PolyRouter: A Multi-LLM Querying System

0
Sign in to get full access
Overview
- PolyRouter is a multi-LLM querying system that aims to efficiently leverage the capabilities of multiple large language models (LLMs) to answer user queries.
- The system dynamically routes queries to the most appropriate LLM based on the query's characteristics and the models' strengths.
- PolyRouter is designed to provide high-quality responses while optimizing for cost and resource efficiency.
Plain English Explanation
PolyRouter is a tool that helps users get answers to their questions by using multiple large language models. Large language models are AI systems that can understand and generate human-like text. PolyRouter knows the strengths and weaknesses of different language models, and it can automatically send each question to the model that is best suited to answer it. This helps users get high-quality responses, while also being cost-effective and efficient.
For example, if a user asks a question about the latest scientific research, PolyRouter might send that question to a language model that has been trained on a lot of academic papers. But if the user asks about current events, PolyRouter might send that to a model that is better at understanding and discussing recent news. By dynamically routing the questions, PolyRouter can make the most of the different language models' capabilities.
Technical Explanation
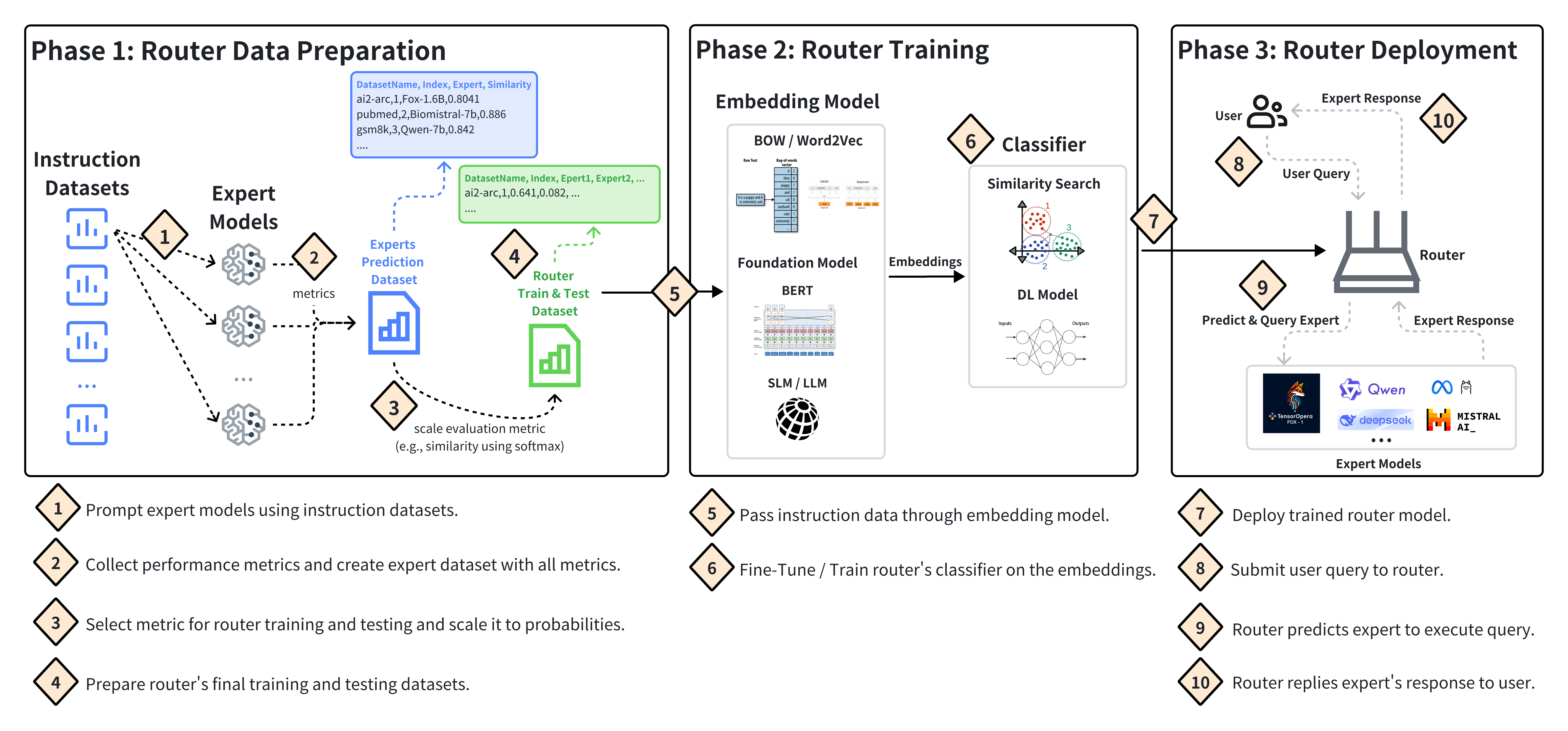
PolyRouter is designed as a modular system that can integrate multiple large language models and dynamically route queries to the most appropriate one. The system first classifies the user's query to determine its characteristics, such as the topic, complexity, and required level of factual accuracy. It then uses a learned routing policy to select the LLM that is best suited to provide a high-quality response for that particular query.
The routing policy is trained using reinforcement learning on a large corpus of user queries and ground-truth responses. The model learns to optimize for both response quality and cost-efficiency, taking into account factors like the latency and compute requirements of each LLM.
