Polynomial Regression as a Task for Understanding In-context Learning Through Finetuning and Alignment

0
Sign in to get full access
Overview
- The paper investigates the task of polynomial regression as a way to understand the capabilities of in-context learning through fine-tuning and alignment.
- It explores how well large language models can learn to perform polynomial regression tasks of varying complexity when fine-tuned or aligned on a small number of examples.
- The authors aim to gain insights into the strengths and limitations of in-context learning methods for this type of regression task.
Plain English Explanation
The paper looks at how well large language models, like GPT-3, can learn to do polynomial regression when provided with only a few examples. Polynomial regression is a type of mathematical modeling where the relationship between variables is represented by a polynomial function.
The researchers wanted to use this as a way to better understand the capabilities and limitations of "in-context learning" - the ability of these models to quickly learn new tasks by just seeing a few examples, without extensive fine-tuning or retraining. They tested how well the models could learn polynomials of varying complexity, from simple linear functions to more complex higher-order polynomials.
By examining how the models performed on this regression task, the authors hoped to gain insights that could help us better understand the context learning abilities of transformers and other large language models. This could inform how we use and develop these models for tasks that require quickly adapting to new situations based on limited information.
Technical Explanation
The paper evaluates the in-context learning capabilities of large language models on the task of polynomial regression. The authors fine-tune or align different models, including GPT-3, on small training sets of polynomial functions, then test their ability to accurately predict outputs for new inputs.
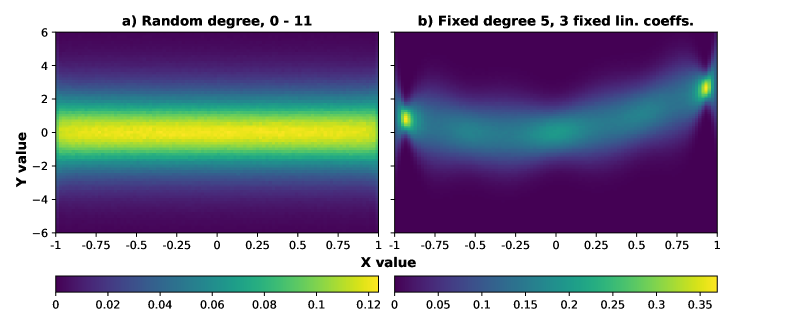
They experiment with polynomials of varying degrees, from simple linear functions up to 9th order polynomials, to assess how model performance scales with problem complexity. The models are evaluated on test sets of held-out polynomial functions.
The results show that the models can effectively learn to perform polynomial regression when provided with just a handful of training examples, with performance degrading as the polynomial degree increases. The authors also explore using different prompting strategies and analyze factors like sample complexity and model size that impact in-context learning for this task.
The insights from this work contribute to our understanding of how transformer-based models can learn from limited contextual information and highlight both the strengths and limitations of in-context learning approaches. This has implications for developing more robust and generalizable context learning abilities in large language models.
Critical Analysis
The paper provides a thoughtful exploration of in-context learning capabilities using polynomial regression as a testbed. However, the authors acknowledge several caveats and limitations to their work:
-
The experiments are limited to synthetic polynomial datasets, which may not fully capture the complexities of real-world regression tasks. Evaluating in-context learning on more diverse, natural datasets would be an important next step.
-
The models are only tested on a fixed set of polynomial degrees. Examining a broader spectrum of function complexities could yield additional insights.
-
The analysis focuses on regression performance, but does not explore other potential in-context learning capabilities, such as few-shot classification or generative tasks. Expanding the scope could reveal a more comprehensive understanding of these models' abilities.
Additionally, one could question whether polynomial regression is the most insightful task for studying in-context learning. While it provides a controlled environment, the underlying function structure may not fully capture the types of relationships large language models are designed to learn from natural language data.
Ultimately, this work represents a valuable contribution to the ongoing research on understanding the context learning mechanisms of transformer-based models. Building on these initial findings with further experimentation and analysis could lead to important advancements in this rapidly evolving field of AI.
Conclusion
This paper investigates the capabilities of large language models to perform in-context learning on the task of polynomial regression. The results demonstrate that these models can effectively learn to predict polynomial functions from just a few training examples, though their performance degrades as the complexity of the polynomials increases.
