Geolocation Predicting of Tweets Using BERT-Based Models

0
🧠
Sign in to get full access
Overview
- This research aims to solve the problem of predicting the location of tweets and users based on their textual content.
- The proposed approach uses neural networks for natural language processing (NLP) and two-dimensional Gaussian Mixture Models (GMMs) to estimate the location as coordinate pairs (longitude, latitude).
- The models are trained and evaluated on a Twitter dataset, using pre-trained Bidirectional Encoder Representations from Transformers (BERT) as the base models.
- The performance metrics show a median error of fewer than 30 km on a worldwide-level dataset and fewer than 15 km on a US-level dataset.
- The source code and data are available on GitHub.
Plain English Explanation
The research paper presents a flexible methodology for the geotagging of textual big data. The researchers aimed to solve the problem of predicting the location of tweets and users based on the text content of their posts. To do this, they used neural networks for natural language processing (NLP) and two-dimensional Gaussian Mixture Models (GMMs) to estimate the location as coordinate pairs (longitude, latitude).
The researchers trained and evaluated their models on a dataset of tweets, using a popular pre-trained language model called Bidirectional Encoder Representations from Transformers (BERT) as the starting point. Their results show that the models were able to predict the location of tweets with a median error of fewer than 30 km on a worldwide-level dataset and fewer than 15 km on a US-level dataset.
The researchers have made their source code and data available on GitHub, which can be useful for other researchers and developers working on similar problems in the field of sentiment analysis on Twitter.
Technical Explanation
The researchers in this paper propose a flexible methodology for the geotagging of textual big data, focusing on the tweet/user geolocation prediction task. The key elements of their approach include:
- Neural Networks for NLP: The researchers use neural networks for natural language processing to estimate the location of tweets as coordinate pairs (longitude, latitude).
- Gaussian Mixture Models (GMMs): They also employ two-dimensional GMMs to model the geographic distribution of the tweet locations.
- BERT as Base Model: The researchers fine-tune pre-trained Bidirectional Encoder Representations from Transformers (BERT) as the base models for their approaches.
- Twitter Dataset: The proposed models are trained and evaluated on a Twitter dataset, which includes the text content and metadata of the tweets.
The performance of the models is evaluated using various metrics, including median error (in kilometers) on both worldwide-level and US-level datasets. The results show that the models can achieve a median error of fewer than 30 km on the worldwide-level dataset and fewer than 15 km on the US-level dataset.
Critical Analysis
The research paper presents a promising approach for the geotagging of textual big data, particularly in the context of tweet/user geolocation prediction. The use of neural networks for NLP and GMMs to model the geographic distribution of tweet locations is a well-designed and flexible methodology.
However, the paper does not discuss certain caveats and limitations of the research. For example, the performance of the models may be affected by factors such as the quality and distribution of the training data, the accuracy of the geolocation information in the dataset, and the applicability of the approach to other types of textual data beyond tweets.
Additionally, the paper could have explored the potential biases and ethical implications of using such geolocation prediction models, especially in the context of social media and user privacy concerns.
Further research could investigate the scalability and robustness of the proposed approach, as well as its performance on more diverse datasets and real-world applications. Exploring ways to incorporate additional contextual information, such as user profiles or social network data, could also be a fruitful avenue for future work.
Conclusion
This research paper presents a flexible methodology for the geotagging of textual big data, focusing on the task of tweet/user geolocation prediction. The proposed approach utilizes neural networks for natural language processing and two-dimensional Gaussian Mixture Models to estimate the location of tweets as coordinate pairs.
The models trained and evaluated on a Twitter dataset using pre-trained BERT as the base models demonstrate promising performance, with a median error of fewer than 30 km on a worldwide-level dataset and fewer than 15 km on a US-level dataset.
The availability of the source code and data on GitHub is a valuable contribution, as it allows other researchers and developers to build upon this work and explore its applications in various domains, such as sentiment analysis on social media platforms.
