Where on Earth Do Users Say They Are?: Geo-Entity Linking for Noisy Multilingual User Input

0

Sign in to get full access
Overview
- This paper explores the challenge of linking noisy, multilingual user input to geographic entities (locations) on a global scale.
- The authors propose a novel geo-entity linking approach that can handle user-generated text with spelling errors, abbreviations, and multilingual content.
- They evaluate their method on a diverse dataset of user-generated content and show it outperforms existing geo-entity linking systems.
Plain English Explanation
When people talk or write online, they often mention places where they are or things they are doing. For example, someone might say "I'm in London for work this week" or "Grabbing coffee at the cafe down the street." Geo-entity linking is the process of automatically identifying these geographic references (like "London" or "the cafe down the street") and linking them to actual geographic locations on a map.
This is a challenging problem because user-generated text can be "noisy" - it often contains spelling errors, abbreviations, and can be in multiple languages. Existing geo-entity linking systems struggle with this type of unstructured, error-prone text.
The researchers in this paper developed a new approach to tackle this problem. Their method can handle messy, multilingual user input and accurately link it to the correct geographic entities around the world. They show their system outperforms previous geo-entity linking approaches, especially on datasets that mirror the types of user-generated content found online.
This work is important because accurately linking geographic references in user text has many real-world applications, like improving locationbased services, understanding human mobility patterns, and measuring the geographic diversity of online conversations. The authors' novel geo-entity linking technique represents an important advancement in this area.
Technical Explanation
The key innovation in this paper is a geo-entity linking model that can handle noisy, multilingual user-generated input. The model consists of three main components:
-
Candidate Generation: This component uses a combination of string matching, phonetic encoding, and knowledge graph lookup to identify a set of plausible geographic entity candidates for each mention in the input text.
-
Ranking: A neural network-based ranking model then scores each candidate entity based on features like textual similarity, geographic proximity, and entity type. This allows the system to select the most likely geographic referent.
-
Disambiguation: Finally, the model uses a collective inference approach to jointly disambiguate all entity mentions in the input, leveraging the relationships between them.
The authors evaluate their geo-entity linking system on a diverse dataset of user-generated content from social media, travel reviews, and online forums. They show it significantly outperforms previous state-of-the-art methods, especially on noisy inputs with spelling errors, abbreviations, and multilingual content.
Critical Analysis
A key strength of this work is the authors' focus on real-world, user-generated data, which poses significant challenges for existing geo-entity linking systems. By developing a model that can handle such "messy" inputs, the researchers have created a valuable tool for applications like location-based services and geographic diversity analysis.
That said, the authors acknowledge several limitations of their approach. For example, the model may struggle with very short or highly ambiguous geographic references, and its performance could be further improved by incorporating additional signals like user location history or multimodal information (e.g., images).
Additionally, while the authors demonstrate the effectiveness of their approach on a diverse test set, it would be valuable to see how the model generalizes to other types of user-generated content, such as private messages or specialized forums. Continued research in this direction could lead to even more robust and widely applicable geo-entity linking systems.
Conclusion
This paper presents a novel geo-entity linking system that can effectively handle noisy, multilingual user-generated text. By developing a model that can accurately identify and link geographic references in messy online content, the researchers have made an important contribution to the field of location-based services and geographic analysis of user-generated data.
The authors' innovative approach, combined with their thorough evaluation on realistic datasets, represents a significant advancement in the state of the art for geo-entity linking. As user-generated content continues to grow in importance, this work will likely have a meaningful impact on a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Where on Earth Do Users Say They Are?: Geo-Entity Linking for Noisy Multilingual User Input
Tessa Masis, Brendan O'Connor
Geo-entity linking is the task of linking a location mention to the real-world geographic location. In this paper we explore the challenging task of geo-entity linking for noisy, multilingual social media data. There are few open-source multilingual geo-entity linking tools available and existing ones are often rule-based, which break easily in social media settings, or LLM-based, which are too expensive for large-scale datasets. We present a method which represents real-world locations as averaged embeddings from labeled user-input location names and allows for selective prediction via an interpretable confidence score. We show that our approach improves geo-entity linking on a global and multilingual social media dataset, and discuss progress and problems with evaluating at different geographic granularities.
