Disentangling Knowledge-based and Visual Reasoning by Question Decomposition in KB-VQA
2406.18839
0
0

Abstract
We study the Knowledge-Based visual question-answering problem, for which given a question, the models need to ground it into the visual modality to find the answer. Although many recent works use question-dependent captioners to verbalize the given image and use Large Language Models to solve the VQA problem, the research results show they are not reasonably performing for multi-hop questions. Our study shows that replacing a complex question with several simpler questions helps to extract more relevant information from the image and provide a stronger comprehension of it. Moreover, we analyze the decomposed questions to find out the modality of the information that is required to answer them and use a captioner for the visual questions and LLMs as a general knowledge source for the non-visual KB-based questions. Our results demonstrate the positive impact of using simple questions before retrieving visual or non-visual information. We have provided results and analysis on three well-known VQA datasets including OKVQA, A-OKVQA, and KRVQA, and achieved up to 2% improvement in accuracy.
Create account to get full access
Overview
• This paper proposes a method for disentangling knowledge-based and visual reasoning in visual question answering (VQA) tasks.
• The authors introduce a question decomposition approach that separates a VQA question into two parts: one that requires knowledge-based reasoning and one that requires visual reasoning.
• This allows the model to focus on the specific type of reasoning needed for each part of the question, potentially improving performance.
Plain English Explanation
The paper tackles the challenge of visual question answering (VQA), where an AI system is asked a question about an image and must provide the correct answer.
The key idea is that some questions require retrieving and reasoning about information from a knowledge base (like facts about the world), while others primarily need to analyze the visual information in the image. The authors propose a method to disentangle these two types of reasoning, breaking down each question into a "knowledge" part and a "visual" part.
This separation allows the model to focus on the specific type of reasoning needed for each part of the question, rather than trying to do both at the same time. The authors hypothesize that this will lead to better performance on VQA tasks that require a mix of knowledge-based and visual reasoning.
Technical Explanation
The core of the paper's approach is a question decomposition module that splits each VQA question into two parts: one that requires knowledge-based reasoning and one that requires visual reasoning.
This module uses a pre-trained language model to analyze the question text and identify the relevant knowledge and visual components. It then passes these decomposed parts to separate reasoning modules - one that retrieves information from a knowledge base and one that analyzes the visual features of the image.
The outputs of the knowledge-based and visual reasoning modules are then combined to produce the final answer. This disentangled approach allows the model to focus on the specific type of reasoning needed for each part of the question, rather than trying to do both simultaneously.
The authors evaluate their method on several VQA benchmarks, including OKVQA and VideoQA, and show that it outperforms baseline VQA models that do not have this disentangled structure.
Critical Analysis
The authors present a compelling approach for disentangling knowledge-based and visual reasoning in VQA tasks. The key strength is the ability to focus the model on the specific type of reasoning required for each part of the question, rather than forcing it to handle both simultaneously.
However, the paper does not address potential limitations of this approach. For example, it's not clear how well the question decomposition module will perform on more complex or ambiguous questions, where the distinction between knowledge-based and visual reasoning may be less clear.
Additionally, the reliance on a pre-trained knowledge base raises questions about the model's ability to handle novel or dynamic knowledge that may not be present in the database. Further research may be needed to address these potential issues and explore the broader applicability of the approach.
Overall, the paper presents an interesting and potentially impactful contribution to the field of VQA, with opportunities for further refinement and exploration.
Conclusion
This paper introduces a novel approach for disentangling knowledge-based and visual reasoning in visual question answering tasks. By decomposing each question into separate knowledge and visual components, the model can focus on the specific type of reasoning required for each part, potentially leading to improved performance on VQA benchmarks.
The key innovation is the question decomposition module, which uses language understanding to identify the relevant knowledge and visual elements of each question. This allows the model to pass these decomposed parts to separate reasoning modules, rather than trying to handle both simultaneously.
