Toward Exploring the Code Understanding Capabilities of Pre-trained Code Generation Models

0
Sign in to get full access
Overview
- This paper explores the code understanding capabilities of pre-trained code generation models, which are large language models trained on vast amounts of code data.
- The researchers investigate how well these models can perform various code-related tasks, such as code summarization, code search, and code generation.
- The findings provide insights into the current state of code understanding in large language models and identify areas for future research and development.
Plain English Explanation
Computers are becoming increasingly adept at understanding and generating code, thanks to the rise of large language models trained on massive datasets of programming languages. These models, known as pre-trained code generation models, have the potential to revolutionize how we interact with and understand code.
In this research paper, the authors set out to explore the code understanding capabilities of these pre-trained models. They wanted to see how well the models could perform tasks like summarizing code, searching for relevant code snippets, and generating new code from scratch.
By testing the models on a variety of code-related tasks, the researchers were able to gain insights into the current state of code understanding in these large language models. They identified areas where the models excel, as well as areas where there is room for improvement.
For example, the models showed strong performance in tasks like code summarization, where they could concisely describe the purpose and functionality of a given code snippet. However, they struggled more with tasks that required deeper semantic understanding, such as code search and generation.
These findings are important because they help us understand the limitations of current code generation models and point the way towards future research and development. By addressing the challenges identified in this paper, we can work towards creating even more powerful and capable models that can truly revolutionize the way we interact with and understand code.
Technical Explanation
The researchers conducted a series of experiments to assess the code understanding capabilities of pre-trained code generation models, such as Transcoder, CERT, and SemCoder.
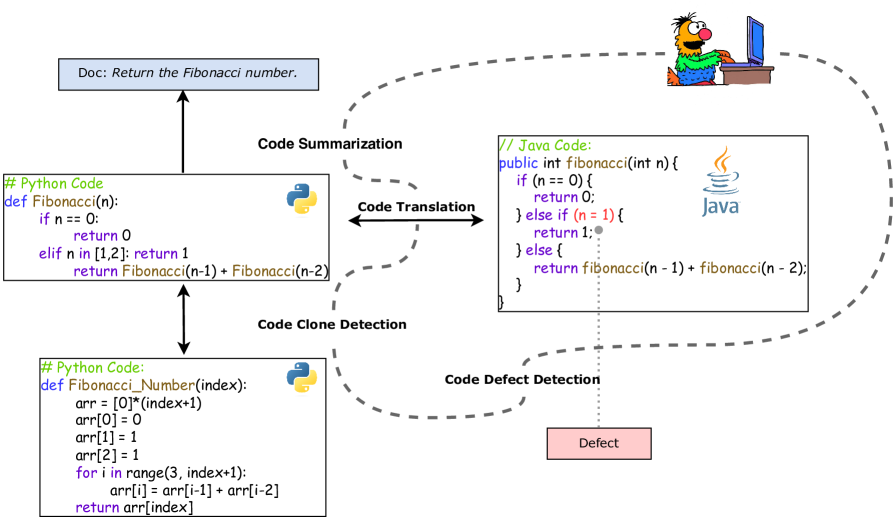
They evaluated the models on a range of code-related tasks, including:
- Code Summarization: Generating a natural language summary of a given code snippet.
- Code Search: Retrieving relevant code snippets from a codebase given a natural language query.
- Code Generation: Generating new code from a natural language description.
The experiments were designed to test the models' ability to understand the semantics and structure of code, as well as their capacity to transfer this understanding to different programming languages and domains.
The results showed that the pre-trained models exhibited strong performance on the code summarization task, indicating their ability to capture the high-level functionality of code. However, the models struggled more with the code search and generation tasks, which require deeper semantic understanding and reasoning capabilities.
The researchers also found that the models' performance varied across different programming languages and domains, suggesting that further research is needed to improve the models' cross-language and cross-domain generalization abilities. Approaches like Code Pretraining and Retrieval-Enhanced Zero-Shot Video Captioning may be promising directions to explore.
Critical Analysis
The paper provides a comprehensive and rigorous evaluation of the code understanding capabilities of pre-trained code generation models. The researchers' experimental design and analysis are sound, and the results offer valuable insights into the current limitations and future research directions in this field.
One potential limitation of the study is the reliance on a limited set of programming languages and tasks. While the authors attempted to cover a range of domains, there may be additional challenges or nuances that emerge when considering a more diverse set of programming languages and real-world code-related tasks.
Additionally, the paper does not delve into the potential biases or fairness implications of these pre-trained models. As with any large language model, there may be concerns about the representation and treatment of different programming languages, domains, or developer communities, which could impact the models' performance and utility in practical applications.
Further research is needed to address these limitations and explore more holistic approaches to improving the code understanding capabilities of large language models. Investigating techniques like few-shot or few-label learning, as well as incorporating more diverse and representative datasets, could lead to more robust and equitable code generation and understanding models.
Conclusion
This paper provides a valuable contribution to the understanding of pre-trained code generation models and their code comprehension abilities. The researchers' thorough evaluation of these models on various code-related tasks reveals both the strengths and limitations of the current state-of-the-art in this rapidly evolving field.
The findings suggest that while pre-trained code generation models have made significant strides in tasks like code summarization, they still struggle with deeper semantic understanding and reasoning required for more complex code-related tasks. Addressing these challenges through continued research and development will be crucial in unlocking the full potential of these models and enabling more seamless and powerful code-centric AI systems.
As the field of code understanding continues to advance, this paper serves as an important stepping stone, highlighting the need for further exploration and innovation to push the boundaries of what is possible in the realm of AI-powered code comprehension and generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Toward Exploring the Code Understanding Capabilities of Pre-trained Code Generation Models
Jiayi Lin, Yutao Xie, Yue Yu, Yibiao Yang, Lei Zhang
Recently, large code generation models trained in a self-supervised manner on extensive unlabeled programming language data have achieved remarkable success. While these models acquire vast amounts of code knowledge, they perform poorly on code understanding tasks, such as code search and clone detection, as they are specifically trained for generation. Pre-training a larger encoder-only architecture model from scratch on massive code data can improve understanding performance. However, this approach is costly and time-consuming, making it suboptimal. In this paper, we pioneer the transfer of knowledge from pre-trained code generation models to code understanding tasks, significantly reducing training costs. We examine effective strategies for enabling decoder-only models to acquire robust code representations. Furthermore, we introduce CL4D, a contrastive learning method designed to enhance the representation capabilities of decoder-only models. Comprehensive experiments demonstrate that our approach achieves state-of-the-art performance in understanding tasks such as code search and clone detection. Our analysis shows that our method effectively reduces the distance between semantically identical samples in the representation space. These findings suggest the potential for unifying code understanding and generation tasks using a decoder-only structured model.
Read more6/19/2024
0
TransCoder: Towards Unified Transferable Code Representation Learning Inspired by Human Skills
Qiushi Sun, Nuo Chen, Jianing Wang, Xiang Li, Ming Gao
Code pre-trained models (CodePTMs) have recently demonstrated a solid capacity to process various software intelligence tasks, e.g., code clone detection, code translation, and code summarization. The current mainstream method that deploys these models to downstream tasks is to fine-tune them on individual tasks, which is generally costly and needs sufficient data for large models. To tackle the issue, in this paper, we present TransCoder, a unified Transferable fine-tuning strategy for Code representation learning. Inspired by human inherent skills of knowledge generalization, TransCoder drives the model to learn better code-related meta-knowledge like human programmers. Specifically, we employ a tunable prefix encoder as the meta-learner to capture cross-task and cross-language transferable knowledge, respectively. Besides, tasks with minor training sample sizes and languages with small corpus can be remarkably benefited from our approach. Extensive experiments conducted on benchmark datasets clearly demonstrate that our method can lead to superior performance on various code-related tasks and encourage mutual reinforcement. We also show that TransCoder is applicable in low-resource scenarios. Our codes are available at https://github.com/QiushiSun/TransCoder.
Read more5/10/2024

