Pre-Training Representations of Binary Code Using Contrastive Learning

0
📉
Sign in to get full access
Overview
- Compiled software is delivered as executable binary code, which is difficult for humans to understand.
- Existing work uses AI models to assist in analyzing source code, but few studies have considered binary code analysis.
- This paper proposes a model called COMBO that incorporates source code and comments into binary code representation learning to improve binary code analysis tasks.
Plain English Explanation
When software is compiled, the original human-readable source code is converted into a binary format that a computer's central processing unit (CPU) can directly execute. This binary code is much more difficult for human engineers to understand and analyze compared to the original source code or natural language.
While researchers have used AI models to help analyze source code, not much work has been done on using AI to assist with binary code analysis. This paper introduces a new AI model called COMBO (COntrastive learning Model for Binary cOde Analysis) that aims to improve binary code analysis by incorporating information from the original source code and comments.
The key idea is to use a contrastive learning approach, which trains the model to recognize patterns and relationships in the data by comparing positive and negative examples. COMBO uses this technique to learn representations of the binary code that capture relevant information, while also incorporating the source code and comments to provide additional context.
The paper evaluates COMBO on three different tasks related to binary code analysis: algorithmic functionality classification, binary code similarity, and vulnerability detection. The results show that COMBO outperforms other state-of-the-art models on these tasks, demonstrating the value of its approach to incorporating multiple sources of information into the binary code representation.
Technical Explanation
The paper proposes a COntrastive learning Model for Binary cOde Analysis (COMBO) that incorporates source code and comment information into binary code representation learning.
COMBO has three main components:
-
Primary Contrastive Learning: This is the core of the model, which uses a contrastive learning approach to pre-train the representation of the binary code. Contrastive learning trains the model to recognize patterns and relationships in the data by comparing positive and negative examples.
-
Simplex Interpolation: This method is used to incorporate the source code, comments, and binary code into the representation learning process. It allows the model to leverage the semantic information from the source code and comments to improve the binary code representation.
-
Intermediate Representation Learning: This step produces the final binary code embeddings that can be used for various downstream tasks, such as the three evaluated in the paper: algorithmic functionality classification, binary code similarity, and vulnerability detection.
The paper evaluates COMBO on these three tasks and compares its performance to state-of-the-art large-scale language representation models. The results show that COMBO outperforms these models by 5.45% on average, demonstrating the value of incorporating source code and comment information into binary code representation learning.
Critical Analysis
The paper presents a novel and promising approach to binary code analysis by leveraging source code and comments. The use of contrastive learning and the incorporation of multiple sources of information are compelling aspects of the research.
However, the paper does not address some potential limitations and areas for further work:
- Scalability: The evaluation is conducted on a relatively small dataset, and it's unclear how well COMBO would scale to larger, more diverse datasets encountered in real-world binary code analysis tasks.
- Interpretability: The paper does not provide much insight into the internal workings of COMBO or how the model arrives at its representations and decisions. Improving the interpretability of the model could be valuable for users who need to understand the reasoning behind the results.
- Generalization: The paper focuses on three specific tasks, but it's unclear how well COMBO's representations would generalize to other binary code analysis tasks or domains. Further research is needed to understand the broader applicability of the approach.
Overall, the paper presents an interesting and promising approach to binary code analysis, but additional research is needed to fully understand the capabilities, limitations, and potential impact of the COMBO model.
Conclusion
This paper introduces COMBO, a COntrastive learning Model for Binary cOde Analysis that incorporates source code and comment information into binary code representation learning. By leveraging multiple sources of information, COMBO achieves superior performance on three key binary code analysis tasks: algorithmic functionality classification, binary code similarity, and vulnerability detection.