Read more4/30/2024
0
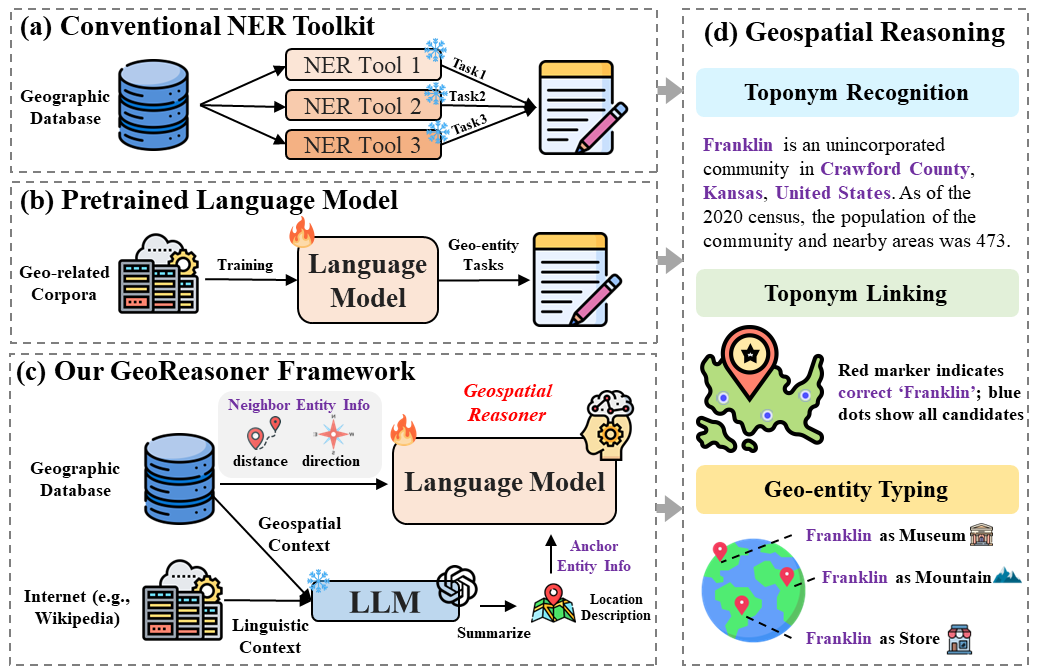
GeoReasoner: Reasoning On Geospatially Grounded Context For Natural Language Understanding
Yibo Yan, Joey Lee
In human reading and communication, individuals tend to engage in geospatial reasoning, which involves recognizing geographic entities and making informed inferences about their interrelationships. To mimic such cognitive process, current methods either utilize conventional natural language understanding toolkits, or directly apply models pretrained on geo-related natural language corpora. However, these methods face two significant challenges: i) they do not generalize well to unseen geospatial scenarios, and ii) they overlook the importance of integrating geospatial context from geographical databases with linguistic information from the Internet. To handle these challenges, we propose GeoReasoner, a language model capable of reasoning on geospatially grounded natural language. Specifically, it first leverages Large Language Models (LLMs) to generate a comprehensive location description based on linguistic and geospatial information. It also encodes direction and distance information into spatial embedding via treating them as pseudo-sentences. Consequently, the model is trained on both anchor-level and neighbor-level inputs to learn geo-entity representation. Extensive experimental results demonstrate GeoReasoner's superiority in three tasks: toponym recognition, toponym linking, and geo-entity typing, compared to the state-of-the-art baselines.
Read more8/22/2024
0
Leveraging Large Language Models to Geolocate Linguistic Variations in Social Media Posts
Davide Savarro, Davide Zago, Stefano Zoia
Geolocalization of social media content is the task of determining the geographical location of a user based on textual data, that may show linguistic variations and informal language. In this project, we address the GeoLingIt challenge of geolocalizing tweets written in Italian by leveraging large language models (LLMs). GeoLingIt requires the prediction of both the region and the precise coordinates of the tweet. Our approach involves fine-tuning pre-trained LLMs to simultaneously predict these geolocalization aspects. By integrating innovative methodologies, we enhance the models' ability to understand the nuances of Italian social media text to improve the state-of-the-art in this domain. This work is conducted as part of the Large Language Models course at the Bertinoro International Spring School 2024. We make our code publicly available on GitHub https://github.com/dawoz/geolingit-biss2024.
Read more7/24/2024
🧠
0
Geolocation Predicting of Tweets Using BERT-Based Models
Kateryna Lutsai, Christoph H. Lampert
This research is aimed to solve the tweet/user geolocation prediction task and provide a flexible methodology for the geotagging of textual big data. The suggested approach implements neural networks for natural language processing (NLP) to estimate the location as coordinate pairs (longitude, latitude) and two-dimensional Gaussian Mixture Models (GMMs). The scope of proposed models has been finetuned on a Twitter dataset using pretrained Bidirectional Encoder Representations from Transformers (BERT) as base models. Performance metrics show a median error of fewer than 30 km on a worldwide-level, and fewer than 15 km on the US-level datasets for the models trained and evaluated on text features of tweets' content and metadata context. Our source code and data are available at https://github.com/K4TEL/geo-twitter.git
Read more8/2/2024