Transformer In-Context Learning for Categorical Data

0

Sign in to get full access
Overview
- This paper presents a new approach called Transformer In-Context Learning for Categorical Data to address the challenge of learning from categorical data using transformers.
- The proposed method leverages attention-based meta-learning to enable transformers to effectively learn from categorical data, which is often more challenging than numerical data.
- The paper also explores the theoretical properties of this approach, including how it relates to other context learning techniques such as temporal difference learning and Bayesian approaches.
Plain English Explanation
Transformers are a type of machine learning model that has become very powerful for tasks like language processing. However, transformers can struggle when the data they're trained on is made up of categories or labels, rather than numbers. This paper introduces a new way to help transformers learn better from this kind of categorical data.
The key idea is to use a technique called attention-based meta-learning. This allows the transformer to "learn how to learn" from the categorical data, by paying attention to the important patterns and relationships in the data. It's kind of like how humans can get better at recognizing different types of animals or objects the more examples they see.
The paper also explores the mathematical properties of this approach, and how it connects to other ways of helping models learn from context, like reinforcement learning and Bayesian modeling. By understanding these connections, the researchers hope to shed light on how transformers and other AI models can become more effective at learning from the kinds of messy, real-world data we encounter in many applications.
Technical Explanation
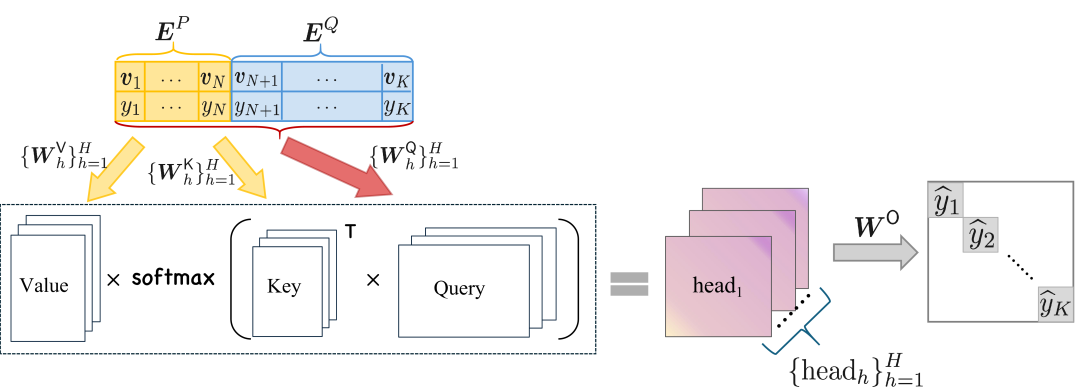
The paper introduces a new approach called Transformer In-Context Learning for Categorical Data (TICL) that enables transformers to effectively learn from categorical data. The key innovation is the use of attention-based meta-learning, which allows the transformer to dynamically adapt its internal representations to better capture the relevant patterns and relationships in the categorical data.
Specifically, the TICL model consists of a transformer encoder that takes in the categorical input data, and an attention-based meta-learning module that learns to produce a set of attention weights. These attention weights guide the transformer's learning process, helping it focus on the most informative parts of the input.
The paper also provides a theoretical analysis of TICL, drawing connections to other context learning techniques like temporal difference learning and Bayesian approaches. This analysis sheds light on the properties of TICL, such as how it can learn to extract useful context from the input data and how it relates to other state-of-the-art methods for learning from categorical data.
Critical Analysis
The TICL approach presented in this paper is a promising step towards enabling transformers to effectively learn from categorical data. The use of attention-based meta-learning is a novel and insightful idea that could have broader applicability beyond just transformers.
However, the paper does note some limitations of the current TICL model. For example, the performance of TICL may be sensitive to the specific architecture and hyperparameters used, and further research is needed to fully understand its theoretical properties and how it compares to other context learning techniques.
Additionally, the experiments in the paper are conducted on relatively simple datasets, and it would be valuable to see how TICL performs on more complex, real-world categorical datasets. There may also be opportunities to further improve the TICL approach, such as by incorporating additional inductive biases or exploring hybrid models that combine TICL with other learning techniques.
Overall, this paper represents an important contribution to the field of machine learning, particularly in the area of context learning and the challenge of working with categorical data. The TICL approach is a promising direction, and the theoretical analysis provides valuable insights that could inspire future research in this area.
Conclusion
This paper presents a new approach called Transformer In-Context Learning for Categorical Data (TICL) that enables transformers to effectively learn from categorical data. TICL leverages attention-based meta-learning to help transformers adapt their internal representations to better capture the relevant patterns and relationships in categorical data.
The paper also provides a thorough theoretical analysis of TICL, exploring its connections to other context learning techniques like temporal difference learning and Bayesian approaches. This analysis sheds light on the properties of TICL and how it relates to state-of-the-art methods for learning from categorical data.
While the TICL approach shows promise, the paper also notes some limitations and areas for further research. Exploring TICL's performance on more complex, real-world datasets and investigating ways to further improve the approach could lead to valuable advancements in the field of machine learning and its ability to work with diverse types of data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Transformer In-Context Learning for Categorical Data
Aaron T. Wang, Ricardo Henao, Lawrence Carin
