Policy Learning with a Language Bottleneck
2405.04118
0
0
💬
Abstract
Modern AI systems such as self-driving cars and game-playing agents achieve superhuman performance, but often lack human-like features such as generalization, interpretability and human inter-operability. Inspired by the rich interactions between language and decision-making in humans, we introduce Policy Learning with a Language Bottleneck (PLLB), a framework enabling AI agents to generate linguistic rules that capture the strategies underlying their most rewarding behaviors. PLLB alternates between a rule generation step guided by language models, and an update step where agents learn new policies guided by rules. In a two-player communication game, a maze solving task, and two image reconstruction tasks, we show that PLLB agents are not only able to learn more interpretable and generalizable behaviors, but can also share the learned rules with human users, enabling more effective human-AI coordination.
Create account to get full access
Overview
- Modern AI systems can perform superhuman tasks, but often lack human-like features such as generalization, interpretability, and the ability to interact effectively with humans.
- The paper introduces Policy Learning with a Language Bottleneck (PLLB), a framework that enables AI agents to generate linguistic rules that capture the strategies underlying their most rewarding behaviors.
- PLLB alternates between a rule generation step guided by language models and an update step where agents learn new policies guided by these rules.
- The authors show that PLLB agents can learn more interpretable and generalizable behaviors, and can share their learned rules with human users, enabling more effective human-AI coordination.
Plain English Explanation
The paper focuses on a common challenge in artificial intelligence (AI) - the gap between the superhuman performance of modern AI systems and their lack of human-like features. For example, self-driving cars and game-playing agents can outperform humans in specific tasks, but they often struggle with generalization, the ability to explain their decision-making, and working seamlessly with people.
To address this, the researchers developed a new framework called Policy Learning with a Language Bottleneck (PLLB). The key idea is to enable AI agents to generate linguistic rules that capture the strategies behind their most successful behaviors. This is inspired by the rich interplay between language and decision-making in humans.
PLLB works by alternating between two steps: a rule generation step guided by language models, and an update step where the agents learn new policies based on these rules. This allows the agents to learn behaviors that are more interpretable and generalizable, and also enables them to share their learned rules with human users, facilitating better coordination and cooperation between humans and AI.
The researchers tested PLLB in several tasks, including a two-player communication game, a maze-solving problem, and two image reconstruction challenges. The results show that PLLB agents not only perform well, but also develop more transparent and transferable strategies compared to traditional AI approaches.
Technical Explanation
The Policy Learning with a Language Bottleneck (PLLB) framework is designed to address the challenge of creating AI systems that can achieve superhuman performance while also exhibiting human-like features such as generalization, interpretability, and the ability to effectively interact with humans.
The key innovation in PLLB is the introduction of a language-based rule generation step, which is inspired by the tight coupling between language and decision-making in humans. During this step, the agents use language models to generate linguistic rules that capture the strategies underlying their most rewarding behaviors. These rules are then used to guide the agents' policy updates in the subsequent step.
By alternating between rule generation and policy update, PLLB agents are able to learn behaviors that are more interpretable and generalizable compared to traditional reinforcement learning approaches. The authors demonstrate the effectiveness of PLLB in a variety of tasks, including a two-player communication game, a maze-solving problem, and two image reconstruction challenges.
In the communication game, PLLB agents are able to develop shared linguistic protocols that enable more effective coordination with their partners. In the maze-solving and image reconstruction tasks, PLLB agents learn strategies that are not only successful, but can also be easily understood and adopted by human users.
Critical Analysis
The PLLB framework represents an important step towards bridging the gap between the impressive capabilities of modern AI systems and their lack of human-like features. By integrating language-based rule generation into the training process, the authors have shown that it is possible to create agents that are more interpretable and generalizable, while still maintaining high performance.
However, the paper does not address some potential limitations and areas for further research. For example, the language models used in the rule generation step are pre-trained and fixed, which may limit the agents' ability to fully optimize their linguistic strategies. Exploring more dynamic, interactive approaches to language-guided reinforcement learning could be a fruitful avenue for future work.
Additionally, the authors do not provide a deep analysis of the specific linguistic rules developed by the PLLB agents, nor do they investigate how these rules might be further refined or generalized for use in other domains. A more thorough examination of the learned rules and their properties could yield valuable insights into the decision-making processes of these agents.
Overall, the PLLB framework represents an important contribution to the field of AI, demonstrating the potential for language-based approaches to enhance the interpretability and human-AI interoperability of artificial agents. As the authors note, continued research in this direction could lead to more robust and versatile AI systems that can seamlessly collaborate with human users.
Conclusion
The Policy Learning with a Language Bottleneck (PLLB) framework introduced in this paper represents a promising approach for developing AI systems that can achieve superhuman performance while also exhibiting human-like features such as generalization, interpretability, and the ability to effectively interact with humans.