While the paper presents promising results, further research may be needed to address potential limitations, such as the model's ability to handle complex or ambiguous questions and its reliance on a fixed knowledge base. Nonetheless, this work represents an important step towards enhancing visual question answering through more fine-grained reasoning capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
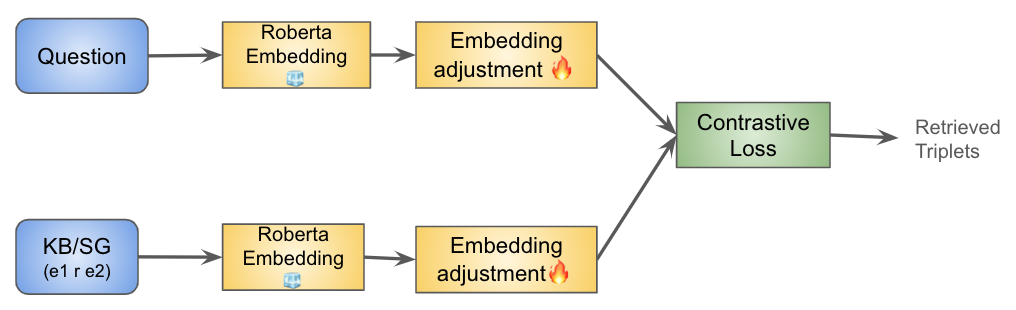
Find The Gap: Knowledge Base Reasoning For Visual Question Answering
Elham J. Barezi, Parisa Kordjamshidi
0
0
We analyze knowledge-based visual question answering, for which given a question, the models need to ground it into the visual modality and retrieve the relevant knowledge from a given large knowledge base (KB) to be able to answer. Our analysis has two folds, one based on designing neural architectures and training them from scratch, and another based on large pre-trained language models (LLMs). Our research questions are: 1) Can we effectively augment models by explicit supervised retrieval of the relevant KB information to solve the KB-VQA problem? 2) How do task-specific and LLM-based models perform in the integration of visual and external knowledge, and multi-hop reasoning over both sources of information? 3) Is the implicit knowledge of LLMs sufficient for KB-VQA and to what extent it can replace the explicit KB? Our results demonstrate the positive impact of empowering task-specific and LLM models with supervised external and visual knowledge retrieval models. Our findings show that though LLMs are stronger in 1-hop reasoning, they suffer in 2-hop reasoning in comparison with our fine-tuned NN model even if the relevant information from both modalities is available to the model. Moreover, we observed that LLM models outperform the NN model for KB-related questions which confirms the effectiveness of implicit knowledge in LLMs however, they do not alleviate the need for external KB.
4/17/2024
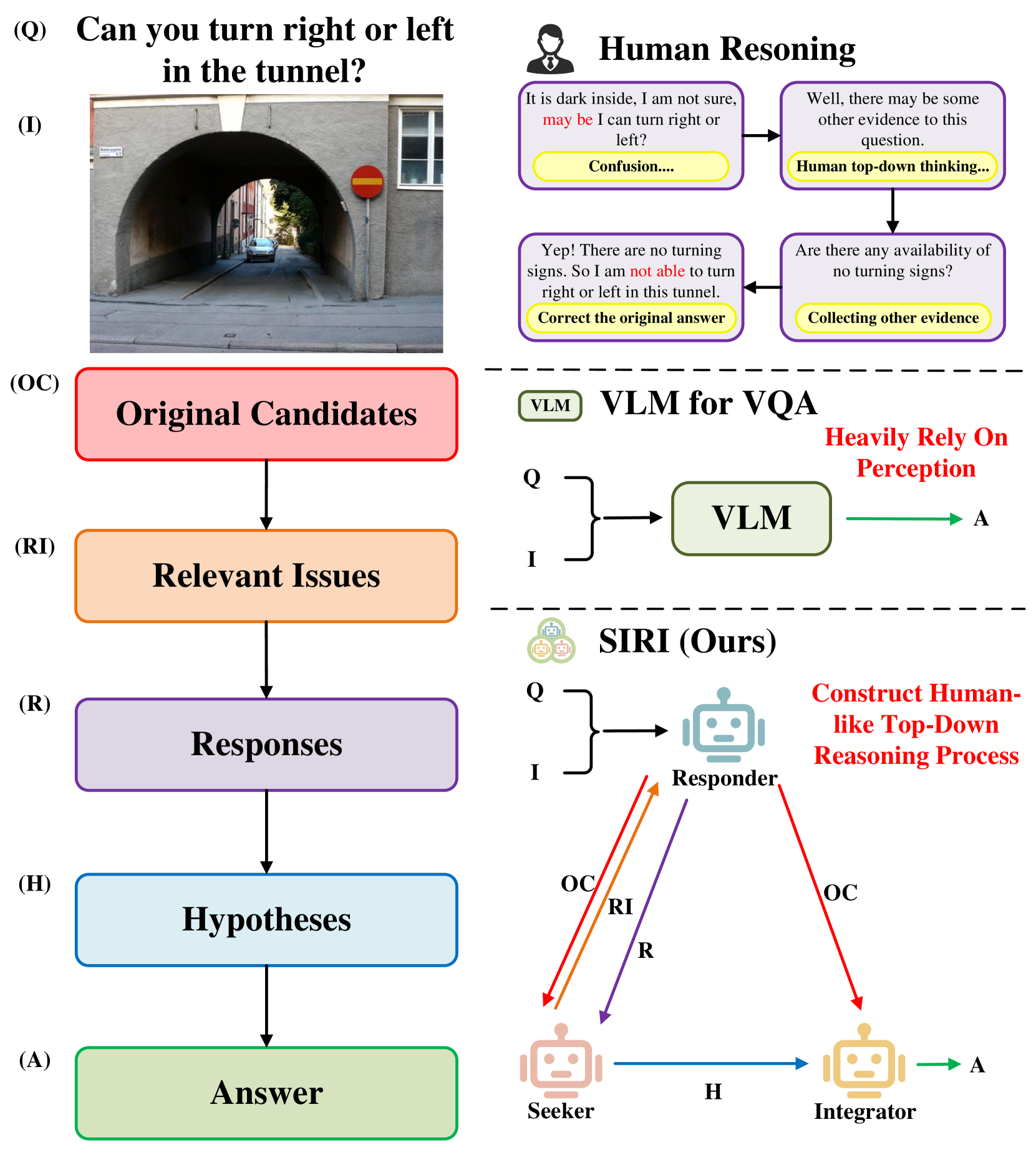
Towards Top-Down Reasoning: An Explainable Multi-Agent Approach for Visual Question Answering
Zeqing Wang, Wentao Wan, Qiqing Lao, Runmeng Chen, Minjie Lang, Keze Wang, Liang Lin
0
0
Recently, several methods have been proposed to augment large Vision Language Models (VLMs) for Visual Question Answering (VQA) simplicity by incorporating external knowledge from knowledge bases or visual clues derived from question decomposition. Although having achieved promising results, these methods still suffer from the challenge that VLMs cannot inherently understand the incorporated knowledge and might fail to generate the optimal answers. Contrarily, human cognition engages visual questions through a top-down reasoning process, systematically exploring relevant issues to derive a comprehensive answer. This not only facilitates an accurate answer but also provides a transparent rationale for the decision-making pathway. Motivated by this cognitive mechanism, we introduce a novel, explainable multi-agent collaboration framework designed to imitate human-like top-down reasoning by leveraging the expansive knowledge of Large Language Models (LLMs). Our framework comprises three agents, i.e., Responder, Seeker, and Integrator, each contributing uniquely to the top-down reasoning process. The VLM-based Responder generates the answer candidates for the question and gives responses to other issues. The Seeker, primarily based on LLM, identifies relevant issues related to the question to inform the Responder and constructs a Multi-View Knowledge Base (MVKB) for the given visual scene by leveraging the understanding capabilities of LLM. The Integrator agent combines information from the Seeker and the Responder to produce the final VQA answer. Through this collaboration mechanism, our framework explicitly constructs an MVKB for a specific visual scene and reasons answers in a top-down reasoning process. Extensive and comprehensive evaluations on diverse VQA datasets and VLMs demonstrate the superior applicability and interpretability of our framework over the existing compared methods.