Recent research has sought to understand Transformers through the lens of in-context learning with functional data. We extend that line of work with the goal of moving closer to language models, considering categorical outcomes, nonlinear underlying models, and nonlinear attention. The contextual data are of the form $textsf{C}=(x_1,c_1,dots,x_N,c_{N})$ where each $c_iin{0,dots,C-1}$ is drawn from a categorical distribution that depends on covariates $x_iinmathbb{R}^d$. Contextual outcomes in the $m$th set of contextual data, $textsf{C}_m$, are modeled in terms of latent function $f_m(x)intextsf{F}$, where $textsf{F}$ is a functional class with $(C-1)$-dimensional vector output. The probability of observing class $cin{0,dots,C-1}$ is modeled in terms of the output components of $f_m(x)$ via the softmax. The Transformer parameters may be trained with $M$ contextual examples, ${textsf{C}_m}_{m=1,M}$, and the trained model is then applied to new contextual data $textsf{C}_{M+1}$ for new $f_{M+1}(x)intextsf{F}$. The goal is for the Transformer to constitute the probability of each category $cin{0,dots,C-1}$ for a new query $x_{N_{M+1}+1}$. We assume each component of $f_m(x)$ resides in a reproducing kernel Hilbert space (RKHS), specifying $textsf{F}$. Analysis and an extensive set of experiments suggest that on its forward pass the Transformer (with attention defined by the RKHS kernel) implements a form of gradient descent of the underlying function, connected to the latent vector function associated with the softmax. We present what is believed to be the first real-world demonstration of this few-shot-learning methodology, using the ImageNet dataset.
Read more5/28/2024
0
In-Context Learning with Representations: Contextual Generalization of Trained Transformers
Tong Yang, Yu Huang, Yingbin Liang, Yuejie Chi
In-context learning (ICL) refers to a remarkable capability of pretrained large language models, which can learn a new task given a few examples during inference. However, theoretical understanding of ICL is largely under-explored, particularly whether transformers can be trained to generalize to unseen examples in a prompt, which will require the model to acquire contextual knowledge of the prompt for generalization. This paper investigates the training dynamics of transformers by gradient descent through the lens of non-linear regression tasks. The contextual generalization here can be attained via learning the template function for each task in-context, where all template functions lie in a linear space with $m$ basis functions. We analyze the training dynamics of one-layer multi-head transformers to in-contextly predict unlabeled inputs given partially labeled prompts, where the labels contain Gaussian noise and the number of examples in each prompt are not sufficient to determine the template. Under mild assumptions, we show that the training loss for a one-layer multi-head transformer converges linearly to a global minimum. Moreover, the transformer effectively learns to perform ridge regression over the basis functions. To our knowledge, this study is the first provable demonstration that transformers can learn contextual (i.e., template) information to generalize to both unseen examples and tasks when prompts contain only a small number of query-answer pairs.
Read more8/21/2024
↗️
0
Transformers are Universal In-context Learners
Takashi Furuya, Maarten V. de Hoop, Gabriel Peyr'e
Transformers are deep architectures that define in-context mappings which enable predicting new tokens based on a given set of tokens (such as a prompt in NLP applications or a set of patches for vision transformers). This work studies in particular the ability of these architectures to handle an arbitrarily large number of context tokens. To mathematically and uniformly address the expressivity of these architectures, we consider the case that the mappings are conditioned on a context represented by a probability distribution of tokens (discrete for a finite number of tokens). The related notion of smoothness corresponds to continuity in terms of the Wasserstein distance between these contexts. We demonstrate that deep transformers are universal and can approximate continuous in-context mappings to arbitrary precision, uniformly over compact token domains. A key aspect of our results, compared to existing findings, is that for a fixed precision, a single transformer can operate on an arbitrary (even infinite) number of tokens. Additionally, it operates with a fixed embedding dimension of tokens (this dimension does not increase with precision) and a fixed number of heads (proportional to the dimension). The use of MLP layers between multi-head attention layers is also explicitly controlled.
Read more8/6/2024

0
Transformers are Minimax Optimal Nonparametric In-Context Learners
Juno Kim, Tai Nakamaki, Taiji Suzuki
In-context learning (ICL) of large language models has proven to be a surprisingly effective method of learning a new task from only a few demonstrative examples. In this paper, we study the efficacy of ICL from the viewpoint of statistical learning theory. We develop approximation and generalization error bounds for a transformer composed of a deep neural network and one linear attention layer, pretrained on nonparametric regression tasks sampled from general function spaces including the Besov space and piecewise $gamma$-smooth class. We show that sufficiently trained transformers can achieve -- and even improve upon -- the minimax optimal estimation risk in context by encoding the most relevant basis representations during pretraining. Our analysis extends to high-dimensional or sequential data and distinguishes the emph{pretraining} and emph{in-context} generalization gaps. Furthermore, we establish information-theoretic lower bounds for meta-learners w.r.t. both the number of tasks and in-context examples. These findings shed light on the roles of task diversity and representation learning for ICL.
Read more8/23/2024