Position Paper: An Inner Interpretability Framework for AI Inspired by Lessons from Cognitive Neuroscience

0

Sign in to get full access
Overview
- This paper proposes a new framework for improving the interpretability of AI systems, called "Position," which takes inspiration from cognitive neuroscience.
- The framework aims to make AI systems more transparent and easier to understand by mapping the internal representations and decision-making processes of the AI to corresponding structures and functions in the human brain.
- The authors argue that this approach can lead to more robust and trustworthy AI systems that are better aligned with human values and cognition.
Plain English Explanation
This paper suggests a new way to make AI systems more interpretable and understandable. The key idea is to design AI systems that work more like the human brain. By mapping the internal workings of the AI to the structure and function of the human brain, the researchers believe they can create AI that is more transparent and aligned with human values and thinking.
The human brain is incredibly complex, but scientists have learned a lot about how it processes information and makes decisions. The authors of this paper propose taking inspiration from this cognitive neuroscience research to develop a new "Position" framework for AI interpretability. The goal is to make it easier to understand how AI systems arrive at their outputs, similar to how we can study the neural activity in the brain to understand human decision-making.
This approach could lead to AI systems that are more robust and trustworthy. If an AI's inner workings map closely to the human brain, it may behave in ways that are more intuitive and aligned with human values. This could help address concerns about the safety and reliability of AI as it becomes more advanced and influential in our lives.
Technical Explanation
The core of the "Position" framework is the idea of mapping the internal representations and decision-making processes of an AI system to corresponding structures and functions in the human brain. This "thermodynamics-inspired" approach aims to create AI that is more mechanistically interpretable, meaning we can better understand how it works at a fundamental level.
The authors draw insights from cognitive neuroscience research to identify key principles that could be applied to AI design. For example, the brain's use of distributed and hierarchical processing, the importance of context and spatial representations, and the role of different neurotransmitters in modulating cognition. They use a case study on interpreting AI for planning to illustrate how the Position framework could be implemented.
By aligning the AI's internal structure and dynamics with our scientific understanding of the brain, the authors argue that we can develop systems that are more transparent, reliable, and aligned with human values. This could lead to significant advances in explainable human-AI interaction and AI safety.
Critical Analysis
The Position framework is an ambitious and novel approach to AI interpretability that draws inspiration from a deep well of cognitive neuroscience research. The authors make a compelling case that better aligning AI with human brain function could lead to more trustworthy and understandable systems.
However, the paper acknowledges several challenges and limitations in implementing this framework. Accurately mapping the complexity of the brain to AI systems is an enormously difficult task, and the authors note that our current understanding of the brain is still quite limited in many areas. There are also open questions about how to best translate neuroscientific principles into practical AI design choices.
Additionally, the framework may face obstacles in scaling to larger, more complex AI systems. The authors suggest that the Position approach could be most applicable to narrow, specialized AI applications rather than general-purpose models.
Despite these caveats, the Position framework represents an intriguing new direction for AI interpretability research. By drawing on insights from cognitive science, the authors aim to develop AI systems that are not just black boxes, but that have an inner logic and structure that is legible and aligned with human intelligence. Further research and experimentation will be needed to fully evaluate the potential of this approach.
Conclusion
This paper presents a novel "Position" framework for improving the interpretability of AI systems by drawing inspiration from cognitive neuroscience. The core idea is to map the internal representations and decision-making processes of AI to corresponding structures and functions in the human brain.
The authors argue that this approach can lead to more transparent, reliable, and human-aligned AI systems. While significant challenges remain in accurately translating neuroscientific principles into AI design, the Position framework represents an intriguing new direction for the field of AI interpretability. Further research in this area could yield important insights and advances in explainable AI and AI safety.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Position Paper: An Inner Interpretability Framework for AI Inspired by Lessons from Cognitive Neuroscience
Martina G. Vilas, Federico Adolfi, David Poeppel, Gemma Roig
Inner Interpretability is a promising emerging field tasked with uncovering the inner mechanisms of AI systems, though how to develop these mechanistic theories is still much debated. Moreover, recent critiques raise issues that question its usefulness to advance the broader goals of AI. However, it has been overlooked that these issues resemble those that have been grappled with in another field: Cognitive Neuroscience. Here we draw the relevant connections and highlight lessons that can be transferred productively between fields. Based on these, we propose a general conceptual framework and give concrete methodological strategies for building mechanistic explanations in AI inner interpretability research. With this conceptual framework, Inner Interpretability can fend off critiques and position itself on a productive path to explain AI systems.
Read more8/1/2024
🗣️
0
The Cognitive Revolution in Interpretability: From Explaining Behavior to Interpreting Representations and Algorithms
Adam Davies, Ashkan Khakzar
Artificial neural networks have long been understood as black boxes: though we know their computation graphs and learned parameters, the knowledge encoded by these weights and functions they perform are not inherently interpretable. As such, from the early days of deep learning, there have been efforts to explain these models' behavior and understand them internally; and recently, mechanistic interpretability (MI) has emerged as a distinct research area studying the features and implicit algorithms learned by foundation models such as large language models. In this work, we aim to ground MI in the context of cognitive science, which has long struggled with analogous questions in studying and explaining the behavior of black box intelligent systems like the human brain. We leverage several important ideas and developments in the history of cognitive science to disentangle divergent objectives in MI and indicate a clear path forward. First, we argue that current methods are ripe to facilitate a transition in deep learning interpretation echoing the cognitive revolution in 20th-century psychology that shifted the study of human psychology from pure behaviorism toward mental representations and processing. Second, we propose a taxonomy mirroring key parallels in computational neuroscience to describe two broad categories of MI research, semantic interpretation (what latent representations are learned and used) and algorithmic interpretation (what operations are performed over representations) to elucidate their divergent goals and objects of study. Finally, we elaborate the parallels and distinctions between various approaches in both categories, analyze the respective strengths and weaknesses of representative works, clarify underlying assumptions, outline key challenges, and discuss the possibility of unifying these modes of interpretation under a common framework.
Read more8/13/2024
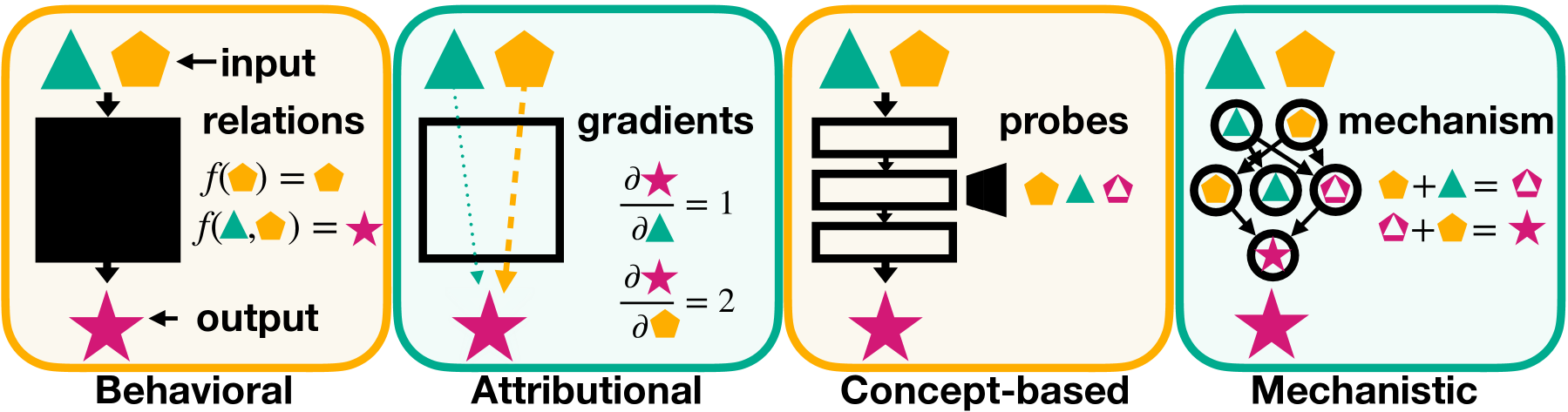
0
Mechanistic Interpretability for AI Safety -- A Review
Leonard Bereska, Efstratios Gavves
Understanding AI systems' inner workings is critical for ensuring value alignment and safety. This review explores mechanistic interpretability: reverse engineering the computational mechanisms and representations learned by neural networks into human-understandable algorithms and concepts to provide a granular, causal understanding. We establish foundational concepts such as features encoding knowledge within neural activations and hypotheses about their representation and computation. We survey methodologies for causally dissecting model behaviors and assess the relevance of mechanistic interpretability to AI safety. We examine benefits in understanding, control, alignment, and risks such as capability gains and dual-use concerns. We investigate challenges surrounding scalability, automation, and comprehensive interpretation. We advocate for clarifying concepts, setting standards, and scaling techniques to handle complex models and behaviors and expand to domains such as vision and reinforcement learning. Mechanistic interpretability could help prevent catastrophic outcomes as AI systems become more powerful and inscrutable.
Read more8/27/2024