0
A new approach for encoding code and assisting code understanding
Mengdan Fan, Wei Zhang, Haiyan Zhao, Zhi Jin
Some companies(e.g., Microsoft Research and Google DeepMind) have discovered some of the limitations of GPTs autoregressive paradigm next-word prediction, manifested in the model lack of planning, working memory, backtracking, and reasoning skills. GPTs rely on a local and greedy process of generating the next word, without a global understanding of the task or the output.We have confirmed the above limitations through specialized empirical studies of code comprehension. Although GPT4 is good at producing fluent and coherent text, it cannot handle complex logic and generate new code that haven not been seen, and it relies too much on the formatting of the prompt to generate the correct code.We propose a new paradigm for code understanding that goes beyond the next-word prediction paradigm, inspired by the successful application of diffusion techniques to image generation(Dalle2, Sora) and protein structure generation(AlphaFold3), which have no autoregressive constraints.Instead of encoding the code in a form that mimics natural language, we encode the code as a heterogeneous image paradigm with a memory of global information that mimics both images and protein structures.We then refer to Sora's CLIP upstream text-to-image encoder model to design a text-to-code encoder model that can be applied to various downstream code understanding tasks.The model learns the global understanding of code under the new paradigm heterogeneous image, connects the encoding space of text and code, and encodes the input of text into the vector of code most similar to it.Using self-supervised comparative learning on 456,360 text-code pairs, the model achieved a zero-shot prediction of new data. This work is the basis for future work on code generation using diffusion techniques under a new paradigm to avoid autoregressive limitations.
Read more8/2/2024

0
DeepCodeProbe: Towards Understanding What Models Trained on Code Learn
Vahid Majdinasab, Amin Nikanjam, Foutse Khomh
Machine learning models trained on code and related artifacts offer valuable support for software maintenance but suffer from interpretability issues due to their complex internal variables. These concerns are particularly significant in safety-critical applications where the models' decision-making processes must be reliable. The specific features and representations learned by these models remain unclear, adding to the hesitancy in adopting them widely. To address these challenges, we introduce DeepCodeProbe, a probing approach that examines the syntax and representation learning abilities of ML models designed for software maintenance tasks. Our study applies DeepCodeProbe to state-of-the-art models for code clone detection, code summarization, and comment generation. Findings reveal that while small models capture abstract syntactic representations, their ability to fully grasp programming language syntax is limited. Increasing model capacity improves syntax learning but introduces trade-offs such as increased training time and overfitting. DeepCodeProbe also identifies specific code patterns the models learn from their training data. Additionally, we provide best practices for training models on code to enhance performance and interpretability, supported by an open-source replication package for broader application of DeepCodeProbe in interpreting other code-related models.
Read more7/15/2024