While the research presents a solid technical approach, further exploration of its limitations, biases, and ethical implications could strengthen the overall impact and applicability of the methodology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
Geolocation Predicting of Tweets Using BERT-Based Models
Kateryna Lutsai, Christoph H. Lampert
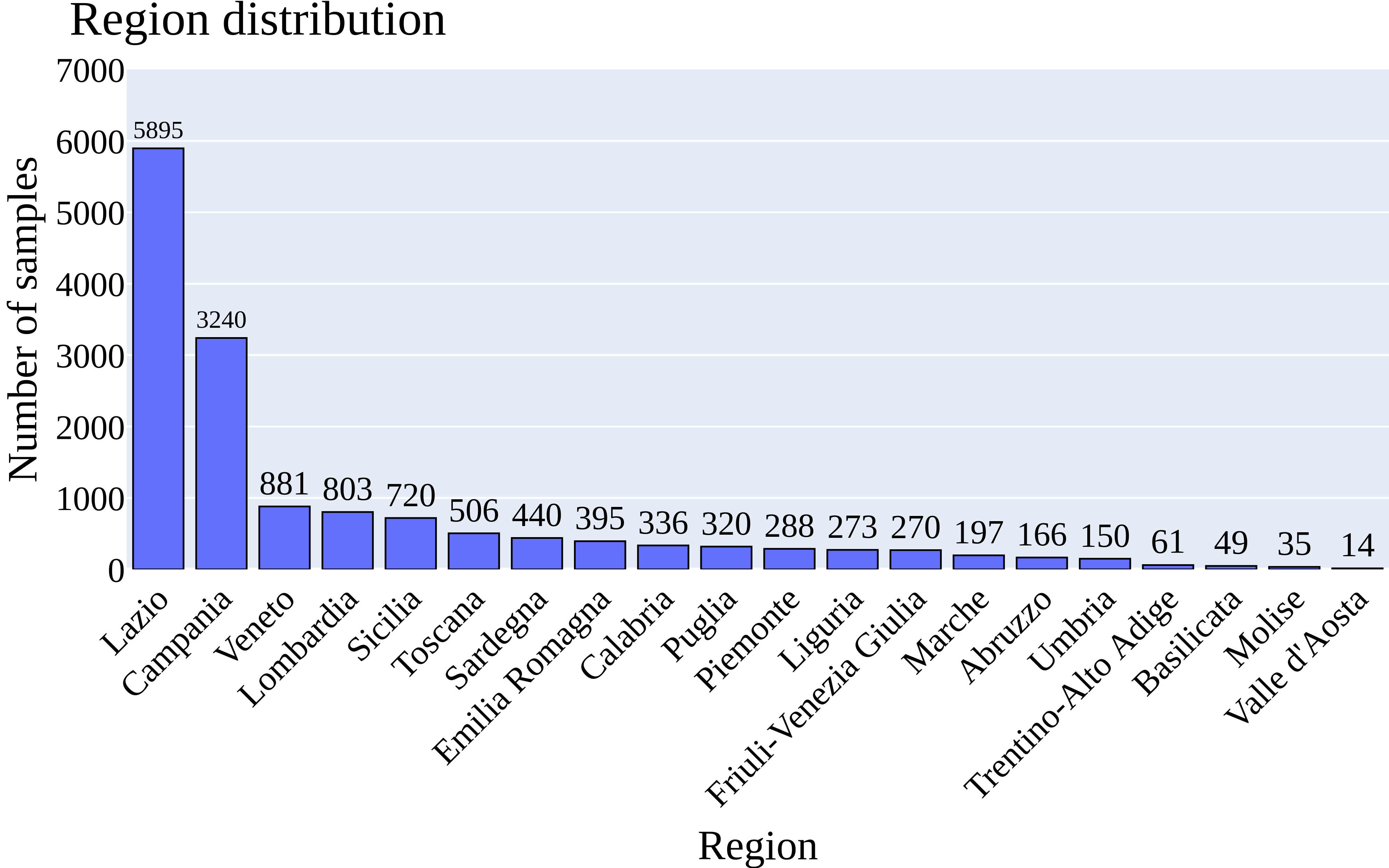
This research is aimed to solve the tweet/user geolocation prediction task and provide a flexible methodology for the geotagging of textual big data. The suggested approach implements neural networks for natural language processing (NLP) to estimate the location as coordinate pairs (longitude, latitude) and two-dimensional Gaussian Mixture Models (GMMs). The scope of proposed models has been finetuned on a Twitter dataset using pretrained Bidirectional Encoder Representations from Transformers (BERT) as base models. Performance metrics show a median error of fewer than 30 km on a worldwide-level, and fewer than 15 km on the US-level datasets for the models trained and evaluated on text features of tweets' content and metadata context. Our source code and data are available at https://github.com/K4TEL/geo-twitter.git
Read more8/2/2024
0
Leveraging Large Language Models to Geolocate Linguistic Variations in Social Media Posts
Davide Savarro, Davide Zago, Stefano Zoia
Geolocalization of social media content is the task of determining the geographical location of a user based on textual data, that may show linguistic variations and informal language. In this project, we address the GeoLingIt challenge of geolocalizing tweets written in Italian by leveraging large language models (LLMs). GeoLingIt requires the prediction of both the region and the precise coordinates of the tweet. Our approach involves fine-tuning pre-trained LLMs to simultaneously predict these geolocalization aspects. By integrating innovative methodologies, we enhance the models' ability to understand the nuances of Italian social media text to improve the state-of-the-art in this domain. This work is conducted as part of the Large Language Models course at the Bertinoro International Spring School 2024. We make our code publicly available on GitHub https://github.com/dawoz/geolingit-biss2024.
Read more7/24/2024

0
LLMGeo: Benchmarking Large Language Models on Image Geolocation In-the-wild