The paper's key contribution is demonstrating the value of incorporating source code and comments into binary code analysis, which is a critical task in areas like reverse engineering and computer security where the original source code may not be available. The results suggest that COMBO's approach to representation learning can unlock new capabilities in binary code analysis and inspire further research in this important and challenging domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📉
0
Pre-Training Representations of Binary Code Using Contrastive Learning
Yifan Zhang, Chen Huang, Kevin Cao, Yueke Zhang, Scott Thomas Andersen, Huajie Shao, Kevin Leach, Yu Huang
Compiled software is delivered as executable binary code. Developers write source code to express the software semantics, but the compiler converts it to a binary format that the CPU can directly execute. Therefore, binary code analysis is critical to applications in reverse engineering and computer security tasks where source code is not available. However, unlike source code and natural language that contain rich semantic information, binary code is typically difficult for human engineers to understand and analyze. While existing work uses AI models to assist source code analysis, few studies have considered binary code. In this paper, we propose a COntrastive learning Model for Binary cOde Analysis, or COMBO, that incorporates source code and comment information into binary code during representation learning. Specifically, we present three components in COMBO: (1) a primary contrastive learning method for cold-start pre-training, (2) a simplex interpolation method to incorporate source code, comments, and binary code, and (3) an intermediate representation learning algorithm to provide binary code embeddings. Finally, we evaluate the effectiveness of the pre-trained representations produced by COMBO using three indicative downstream tasks relating to binary code: algorithmic functionality classification, binary code similarity, and vulnerability detection. Our experimental results show that COMBO facilitates representation learning of binary code visualized by distribution analysis, and improves the performance on all three downstream tasks by 5.45% on average compared to state-of-the-art large-scale language representation models. To the best of our knowledge, COMBO is the first language representation model that incorporates source code, binary code, and comments into contrastive code representation learning and unifies multiple tasks for binary code analysis.
Read more8/22/2024
0
On Training a Neural Network to Explain Binaries
Alexander Interrante-Grant, Andy Davis, Heather Preslier, Tim Leek
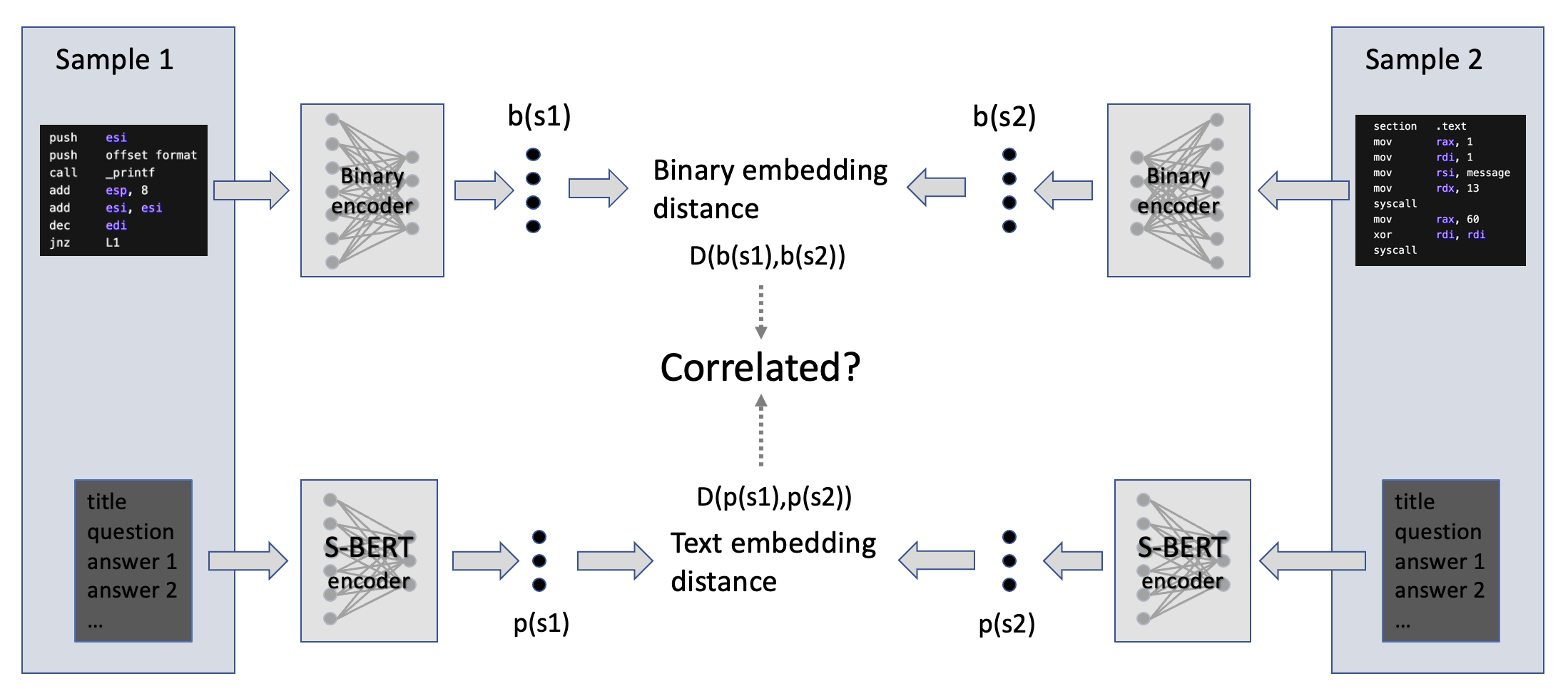
In this work, we begin to investigate the possibility of training a deep neural network on the task of binary code understanding. Specifically, the network would take, as input, features derived directly from binaries and output English descriptions of functionality to aid a reverse engineer in investigating the capabilities of a piece of closed-source software, be it malicious or benign. Given recent success in applying large language models (generative AI) to the task of source code summarization, this seems a promising direction. However, in our initial survey of the available datasets, we found nothing of sufficiently high quality and volume to train these complex models. Instead, we build our own dataset derived from a capture of Stack Overflow containing 1.1M entries. A major result of our work is a novel dataset evaluation method using the correlation between two distances on sample pairs: one distance in the