0
Multilevel Interpretability Of Artificial Neural Networks: Leveraging Framework And Methods From Neuroscience
Zhonghao He, Jascha Achterberg, Katie Collins, Kevin Nejad, Danyal Akarca, Yinzhu Yang, Wes Gurnee, Ilia Sucholutsky, Yuhan Tang, Rebeca Ianov, George Ogden, Chole Li, Kai Sandbrink, Stephen Casper, Anna Ivanova, Grace W. Lindsay
As deep learning systems are scaled up to many billions of parameters, relating their internal structure to external behaviors becomes very challenging. Although daunting, this problem is not new: Neuroscientists and cognitive scientists have accumulated decades of experience analyzing a particularly complex system - the brain. In this work, we argue that interpreting both biological and artificial neural systems requires analyzing those systems at multiple levels of analysis, with different analytic tools for each level. We first lay out a joint grand challenge among scientists who study the brain and who study artificial neural networks: understanding how distributed neural mechanisms give rise to complex cognition and behavior. We then present a series of analytical tools that can be used to analyze biological and artificial neural systems, organizing those tools according to Marr's three levels of analysis: computation/behavior, algorithm/representation, and implementation. Overall, the multilevel interpretability framework provides a principled way to tackle neural system complexity; links structure, computation, and behavior; clarifies assumptions and research priorities at each level; and paves the way toward a unified effort for understanding intelligent systems, may they be biological or artificial.
Read more8/27/2024