The insights gained from this work contribute to our broader understanding of the strengths and limitations of in-context learning approaches in transformer-based models. This knowledge can inform the development of more robust and generalizable context learning abilities, which will be crucial as these models are deployed for an expanding range of real-world applications.
While the paper is limited in scope to synthetic polynomial datasets, the general methodology and findings provide a solid foundation for further research into the context learning capabilities of large language models. Exploring more diverse tasks and datasets could uncover additional insights to advance the state of the art in this rapidly evolving field of AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Polynomial Regression as a Task for Understanding In-context Learning Through Finetuning and Alignment
Max Wilcoxson, Morten Svendg{aa}rd, Ria Doshi, Dylan Davis, Reya Vir, Anant Sahai
Simple function classes have emerged as toy problems to better understand in-context-learning in transformer-based architectures used for large language models. But previously proposed simple function classes like linear regression or multi-layer-perceptrons lack the structure required to explore things like prompting and alignment within models capable of in-context-learning. We propose univariate polynomial regression as a function class that is just rich enough to study prompting and alignment, while allowing us to visualize and understand what is going on clearly.
Read more7/30/2024

0
Towards Better Understanding of In-Context Learning Ability from In-Context Uncertainty Quantification
Shang Liu, Zhongze Cai, Guanting Chen, Xiaocheng Li
Predicting simple function classes has been widely used as a testbed for developing theory and understanding of the trained Transformer's in-context learning (ICL) ability. In this paper, we revisit the training of Transformers on linear regression tasks, and different from all the existing literature, we consider a bi-objective prediction task of predicting both the conditional expectation $mathbb{E}[Y|X]$ and the conditional variance Var$(Y|X)$. This additional uncertainty quantification objective provides a handle to (i) better design out-of-distribution experiments to distinguish ICL from in-weight learning (IWL) and (ii) make a better separation between the algorithms with and without using the prior information of the training distribution. Theoretically, we show that the trained Transformer reaches near Bayes-optimum, suggesting the usage of the information of the training distribution. Our method can be extended to other cases. Specifically, with the Transformer's context window $S$, we prove a generalization bound of $tilde{mathcal{O}}(sqrt{min{S, T}/(n T)})$ on $n$ tasks with sequences of length $T$, providing sharper analysis compared to previous results of $tilde{mathcal{O}}(sqrt{1/n})$. Empirically, we illustrate that while the trained Transformer behaves as the Bayes-optimal solution as a natural consequence of supervised training in distribution, it does not necessarily perform a Bayesian inference when facing task shifts, in contrast to the textit{equivalence} between these two proposed in many existing literature. We also demonstrate the trained Transformer's ICL ability over covariates shift and prompt-length shift and interpret them as a generalization over a meta distribution.
Read more5/27/2024
0
In-Context Learning with Representations: Contextual Generalization of Trained Transformers
Tong Yang, Yu Huang, Yingbin Liang, Yuejie Chi
In-context learning (ICL) refers to a remarkable capability of pretrained large language models, which can learn a new task given a few examples during inference. However, theoretical understanding of ICL is largely under-explored, particularly whether transformers can be trained to generalize to unseen examples in a prompt, which will require the model to acquire contextual knowledge of the prompt for generalization. This paper investigates the training dynamics of transformers by gradient descent through the lens of non-linear regression tasks. The contextual generalization here can be attained via learning the template function for each task in-context, where all template functions lie in a linear space with $m$ basis functions. We analyze the training dynamics of one-layer multi-head transformers to in-contextly predict unlabeled inputs given partially labeled prompts, where the labels contain Gaussian noise and the number of examples in each prompt are not sufficient to determine the template. Under mild assumptions, we show that the training loss for a one-layer multi-head transformer converges linearly to a global minimum. Moreover, the transformer effectively learns to perform ridge regression over the basis functions. To our knowledge, this study is the first provable demonstration that transformers can learn contextual (i.e., template) information to generalize to both unseen examples and tasks when prompts contain only a small number of query-answer pairs.
Read more9/27/2024
↗️
0
On regularized polynomial functional regression
Markus Holzleitner, Sergei Pereverzyev
This article offers a comprehensive treatment of polynomial functional regression, culminating in the establishment of a novel finite sample bound. This bound encompasses various aspects, including general smoothness conditions, capacity conditions, and regularization techniques. In doing so, it extends and generalizes several findings from the context of linear functional regression as well. We also provide numerical evidence that using higher order polynomial terms can lead to an improved performance.
Read more5/8/2024