal policy, which is a significant advancement over previous CRL research that focused on the Infinite Horizon setting.
The authors prove the convergence of their algorithm and show through experiments that it outperforms other well-known CRL algorithms in the Finite Horizon setting. This research opens up new possibilities for applying Reinforcement Learning to real-world problems with time-varying constraints and objectives, which are more common in practice than the Infinite Horizon setting.
Future work could explore ways to improve the algorithm's robustness, such as through alternative function approximation methods or stability analysis. Overall, this paper represents an important contribution to the field of Constrained Reinforcement Learning and its application to more realistic problem settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
A policy gradient approach for Finite Horizon Constrained Markov Decision Processes
Soumyajit Guin, Shalabh Bhatnagar
The infinite horizon setting is widely adopted for problems of reinforcement learning (RL). These invariably result in stationary policies that are optimal. In many situations, finite horizon control problems are of interest and for such problems, the optimal policies are time-varying in general. Another setting that has become popular in recent times is of Constrained Reinforcement Learning, where the agent maximizes its rewards while it also aims to satisfy some given constraint criteria. However, this setting has only been studied in the context of infinite horizon MDPs where stationary policies are optimal. We present an algorithm for constrained RL in the Finite Horizon Setting where the horizon terminates after a fixed (finite) time. We use function approximation in our algorithm which is essential when the state and action spaces are large or continuous and use the policy gradient method to find the optimal policy. The optimal policy that we obtain depends on the stage and so is non-stationary in general. To the best of our knowledge, our paper presents the first policy gradient algorithm for the finite horizon setting with constraints. We show the convergence of our algorithm to a constrained optimal policy. We also compare and analyze the performance of our algorithm through experiments and show that our algorithm performs better than some other well known algorithms.
Read more6/24/2024
🛠️
0
Landscape of Policy Optimization for Finite Horizon MDPs with General State and Action
Xin Chen, Yifan Hu, Minda Zhao
Policy gradient methods are widely used in reinforcement learning. Yet, the nonconvexity of policy optimization imposes significant challenges in understanding the global convergence of policy gradient methods. For a class of finite-horizon Markov Decision Processes (MDPs) with general state and action spaces, we develop a framework that provides a set of easily verifiable assumptions to ensure the Kurdyka-Lojasiewicz (KL) condition of the policy optimization. Leveraging the KL condition, policy gradient methods converge to the globally optimal policy with a non-asymptomatic rate despite nonconvexity. Our results find applications in various control and operations models, including entropy-regularized tabular MDPs, Linear Quadratic Regulator (LQR) problems, stochastic inventory models, and stochastic cash balance problems, for which we show an $epsilon$-optimal policy can be obtained using a sample size in $tilde{mathcal{O}}(epsilon^{-1})$ and polynomial in terms of the planning horizon by stochastic policy gradient methods. Our result establishes the first sample complexity for multi-period inventory systems with Markov-modulated demands and stochastic cash balance problems in the literature.
Read more9/26/2024

0
Tensor Low-rank Approximation of Finite-horizon Value Functions
Sergio Rozada, Antonio G. Marques
The goal of reinforcement learning is estimating a policy that maps states to actions and maximizes the cumulative reward of a Markov Decision Process (MDP). This is oftentimes achieved by estimating first the optimal (reward) value function (VF) associated with each state-action pair. When the MDP has an infinite horizon, the optimal VFs and policies are stationary under mild conditions. However, in finite-horizon MDPs, the VFs (hence, the policies) vary with time. This poses a challenge since the number of VFs to estimate grows not only with the size of the state-action space but also with the time horizon. This paper proposes a non-parametric low-rank stochastic algorithm to approximate the VFs of finite-horizon MDPs. First, we represent the (unknown) VFs as a multi-dimensional array, or tensor, where time is one of the dimensions. Then, we use rewards sampled from the MDP to estimate the optimal VFs. More precisely, we use the (truncated) PARAFAC decomposition to design an online low-rank algorithm that recovers the entries of the tensor of VFs. The size of the low-rank PARAFAC model grows additively with respect to each of its dimensions, rendering our approach efficient, as demonstrated via numerical experiments.