PolyRouter also incorporates techniques to further improve the efficiency of LLM inference, such as model parallelism and hybrid LLM architectures. By intelligently combining the strengths of multiple LLMs, PolyRouter aims to provide users with high-quality and cost-effective responses to a wide range of queries.
Critical Analysis
The paper provides a compelling vision for PolyRouter as a system that can efficiently leverage the capabilities of multiple language models. The use of a learned routing policy to dynamically select the most appropriate LLM is a promising approach, as it allows the system to adapt to the specific characteristics of each query.
However, the paper does not delve into the details of the routing policy's training process or the specific techniques used for model parallelism and hybrid LLM architectures. Additional information on the system's implementation and evaluation would be helpful to fully assess its capabilities and potential limitations.
Furthermore, the paper does not address potential challenges related to the interpretability and transparency of the routing decisions made by PolyRouter. As users increasingly rely on AI systems to provide information and recommendations, it will be important for these systems to be able to explain their decision-making process in a clear and understandable way.
Conclusion
PolyRouter presents an innovative approach to leveraging the strengths of multiple large language models to provide high-quality and cost-effective responses to user queries. By dynamically routing queries to the most suitable LLM, the system has the potential to deliver significant improvements in both response quality and efficiency.
As the field of natural language processing continues to rapidly evolve, systems like PolyRouter will play an increasingly important role in enabling users to access the wealth of knowledge and capabilities offered by large language models. Further research and development in this area could lead to even more advanced and user-friendly AI-powered query-answering systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PolyRouter: A Multi-LLM Querying System
Dimitris Stripelis, Zijian Hu, Jipeng Zhang, Zhaozhuo Xu, Alay Dilipbhai Shah, Han Jin, Yuhang Yao, Salman Avestimehr, Chaoyang He
With the rapid growth of Large Language Models (LLMs) across various domains, numerous new LLMs have emerged, each possessing domain-specific expertise. This proliferation has highlighted the need for quick, high-quality, and cost-effective LLM query response methods. Yet, no single LLM exists to efficiently balance this trilemma. Some models are powerful but extremely costly, while others are fast and inexpensive but qualitatively inferior. To address this challenge, we present PolyRouter, a non-monolithic LLM querying system that seamlessly integrates various LLM experts into a single query interface and dynamically routes incoming queries to the most high-performant expert based on query's requirements. Through extensive experiments, we demonstrate that when compared to standalone expert models, PolyRouter improves query efficiency by up to 40%, and leads to significant cost reductions of up to 30%, while maintaining or enhancing model performance by up to 10%.
Read more8/28/2024
💬
0
Expert Router: Orchestrating Efficient Language Model Inference through Prompt Classification
Josef Pichlmeier, Philipp Ross, Andre Luckow
Large Language Models (LLMs) have experienced widespread adoption across scientific and industrial domains due to their versatility and utility for diverse tasks. Nevertheless, deploying and serving these models at scale with optimal throughput and latency remains a significant challenge, primarily because of the high computational and memory demands associated with LLMs. To tackle this limitation, we introduce Expert Router, a system designed to orchestrate multiple expert models efficiently, thereby enhancing scalability. Expert Router is a parallel inference system with a central routing gateway that distributes incoming requests using a clustering method. This approach effectively partitions incoming requests among available LLMs, maximizing overall throughput. Our extensive evaluations encompassed up to 1,000 concurrent users, providing comprehensive insights into the system's behavior from user and infrastructure perspectives. The results demonstrate Expert Router's effectiveness in handling high-load scenarios and achieving higher throughput rates, particularly under many concurrent users.
Read more4/24/2024
🛸
0
Hybrid LLM: Cost-Efficient and Quality-Aware Query Routing
Dujian Ding, Ankur Mallick, Chi Wang, Robert Sim, Subhabrata Mukherjee, Victor Ruhle, Laks V. S. Lakshmanan, Ahmed Hassan Awadallah
Large language models (LLMs) excel in most NLP tasks but also require expensive cloud servers for deployment due to their size, while smaller models that can be deployed on lower cost (e.g., edge) devices, tend to lag behind in terms of response quality. Therefore in this work we propose a hybrid inference approach which combines their respective strengths to save cost and maintain quality. Our approach uses a router that assigns queries to the small or large model based on the predicted query difficulty and the desired quality level. The desired quality level can be tuned dynamically at test time to seamlessly trade quality for cost as per the scenario requirements. In experiments our approach allows us to make up to 40% fewer calls to the large model, with no drop in response quality.
Read more4/24/2024

0
RouteLLM: Learning to Route LLMs with Preference Data
Isaac Ong, Amjad Almahairi, Vincent Wu, Wei-Lin Chiang, Tianhao Wu, Joseph E. Gonzalez, M Waleed Kadous, Ion Stoica
Large language models (LLMs) exhibit impressive capabilities across a wide range of tasks, yet the choice of which model to use often involves a trade-off between performance and cost. More powerful models, though effective, come with higher expenses, while less capable models are more cost-effective. To address this dilemma, we propose several efficient router models that dynamically select between a stronger and a weaker LLM during inference, aiming to optimize the balance between cost and response quality. We develop a training framework for these routers leveraging human preference data and data augmentation techniques to enhance performance. Our evaluation on widely-recognized benchmarks shows that our approach significantly reduces costs-by over 2 times in certain cases-without compromising the quality of responses. Interestingly, our router models also demonstrate significant transfer learning capabilities, maintaining their performance even when the strong and weak models are changed at test time. This highlights the potential of these routers to provide a cost-effective yet high-performance solution for deploying LLMs.
Read more7/23/2024