Zhiqiang Wang, Dejia Xu, Rana Muhammad Shahroz Khan, Yanbin Lin, Zhiwen Fan, Xingquan Zhu
Image geolocation is a critical task in various image-understanding applications. However, existing methods often fail when analyzing challenging, in-the-wild images. Inspired by the exceptional background knowledge of multimodal language models, we systematically evaluate their geolocation capabilities using a novel image dataset and a comprehensive evaluation framework. We first collect images from various countries via Google Street View. Then, we conduct training-free and training-based evaluations on closed-source and open-source multi-modal language models. we conduct both training-free and training-based evaluations on closed-source and open-source multimodal language models. Our findings indicate that closed-source models demonstrate superior geolocation abilities, while open-source models can achieve comparable performance through fine-tuning.
Read more6/3/2024

0
Geolocation Representation from Large Language Models are Generic Enhancers for Spatio-Temporal Learning
Junlin He, Tong Nie, Wei Ma
In the geospatial domain, universal representation models are significantly less prevalent than their extensive use in natural language processing and computer vision. This discrepancy arises primarily from the high costs associated with the input of existing representation models, which often require street views and mobility data. To address this, we develop a novel, training-free method that leverages large language models (LLMs) and auxiliary map data from OpenStreetMap to derive geolocation representations (LLMGeovec). LLMGeovec can represent the geographic semantics of city, country, and global scales, which acts as a generic enhancer for spatio-temporal learning. Specifically, by direct feature concatenation, we introduce a simple yet effective paradigm for enhancing multiple spatio-temporal tasks including geographic prediction (GP), long-term time series forecasting (LTSF), and graph-based spatio-temporal forecasting (GSTF). LLMGeovec can seamlessly integrate into a wide spectrum of spatio-temporal learning models, providing immediate enhancements. Experimental results demonstrate that LLMGeovec achieves global coverage and significantly boosts the performance of leading GP, LTSF, and GSTF models.
Read more8/23/2024