TS-RSR: A provably efficient approach for batch bayesian optimization

0

Sign in to get full access
Overview
• This paper introduces a new algorithm called "Minimizing the Thompson Sampling Regret-to-Sigma Ratio (TS-RSR)" for batch Bayesian Optimization (BO) that aims to improve the regret-to-sigma ratio, a measure of the algorithm's efficiency.
• The TS-RSR algorithm is designed to be provably efficient, meaning it has theoretical guarantees on its performance.
• Bayesian Optimization is a powerful technique for optimizing expensive black-box functions, with applications in areas like hyperparameter tuning and reinforcement learning.
Plain English Explanation
The paper presents a new algorithm for a problem called Bayesian Optimization. Bayesian Optimization is a way to find the best setting of a black-box function - a function where you can't see how it works inside, you just know how to evaluate it. This is useful in many machine learning and engineering problems, like tuning the hyperparameters of a machine learning model or optimizing the design of a new product.
The key idea behind the TS-RSR algorithm is to minimize the "regret-to-sigma ratio" - a measure of how efficiently the algorithm is able to find the best setting of the function. The algorithm uses a technique called Thompson Sampling, which involves taking random guesses at the best setting and then learning from the results. The paper shows that this TS-RSR algorithm has strong theoretical guarantees, meaning we can prove that it will perform well.
Technical Explanation
The paper introduces a new algorithm called "Minimizing the Thompson Sampling Regret-to-Sigma Ratio (TS-RSR)" for batch Bayesian Optimization (BO). Bayesian Optimization is a powerful technique for optimizing expensive black-box functions, with applications in areas like hyperparameter tuning, reinforcement learning, and medical imaging.
The TS-RSR algorithm is designed to be provably efficient, meaning it has theoretical guarantees on its performance. Specifically, the algorithm aims to minimize the "regret-to-sigma ratio", a measure of how efficiently the algorithm is able to find the best setting of the function being optimized.
The key technical innovation is the use of Thompson Sampling, a popular bandit algorithm, in the BO setting. Thompson Sampling involves taking random guesses at the best setting and then learning from the results. The paper shows that this TS-RSR algorithm achieves state-of-the-art performance on a range of benchmark BO problems.
Critical Analysis
The paper provides a thorough theoretical analysis of the TS-RSR algorithm, establishing tight regret bounds and demonstrating its superior empirical performance compared to existing BO methods. However, the authors acknowledge several limitations and areas for further research.
For example, the analysis assumes the objective function satisfies certain technical conditions, such as having a bounded derivative. In practice, many real-world optimization problems may violate these assumptions. Additionally, the paper does not address the challenge of selecting appropriate prior distributions for the Bayesian model, which can significantly impact the algorithm's performance.
Further research could explore relaxing the theoretical assumptions, developing more robust prior elicitation techniques, and investigating the algorithm's performance on a wider range of practical applications. Incorporating additional problem structure, such as non-stationary distributions or contextual information, may also lead to further improvements in the TS-RSR algorithm's efficiency and applicability.
Conclusion
This paper presents a new algorithm, TS-RSR, for batch Bayesian Optimization that aims to minimize the regret-to-sigma ratio, a measure of the algorithm's efficiency. The paper establishes strong theoretical guarantees on the algorithm's performance and demonstrates its empirical superiority over existing BO methods.
The TS-RSR algorithm has the potential to significantly improve the efficiency of Bayesian Optimization in a wide range of applications, from hyperparameter tuning to reinforcement learning and beyond. While the theoretical analysis and empirical results are promising, further research is needed to address the limitations and expand the algorithm's applicability to real-world optimization problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TS-RSR: A provably efficient approach for batch bayesian optimization
Zhaolin Ren, Na Li
This paper presents a new approach for batch Bayesian Optimization (BO) called Thompson Sampling-Regret to Sigma Ratio directed sampling (TS-RSR), where we sample a new batch of actions by minimizing a Thompson Sampling approximation of a regret to uncertainty ratio. Our sampling objective is able to coordinate the actions chosen in each batch in a way that minimizes redundancy between points whilst focusing on points with high predictive means or high uncertainty. Theoretically, we provide rigorous convergence guarantees on our algorithm's regret, and numerically, we demonstrate that our method attains state-of-the-art performance on a range of challenging synthetic and realistic test functions, where it outperforms several competitive benchmark batch BO algorithms.
