The Power of LLM-Generated Synthetic Data for Stance Detection in Online Political Discussions

0

Sign in to get full access
Overview
- The paper explores using large language models (LLMs) to generate synthetic data for improving stance detection in online political discussions.
- It investigates whether fine-tuning a stance detection model with LLM-generated synthetic data can outperform models trained on real-world data alone.
- The research aims to address the challenge of limited annotated data for stance detection tasks, which can be mitigated by leveraging the versatility of LLMs.
Plain English Explanation
Stance detection is the task of identifying whether someone agrees or disagrees with a particular position or viewpoint, often in the context of online political discussions. However, building effective stance detection models can be challenging, as they require large datasets of annotated examples, which can be costly and time-consuming to collect.
To address this, the researchers in this paper explored using large language models (LLMs) - powerful AI systems trained on massive amounts of text data - to generate synthetic data for improving stance detection. The idea is that by fine-tuning a stance detection model on a combination of real-world and LLM-generated synthetic data, the model's performance can be significantly improved compared to using real-world data alone.
The paper's key finding is that yes, fine-tuning with synthetic data does improve the stance detection model, and the more synthetic data used, the better the model performs. This suggests that LLMs can be a powerful tool for generating high-quality synthetic data to supplement scarce real-world datasets, ultimately leading to more robust and accurate stance detection models.
Technical Explanation
The researchers first trained a state-of-the-art stance detection model on a publicly available dataset of real-world political discussions. They then fine-tuned this model using different amounts of LLM-generated synthetic data, ranging from 10% to 100% of the original dataset size.
The synthetic data was generated using a pre-trained LLM, which was fine-tuned on the same real-world dataset used for the initial stance detection model. This fine-tuned LLM was then used to generate new text samples expressing different stances on political issues, which were then added to the original dataset to fine-tune the stance detection model.
The researchers evaluated the performance of the fine-tuned models on a held-out test set of real-world data and found that using synthetic data consistently improved the stance detection accuracy, with the best-performing model using 100% synthetic data. They also observed that the more synthetic data used, the higher the model's performance, suggesting that LLMs can be a valuable tool for data augmentation in stance detection tasks.
Critical Analysis
The paper provides a compelling demonstration of the potential of LLM-generated synthetic data to improve stance detection models. However, the research does have some limitations that merit further consideration:
-
The quality and diversity of the synthetic data: While the paper shows that more synthetic data leads to better performance, the researchers do not deeply explore the characteristics of the synthetic data and how it compares to real-world data. Further analysis of the synthetic data could provide insights into the types of examples that are most beneficial for fine-tuning.
-
Generalization to other domains: The experiments in the paper are focused on political discussions, which may have distinctive linguistic patterns and discourse structures. It's unclear how well the findings would translate to stance detection in other domains, such as social, economic, or cultural discussions.
-
Potential biases in the synthetic data: As with any AI-generated content, the synthetic data may inherit biases present in the training data or the LLM itself. The paper does not address the potential for these biases to be propagated into the fine-tuned stance detection model.
-
Scalability and computational efficiency: While the paper demonstrates the effectiveness of using synthetic data, the process of generating and fine-tuning the models may be computationally intensive, which could limit its practical applicability, especially for real-time or large-scale stance detection tasks.
Conclusion
Overall, this paper provides an important contribution to the field of stance detection by showcasing the potential of LLM-generated synthetic data to significantly improve model performance. The findings suggest that by leveraging the versatility and generative capabilities of large language models, researchers and practitioners can create high-quality synthetic datasets to supplement limited real-world annotated data.
As the field of natural language processing continues to evolve, this research highlights the promising role that synthetic data can play in advancing tasks like stance detection, which are crucial for understanding and analyzing online political discourse. However, further exploration of the limitations and potential biases inherent in LLM-generated synthetic data is needed to fully realize the benefits of this approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
The Power of LLM-Generated Synthetic Data for Stance Detection in Online Political Discussions
Stefan Sylvius Wagner, Maike Behrendt, Marc Ziegele, Stefan Harmeling
Stance detection holds great potential for enhancing the quality of online political discussions, as it has shown to be useful for summarizing discussions, detecting misinformation, and evaluating opinion distributions. Usually, transformer-based models are used directly for stance detection, which require large amounts of data. However, the broad range of debate questions in online political discussion creates a variety of possible scenarios that the model is faced with and thus makes data acquisition for model training difficult. In this work, we show how to leverage LLM-generated synthetic data to train and improve stance detection agents for online political discussions:(i) We generate synthetic data for specific debate questions by prompting a Mistral-7B model and show that fine-tuning with the generated synthetic data can substantially improve the performance of stance detection. (ii) We examine the impact of combining synthetic data with the most informative samples from an unlabelled dataset. First, we use the synthetic data to select the most informative samples, second, we combine both these samples and the synthetic data for fine-tuning. This approach reduces labelling effort and consistently surpasses the performance of the baseline model that is trained with fully labeled data. Overall, we show in comprehensive experiments that LLM-generated data greatly improves stance detection performance for online political discussions.
Read more6/19/2024

