Pose Priors from Language Models

0
💬
Sign in to get full access
Overview
- This paper presents a zero-shot pose optimization method that enforces accurate physical contact constraints when estimating the 3D pose of humans.
- The key insight is that since language is often used to describe physical interaction, large pretrained text-based models can act as priors on pose estimation.
- The method converts natural language descriptors, generated by a large multimodal model (LMM), into tractable losses to constrain the 3D pose optimization.
- Despite its simplicity, the method produces compelling pose reconstructions of people in close contact, correctly capturing the semantics of the social and physical interactions.
Plain English Explanation
The paper describes a new way to estimate the 3D poses (positions and orientations) of people in images or videos, particularly when they are in close physical contact with each other. The researchers realized that when people describe physical interactions, they often use language that could provide useful information for estimating the 3D poses.
For example, if someone says "The two people are shaking hands," that linguistic information could help the pose estimation algorithm understand that the hands of the two people should be in contact. The researchers developed a method that takes the natural language descriptions and converts them into mathematical constraints that the pose estimation algorithm can use to produce more accurate 3D pose estimates, especially in cases of physical contact between people.
Interestingly, this approach is simpler and more flexible than previous methods that required expensive human annotation of contact points and training specialized models. The researchers' approach provides a unified framework for resolving both self-contact (e.g., someone crossing their arms) and person-to-person contact.
Technical Explanation
The core of the researchers' approach is to leverage the insights encoded in large, pretrained language models (LLMs) to act as priors for 3D pose estimation. These LLMs have been trained on vast amounts of text data and can capture the semantics of physical interactions as expressed in natural language.
The method works by first generating natural language descriptions of the physical interactions in an image or video using a large multimodal model (LMM). These descriptions are then converted into differentiable losses that can be used to constrain the 3D pose optimization process. This allows the pose estimation to be guided by the linguistic information, resulting in reconstructions that better capture the semantics of the social and physical interactions.
The researchers demonstrate that their zero-shot approach rivals more complex state-of-the-art methods that require expensive human annotation of contact points and training of specialized models. Moreover, the unified framework provided by this method can handle both self-contact and person-to-person contact, overcoming limitations of previous approaches.
Critical Analysis
The researchers provide a compelling approach that leverages the power of large language models to improve 3D pose estimation, particularly in cases of physical interaction. By converting natural language descriptions into optimization constraints, the method is able to capture the semantics of the interactions in a flexible and data-efficient manner.
However, the paper does not address the potential limitations of using language models as priors. While these models can capture rich semantic information, they may also encode biases or fail to generalize to novel interaction types not well represented in the training data. Additionally, the paper does not discuss the computational overhead of generating and integrating the language-based losses into the pose optimization process.
Further research could explore ways to better quantify the uncertainty in the pose estimates produced by this method, as well as investigate strategies for combining the language-based priors with other sources of information, such as visual cues or motion patterns, to further enhance the accuracy and robustness of the 3D pose reconstructions.
Conclusion
This paper presents a novel zero-shot pose optimization method that leverages the semantic insights encoded in large language models to improve 3D pose estimation, particularly in cases of physical interaction between people. By converting natural language descriptions into optimization constraints, the method is able to capture the semantics of the interactions in a flexible and data-efficient manner, outperforming more complex approaches that require expensive human annotation.
While the method shows promising results, further research is needed to address potential limitations, such as the impact of language model biases and the computational overhead of the language-based optimization. Exploring ways to better quantify uncertainty and combine the language-based priors with other sources of information could lead to even more robust and accurate 3D pose estimation capabilities, with applications ranging from human-computer interaction to sports analytics and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Pose Priors from Language Models
Sanjay Subramanian, Evonne Ng, Lea Muller, Dan Klein, Shiry Ginosar, Trevor Darrell
We present a zero-shot pose optimization method that enforces accurate physical contact constraints when estimating the 3D pose of humans. Our central insight is that since language is often used to describe physical interaction, large pretrained text-based models can act as priors on pose estimation. We can thus leverage this insight to improve pose estimation by converting natural language descriptors, generated by a large multimodal model (LMM), into tractable losses to constrain the 3D pose optimization. Despite its simplicity, our method produces surprisingly compelling pose reconstructions of people in close contact, correctly capturing the semantics of the social and physical interactions. We demonstrate that our method rivals more complex state-of-the-art approaches that require expensive human annotation of contact points and training specialized models. Moreover, unlike previous approaches, our method provides a unified framework for resolving self-contact and person-to-person contact.
Read more5/7/2024
🧠
0
ContactArt: Learning 3D Interaction Priors for Category-level Articulated Object and Hand Poses Estimation
Zehao Zhu, Jiashun Wang, Yuzhe Qin, Deqing Sun, Varun Jampani, Xiaolong Wang
We propose a new dataset and a novel approach to learning hand-object interaction priors for hand and articulated object pose estimation. We first collect a dataset using visual teleoperation, where the human operator can directly play within a physical simulator to manipulate the articulated objects. We record the data and obtain free and accurate annotations on object poses and contact information from the simulator. Our system only requires an iPhone to record human hand motion, which can be easily scaled up and largely lower the costs of data and annotation collection. With this data, we learn 3D interaction priors including a discriminator (in a GAN) capturing the distribution of how object parts are arranged, and a diffusion model which generates the contact regions on articulated objects, guiding the hand pose estimation. Such structural and contact priors can easily transfer to real-world data with barely any domain gap. By using our data and learned priors, our method significantly improves the performance on joint hand and articulated object poses estimation over the existing state-of-the-art methods. The project is available at https://zehaozhu.github.io/ContactArt/ .