By incorporating a language-based rule generation step into the training process, PLLB agents are able to learn more transparent and transferable strategies, which can then be shared with human users to enable better coordination and cooperation. The authors demonstrate the effectiveness of this approach across a range of tasks, including communication, navigation, and image reconstruction.
While the paper highlights the potential of PLLB, it also identifies areas for further research, such as exploring more dynamic language-guided reinforcement learning and conducting deeper analyses of the learned linguistic rules. Continued work in this direction could lead to the development of AI systems that are not only highly capable, but also more aligned with human values and easier for people to understand and work with.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Large Language Models as Generalizable Policies for Embodied Tasks
Andrew Szot, Max Schwarzer, Harsh Agrawal, Bogdan Mazoure, Walter Talbott, Katherine Metcalf, Natalie Mackraz, Devon Hjelm, Alexander Toshev
0
0
We show that large language models (LLMs) can be adapted to be generalizable policies for embodied visual tasks. Our approach, called Large LAnguage model Reinforcement Learning Policy (LLaRP), adapts a pre-trained frozen LLM to take as input text instructions and visual egocentric observations and output actions directly in the environment. Using reinforcement learning, we train LLaRP to see and act solely through environmental interactions. We show that LLaRP is robust to complex paraphrasings of task instructions and can generalize to new tasks that require novel optimal behavior. In particular, on 1,000 unseen tasks it achieves 42% success rate, 1.7x the success rate of other common learned baselines or zero-shot applications of LLMs. Finally, to aid the community in studying language conditioned, massively multi-task, embodied AI problems we release a novel benchmark, Language Rearrangement, consisting of 150,000 training and 1,000 testing tasks for language-conditioned rearrangement. Video examples of LLaRP in unseen Language Rearrangement instructions are at https://llm-rl.github.io.
4/17/2024
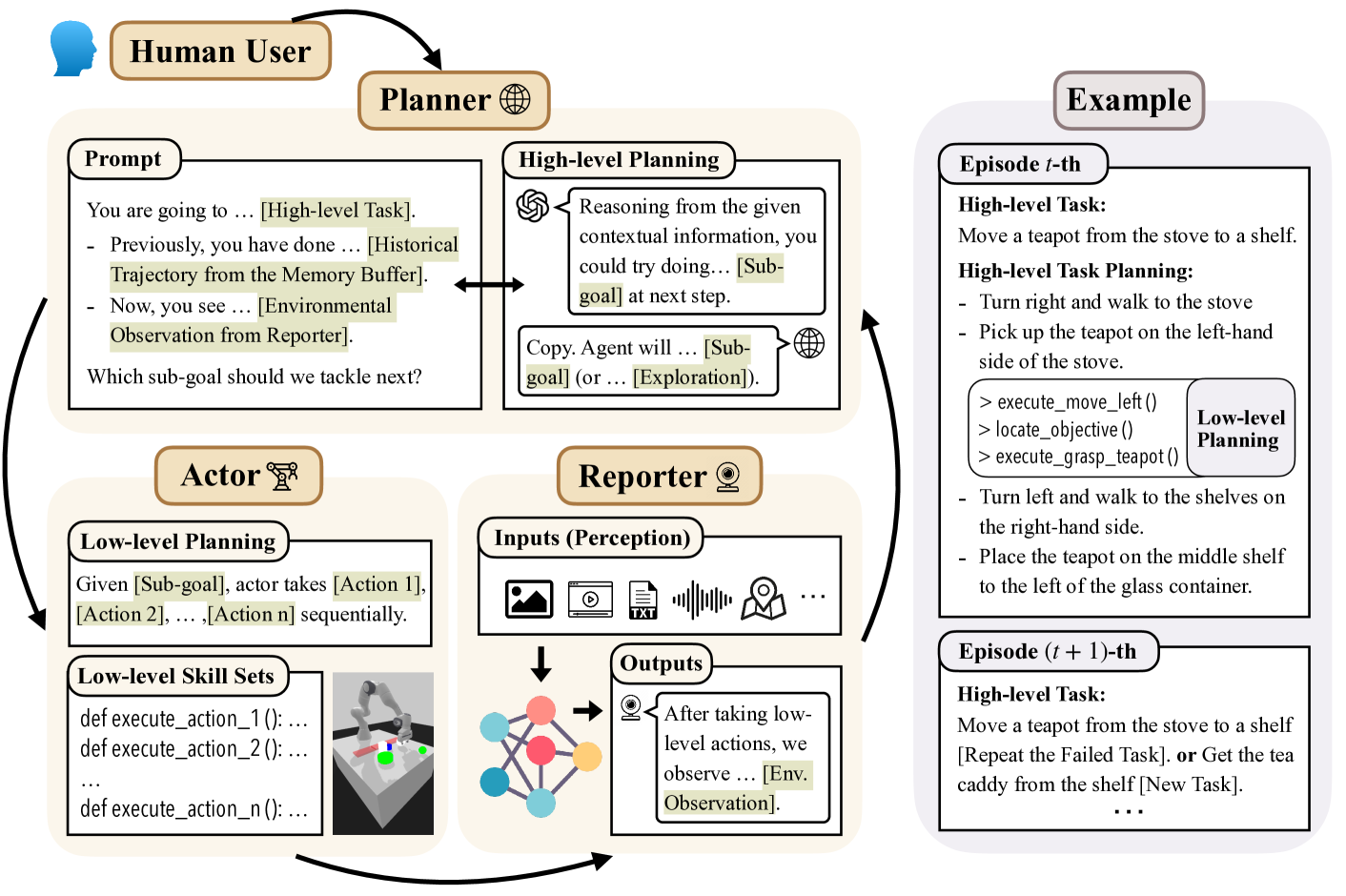
From Words to Actions: Unveiling the Theoretical Underpinnings of LLM-Driven Autonomous Systems
Jianliang He, Siyu Chen, Fengzhuo Zhang, Zhuoran Yang
0
0
In this work, from a theoretical lens, we aim to understand why large language model (LLM) empowered agents are able to solve decision-making problems in the physical world. To this end, consider a hierarchical reinforcement learning (RL) model where the LLM Planner and the Actor perform high-level task planning and low-level execution, respectively. Under this model, the LLM Planner navigates a partially observable Markov decision process (POMDP) by iteratively generating language-based subgoals via prompting. Under proper assumptions on the pretraining data, we prove that the pretrained LLM Planner effectively performs Bayesian aggregated imitation learning (BAIL) through in-context learning. Additionally, we highlight the necessity for exploration beyond the subgoals derived from BAIL by proving that naively executing the subgoals returned by LLM leads to a linear regret. As a remedy, we introduce an $epsilon$-greedy exploration strategy to BAIL, which is proven to incur sublinear regret when the pretraining error is small. Finally, we extend our theoretical framework to include scenarios where the LLM Planner serves as a world model for inferring the transition model of the environment and to multi-agent settings, enabling coordination among multiple Actors.