Read more5/3/2024
0
Epsilon-Greedy Thompson Sampling to Bayesian Optimization
Bach Do, Taiwo Adebiyi, Ruda Zhang
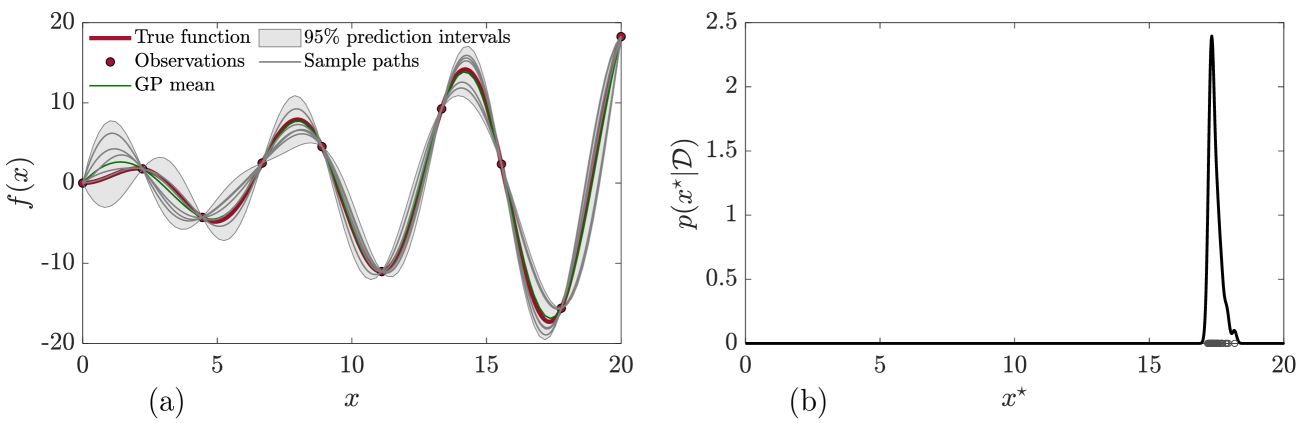
Bayesian optimization (BO) has become a powerful tool for solving simulation-based engineering optimization problems thanks to its ability to integrate physical and mathematical understandings, consider uncertainty, and address the exploitation--exploration dilemma. Thompson sampling (TS) is a preferred solution for BO to handle the exploitation--exploration trade-off. While it prioritizes exploration by generating and minimizing random sample paths from probabilistic models -- a fundamental ingredient of BO -- TS weakly manages exploitation by gathering information about the true objective function after it obtains new observations. In this work, we improve the exploitation of TS by incorporating the $varepsilon$-greedy policy, a well-established selection strategy in reinforcement learning. We first delineate two extremes of TS, namely the generic TS and the sample-average TS. The former promotes exploration, while the latter favors exploitation. We then adopt the $varepsilon$-greedy policy to randomly switch between these two extremes. Small and large values of $varepsilon$ govern exploitation and exploration, respectively. By minimizing two benchmark functions and solving an inverse problem of a steel cantilever beam,we empirically show that $varepsilon$-greedy TS equipped with an appropriate $varepsilon$ is more robust than its two extremes,matching or outperforming the better of the generic TS and the sample-average TS.
Read more5/7/2024
🛠️
0
Posterior Sampling-Based Bayesian Optimization with Tighter Bayesian Regret Bounds
Shion Takeno, Yu Inatsu, Masayuki Karasuyama, Ichiro Takeuchi
Among various acquisition functions (AFs) in Bayesian optimization (BO), Gaussian process upper confidence bound (GP-UCB) and Thompson sampling (TS) are well-known options with established theoretical properties regarding Bayesian cumulative regret (BCR). Recently, it has been shown that a randomized variant of GP-UCB achieves a tighter BCR bound compared with GP-UCB, which we call the tighter BCR bound for brevity. Inspired by this study, this paper first shows that TS achieves the tighter BCR bound. On the other hand, GP-UCB and TS often practically suffer from manual hyperparameter tuning and over-exploration issues, respectively. Therefore, we analyze yet another AF called a probability of improvement from the maximum of a sample path (PIMS). We show that PIMS achieves the tighter BCR bound and avoids the hyperparameter tuning, unlike GP-UCB. Furthermore, we demonstrate a wide range of experiments, focusing on the effectiveness of PIMS that mitigates the practical issues of GP-UCB and TS.