5/15/2024

Precision Empowers, Excess Distracts: Visual Question Answering With Dynamically Infused Knowledge In Language Models
Manas Jhalani, Annervaz K M, Pushpak Bhattacharyya
0
0
In the realm of multimodal tasks, Visual Question Answering (VQA) plays a crucial role by addressing natural language questions grounded in visual content. Knowledge-Based Visual Question Answering (KBVQA) advances this concept by adding external knowledge along with images to respond to questions. We introduce an approach for KBVQA, augmenting the existing vision-language transformer encoder-decoder (OFA) model. Our main contribution involves enhancing questions by incorporating relevant external knowledge extracted from knowledge graphs, using a dynamic triple extraction method. We supply a flexible number of triples from the knowledge graph as context, tailored to meet the requirements for answering the question. Our model, enriched with knowledge, demonstrates an average improvement of 4.75% in Exact Match Score over the state-of-the-art on three different KBVQA datasets. Through experiments and analysis, we demonstrate that furnishing variable triples for each question improves the reasoning capabilities of the language model in contrast to supplying a fixed number of triples. This is illustrated even for recent large language models. Additionally, we highlight the model's generalization capability by showcasing its SOTA-beating performance on a small dataset, achieved through straightforward fine-tuning.
6/17/2024

Enhancing Visual Question Answering through Question-Driven Image Captions as Prompts
Ovgu Ozdemir, Erdem Akagunduz
0
0
Visual question answering (VQA) is known as an AI-complete task as it requires understanding, reasoning, and inferring about the vision and the language content. Over the past few years, numerous neural architectures have been suggested for the VQA problem. However, achieving success in zero-shot VQA remains a challenge due to its requirement for advanced generalization and reasoning skills. This study explores the impact of incorporating image captioning as an intermediary process within the VQA pipeline. Specifically, we explore the efficacy of utilizing image captions instead of images and leveraging large language models (LLMs) to establish a zero-shot setting. Since image captioning is the most crucial step in this process, we compare the impact of state-of-the-art image captioning models on VQA performance across various question types in terms of structure and semantics. We propose a straightforward and efficient question-driven image captioning approach within this pipeline to transfer contextual information into the question-answering (QA) model. This method involves extracting keywords from the question, generating a caption for each image-question pair using the keywords, and incorporating the question-driven caption into the LLM prompt. We evaluate the efficacy of using general-purpose and question-driven image captions in the VQA pipeline. Our study highlights the potential of employing image captions and harnessing the capabilities of LLMs to achieve competitive performance on GQA under the zero-shot setting. Our code is available at url{https://github.com/ovguyo/captions-in-VQA}.
4/15/2024