5/31/2024
💬
Large Language Model as a Policy Teacher for Training Reinforcement Learning Agents
Zihao Zhou, Bin Hu, Chenyang Zhao, Pu Zhang, Bin Liu
0
0
Recent studies have uncovered the potential of Large Language Models (LLMs) in addressing complex sequential decision-making tasks through the provision of high-level instructions. However, LLM-based agents lack specialization in tackling specific target problems, particularly in real-time dynamic environments. Additionally, deploying an LLM-based agent in practical scenarios can be both costly and time-consuming. On the other hand, reinforcement learning (RL) approaches train agents that specialize in the target task but often suffer from low sampling efficiency and high exploration costs. In this paper, we introduce a novel framework that addresses these challenges by training a smaller, specialized student RL agent using instructions from an LLM-based teacher agent. By incorporating the guidance from the teacher agent, the student agent can distill the prior knowledge of the LLM into its own model. Consequently, the student agent can be trained with significantly less data. Moreover, through further training with environment feedback, the student agent surpasses the capabilities of its teacher for completing the target task. We conducted experiments on challenging MiniGrid and Habitat environments, specifically designed for embodied AI research, to evaluate the effectiveness of our framework. The results clearly demonstrate that our approach achieves superior performance compared to strong baseline methods. Our code is available at https://github.com/ZJLAB-AMMI/LLM4Teach.
4/23/2024
Reinforcement Learning Problem Solving with Large Language Models
Sina Gholamian, Domingo Huh
0
0
Large Language Models (LLMs) encapsulate an extensive amount of world knowledge, and this has enabled their application in various domains to improve the performance of a variety of Natural Language Processing (NLP) tasks. This has also facilitated a more accessible paradigm of conversation-based interactions between humans and AI systems to solve intended problems. However, one interesting avenue that shows untapped potential is the use of LLMs as Reinforcement Learning (RL) agents to enable conversational RL problem solving. Therefore, in this study, we explore the concept of formulating Markov Decision Process-based RL problems as LLM prompting tasks. We demonstrate how LLMs can be iteratively prompted to learn and optimize policies for specific RL tasks. In addition, we leverage the introduced prompting technique for episode simulation and Q-Learning, facilitated by LLMs. We then show the practicality of our approach through two detailed case studies for Research Scientist and Legal Matter Intake workflows.
4/30/2024