Read more5/29/2024
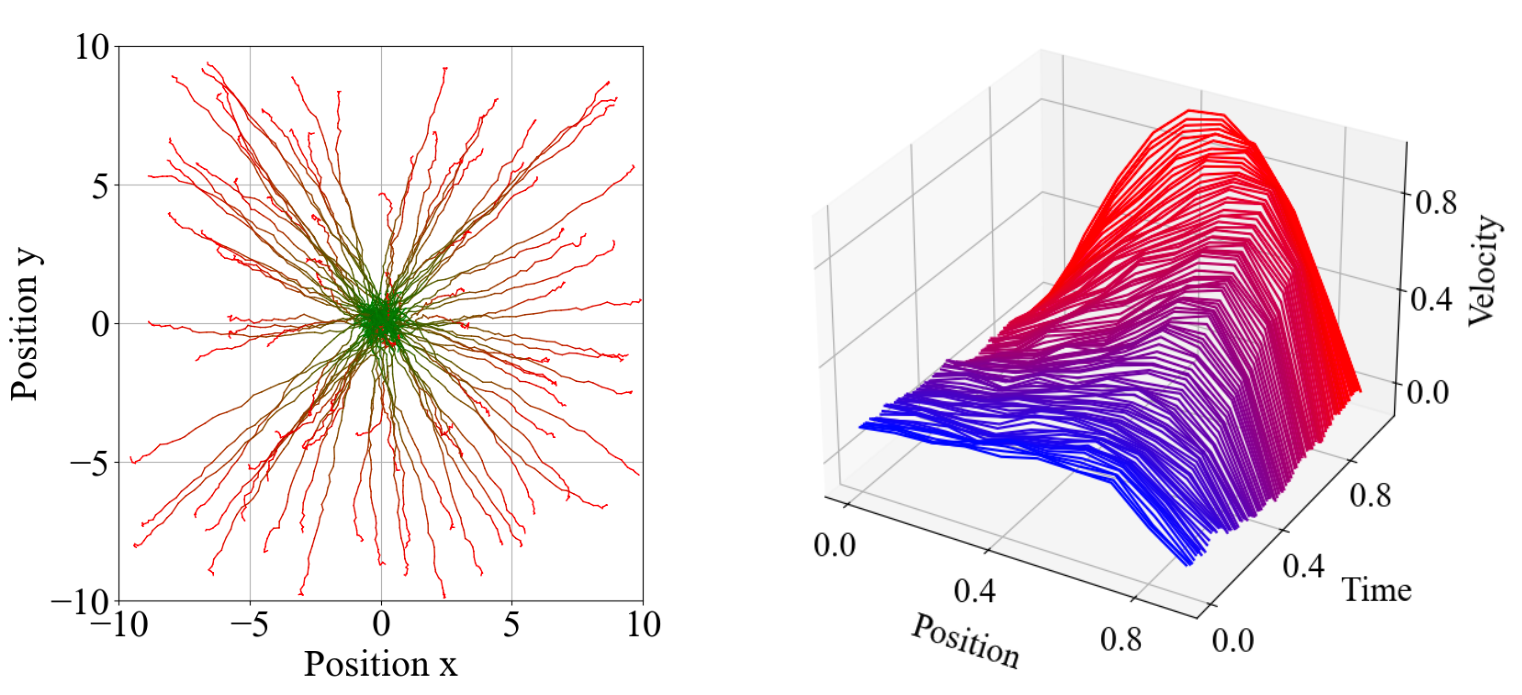
0
Deterministic Policy Gradient Primal-Dual Methods for Continuous-Space Constrained MDPs
Sergio Rozada, Dongsheng Ding, Antonio G. Marques, Alejandro Ribeiro
We study the problem of computing deterministic optimal policies for constrained Markov decision processes (MDPs) with continuous state and action spaces, which are widely encountered in constrained dynamical systems. Designing deterministic policy gradient methods in continuous state and action spaces is particularly challenging due to the lack of enumerable state-action pairs and the adoption of deterministic policies, hindering the application of existing policy gradient methods for constrained MDPs. To this end, we develop a deterministic policy gradient primal-dual method to find an optimal deterministic policy with non-asymptotic convergence. Specifically, we leverage regularization of the Lagrangian of the constrained MDP to propose a deterministic policy gradient primal-dual (D-PGPD) algorithm that updates the deterministic policy via a quadratic-regularized gradient ascent step and the dual variable via a quadratic-regularized gradient descent step. We prove that the primal-dual iterates of D-PGPD converge at a sub-linear rate to an optimal regularized primal-dual pair. We instantiate D-PGPD with function approximation and prove that the primal-dual iterates of D-PGPD converge at a sub-linear rate to an optimal regularized primal-dual pair, up to a function approximation error. Furthermore, we demonstrate the effectiveness of our method in two continuous control problems: robot navigation and fluid control. To the best of our knowledge, this appears to be the first work that proposes a deterministic policy search method for continuous-space constrained MDPs.
Read more8/20/2024