0
SQBC: Active Learning using LLM-Generated Synthetic Data for Stance Detection in Online Political Discussions
Stefan Sylvius Wagner, Maike Behrendt, Marc Ziegele, Stefan Harmeling
Stance detection is an important task for many applications that analyse or support online political discussions. Common approaches include fine-tuning transformer based models. However, these models require a large amount of labelled data, which might not be available. In this work, we present two different ways to leverage LLM-generated synthetic data to train and improve stance detection agents for online political discussions: first, we show that augmenting a small fine-tuning dataset with synthetic data can improve the performance of the stance detection model. Second, we propose a new active learning method called SQBC based on the Query-by-Comittee approach. The key idea is to use LLM-generated synthetic data as an oracle to identify the most informative unlabelled samples, that are selected for manual labelling. Comprehensive experiments show that both ideas can improve the stance detection performance. Curiously, we observed that fine-tuning on actively selected samples can exceed the performance of using the full dataset.
Read more4/15/2024
🔎
0
Stance Detection on Social Media with Fine-Tuned Large Language Models
.Ilker Gul, R'emi Lebret, Karl Aberer
Stance detection, a key task in natural language processing, determines an author's viewpoint based on textual analysis. This study evaluates the evolution of stance detection methods, transitioning from early machine learning approaches to the groundbreaking BERT model, and eventually to modern Large Language Models (LLMs) such as ChatGPT, LLaMa-2, and Mistral-7B. While ChatGPT's closed-source nature and associated costs present challenges, the open-source models like LLaMa-2 and Mistral-7B offers an encouraging alternative. Initially, our research focused on fine-tuning ChatGPT, LLaMa-2, and Mistral-7B using several publicly available datasets. Subsequently, to provide a comprehensive comparison, we assess the performance of these models in zero-shot and few-shot learning scenarios. The results underscore the exceptional ability of LLMs in accurately detecting stance, with all tested models surpassing existing benchmarks. Notably, LLaMa-2 and Mistral-7B demonstrate remarkable efficiency and potential for stance detection, despite their smaller sizes compared to ChatGPT. This study emphasizes the potential of LLMs in stance detection and calls for more extensive research in this field.
Read more4/19/2024
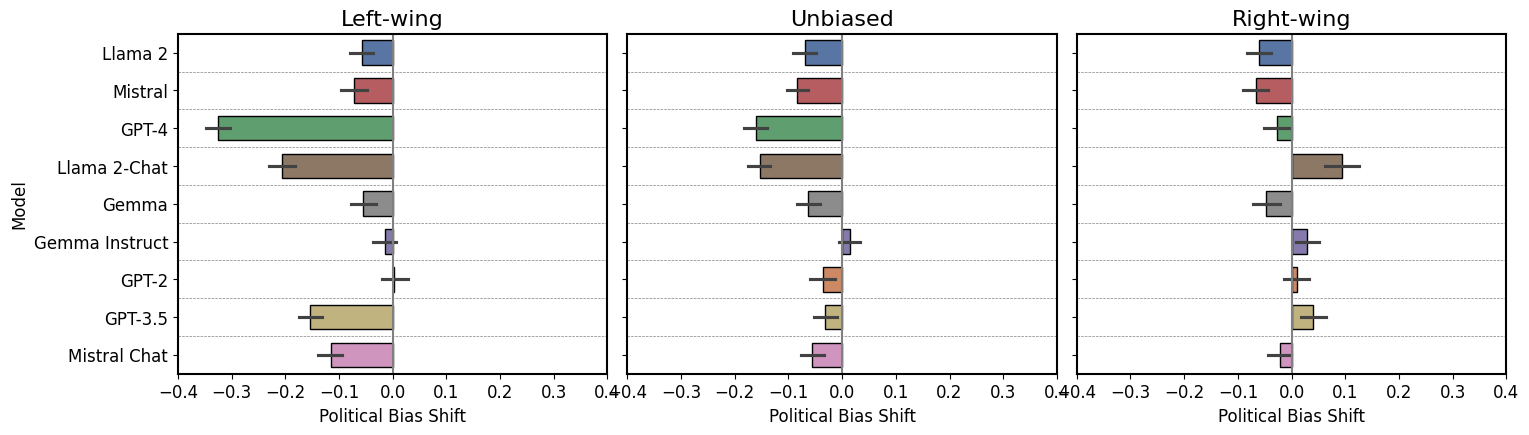
0
Quantifying Generative Media Bias with a Corpus of Real-world and Generated News Articles
Filip Trhlik, Pontus Stenetorp
Large language models (LLMs) are increasingly being utilised across a range of tasks and domains, with a burgeoning interest in their application within the field of journalism. This trend raises concerns due to our limited understanding of LLM behaviour in this domain, especially with respect to political bias. Existing studies predominantly focus on LLMs undertaking political questionnaires, which offers only limited insights into their biases and operational nuances. To address this gap, our study establishes a new curated dataset that contains 2,100 human-written articles and utilises their descriptions to generate 56,700 synthetic articles using nine LLMs. This enables us to analyse shifts in properties between human-authored and machine-generated articles, with this study focusing on political bias, detecting it using both supervised models and LLMs. Our findings reveal significant disparities between base and instruction-tuned LLMs, with instruction-tuned models exhibiting consistent political bias. Furthermore, we are able to study how LLMs behave as classifiers, observing their display of political bias even in this role. Overall, for the first time within the journalistic domain, this study outlines a framework and provides a structured dataset for quantifiable experiments, serving as a foundation for further research into LLM political bias and its implications.
Read more6/18/2024