embedding space of inputs and the other in the embedding space of outputs. Intuitively, if two samples have inputs close in the input embedding space, their outputs should also be close in the output embedding space. We found this Embedding Distance Correlation (EDC) test to be highly diagnostic, indicating that our collected dataset and several existing open-source datasets are of low quality as the distances are not well correlated. We proceed to explore the general applicability of EDC, applying it to a number of qualitatively known good datasets and a number of synthetically known bad ones and found it to be a reliable indicator of dataset value.
Read more5/1/2024

0
Source Code Foundation Models are Transferable Binary Analysis Knowledge Bases
Zian Su, Xiangzhe Xu, Ziyang Huang, Kaiyuan Zhang, Xiangyu Zhang
Human-Oriented Binary Reverse Engineering (HOBRE) lies at the intersection of binary and source code, aiming to lift binary code to human-readable content relevant to source code, thereby bridging the binary-source semantic gap. Recent advancements in uni-modal code model pre-training, particularly in generative Source Code Foundation Models (SCFMs) and binary understanding models, have laid the groundwork for transfer learning applicable to HOBRE. However, existing approaches for HOBRE rely heavily on uni-modal models like SCFMs for supervised fine-tuning or general LLMs for prompting, resulting in sub-optimal performance. Inspired by recent progress in large multi-modal models, we propose that it is possible to harness the strengths of uni-modal code models from both sides to bridge the semantic gap effectively. In this paper, we introduce a novel probe-and-recover framework that incorporates a binary-source encoder-decoder model and black-box LLMs for binary analysis. Our approach leverages the pre-trained knowledge within SCFMs to synthesize relevant, symbol-rich code fragments as context. This additional context enables black-box LLMs to enhance recovery accuracy. We demonstrate significant improvements in zero-shot binary summarization and binary function name recovery, with a 10.3% relative gain in CHRF and a 16.7% relative gain in a GPT4-based metric for summarization, as well as a 6.7% and 7.4% absolute increase in token-level precision and recall for name recovery, respectively. These results highlight the effectiveness of our approach in automating and improving binary code analysis.
Read more5/31/2024
💬
0
Nova: Generative Language Models for Assembly Code with Hierarchical Attention and Contrastive Learning
Nan Jiang, Chengxiao Wang, Kevin Liu, Xiangzhe Xu, Lin Tan, Xiangyu Zhang
Binary code analysis is the foundation of crucial tasks in the security domain; thus building effective binary analysis techniques is more important than ever. Large language models (LLMs) although have brought impressive improvement to source code tasks, do not directly generalize to assembly code due to the unique challenges of assembly: (1) the low information density of assembly and (2) the diverse optimizations in assembly code. To overcome these challenges, this work proposes a hierarchical attention mechanism that builds attention summaries to capture the semantics more effectively, and designs contrastive learning objectives to train LLMs to learn assembly optimization. Equipped with these techniques, this work develops Nova, a generative LLM for assembly code. Nova outperforms existing techniques on binary code decompilation by up to 146.54%, and outperforms the latest binary code similarity detection techniques by up to 6.17%, showing promising abilities on both assembly generation and understanding tasks.
Read more6/19/2024