Read more7/30/2024
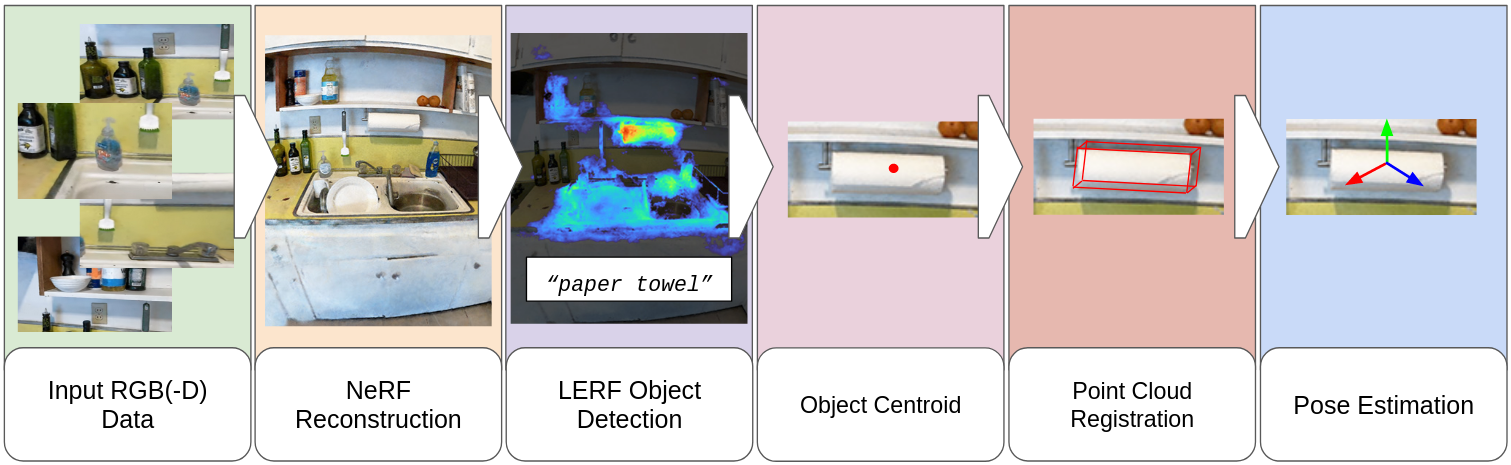
0
From Words to Poses: Enhancing Novel Object Pose Estimation with Vision Language Models
Tessa Pulli, Stefan Thalhammer, Simon Schwaiger, Markus Vincze
Robots are increasingly envisioned to interact in real-world scenarios, where they must continuously adapt to new situations. To detect and grasp novel objects, zero-shot pose estimators determine poses without prior knowledge. Recently, vision language models (VLMs) have shown considerable advances in robotics applications by establishing an understanding between language input and image input. In our work, we take advantage of VLMs zero-shot capabilities and translate this ability to 6D object pose estimation. We propose a novel framework for promptable zero-shot 6D object pose estimation using language embeddings. The idea is to derive a coarse location of an object based on the relevancy map of a language-embedded NeRF reconstruction and to compute the pose estimate with a point cloud registration method. Additionally, we provide an analysis of LERF's suitability for open-set object pose estimation. We examine hyperparameters, such as activation thresholds for relevancy maps and investigate the zero-shot capabilities on an instance- and category-level. Furthermore, we plan to conduct robotic grasping experiments in a real-world setting.
Read more9/10/2024

0
AvatarPose: Avatar-guided 3D Pose Estimation of Close Human Interaction from Sparse Multi-view Videos
Feichi Lu, Zijian Dong, Jie Song, Otmar Hilliges
Despite progress in human motion capture, existing multi-view methods often face challenges in estimating the 3D pose and shape of multiple closely interacting people. This difficulty arises from reliance on accurate 2D joint estimations, which are hard to obtain due to occlusions and body contact when people are in close interaction. To address this, we propose a novel method leveraging the personalized implicit neural avatar of each individual as a prior, which significantly improves the robustness and precision of this challenging pose estimation task. Concretely, the avatars are efficiently reconstructed via layered volume rendering from sparse multi-view videos. The reconstructed avatar prior allows for the direct optimization of 3D poses based on color and silhouette rendering loss, bypassing the issues associated with noisy 2D detections. To handle interpenetration, we propose a collision loss on the overlapping shape regions of avatars to add penetration constraints. Moreover, both 3D poses and avatars are optimized in an alternating manner. Our experimental results demonstrate state-of-the-art performance on several public datasets.
Read more8/21/2024