Read more6/5/2024
0
Efficient and Adaptive Posterior Sampling Algorithms for Bandits
Bingshan Hu, Zhiming Huang, Tianyue H. Zhang, Mathias L'ecuyer, Nidhi Hegde
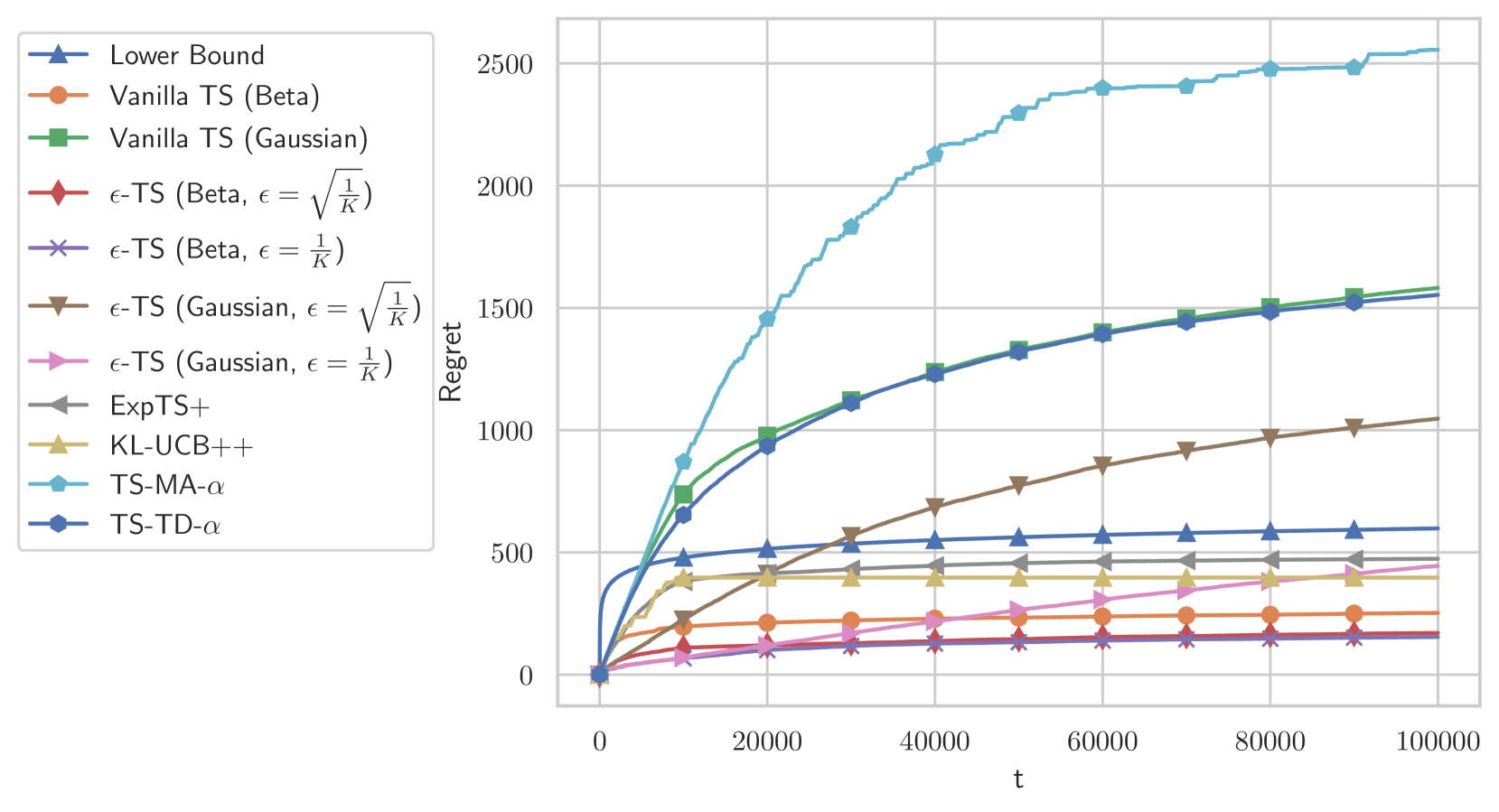
We study Thompson Sampling-based algorithms for stochastic bandits with bounded rewards. As the existing problem-dependent regret bound for Thompson Sampling with Gaussian priors [Agrawal and Goyal, 2017] is vacuous when $T le 288 e^{64}$, we derive a more practical bound that tightens the coefficient of the leading term %from $288 e^{64}$ to $1270$. Additionally, motivated by large-scale real-world applications that require scalability, adaptive computational resource allocation, and a balance in utility and computation, we propose two parameterized Thompson Sampling-based algorithms: Thompson Sampling with Model Aggregation (TS-MA-$alpha$) and Thompson Sampling with Timestamp Duelling (TS-TD-$alpha$), where $alpha in [0,1]$ controls the trade-off between utility and computation. Both algorithms achieve $O left(Kln^{alpha+1}(T)/Delta right)$ regret bound, where $K$ is the number of arms, $T$ is the finite learning horizon, and $Delta$ denotes the single round performance loss when pulling a sub-optimal arm.
Read more5/3/2024