Predicting Question Quality on StackOverflow with Neural Networks

0
🧠
Sign in to get full access
Overview
- The research evaluates neural network models to predict the quality of questions on the popular programming Q&A platform, Stack Overflow.
- The study compares the performance of neural network models to baseline machine learning models, finding that the neural networks achieve an accuracy of 80%.
- The paper also explores how the number of layers in the neural network can significantly impact its performance.
Plain English Explanation
The internet and social media platforms have made an unprecedented amount of information available to us. One popular website for programmers and developers is Stack Overflow, where users can ask and answer questions about coding and computing issues.
However, like many online communities, Stack Overflow contains a mix of helpful and less relevant information. This research looked at using neural network models to predict the quality of questions posted on the site. The researchers wanted to see if these advanced AI models could effectively identify high-quality questions that would be most useful to users.
The results showed that the neural network models outperformed traditional machine learning approaches, achieving an accuracy of 80% in their predictions. Interestingly, the study also found that the number of layers in the neural network had a significant impact on its performance.
This research demonstrates the potential for AI to help curate and organize the wealth of information available online, making it easier for users to find the most relevant and valuable content. By automatically assessing the quality of questions, these models could help improve the user experience on Q&A platforms like Stack Overflow.
Technical Explanation
The researchers in this study leveraged neural network models to predict the quality of questions on the Stack Overflow platform, which serves as an example of a Question Answering (QA) community. They compared the performance of neural network models to baseline machine learning approaches, finding that the neural networks achieved an impressive accuracy of 80% in their predictions.
A key insight from the research was that the number of layers in the neural network architecture had a significant impact on the model's performance. This suggests that the depth and complexity of the neural network can be an important factor in effectively solving QA-related tasks.
The researchers used a variety of features to train their models, including textual characteristics of the questions, user engagement metrics, and other contextual information. By building robust neural network models, they were able to outperform traditional machine learning approaches in predicting question quality on the Stack Overflow platform.
Critical Analysis
The research provides valuable insights into the potential of neural network models for assessing the quality of content in QA communities. However, the study does acknowledge some limitations, such as the specific domain of Stack Overflow and the potential for biases in the user-generated data.
Additionally, while the neural network models outperformed the baseline approaches, the overall accuracy of 80% still leaves room for improvement. Further research could explore additional features, model architectures, or techniques to enhance the performance of these quality prediction systems.
It would also be interesting to see how these models might generalize to other QA platforms or online communities beyond programming-focused sites. Applying these techniques in more diverse settings could yield important insights and help develop more robust solutions for improving the user experience in information-rich online environments.
Overall, this research demonstrates the promise of AI-powered approaches for curating and organizing user-generated content. As the volume of information continues to grow, tools like the ones explored in this study could play a crucial role in helping people find the most relevant and high-quality information to meet their needs.
Conclusion
This research paper explores the use of neural network models to predict the quality of questions on the popular programming Q&A platform, Stack Overflow. The results show that these advanced AI models can outperform traditional machine learning approaches, achieving an accuracy of 80% in their quality predictions.
Notably, the study also found that the number of layers in the neural network architecture can significantly impact its performance. This suggests that the depth and complexity of the model design can be an important factor in effectively solving QA-related tasks.
While the research has some limitations, it demonstrates the potential for AI-powered systems to help curate and organize the wealth of user-generated content available online. By automatically assessing the quality of information, these models could improve the user experience on platforms like Stack Overflow and make it easier for people to find the most relevant and valuable content.
As the volume of online information continues to grow, tools like the ones explored in this study could play a crucial role in helping people navigate the digital landscape and access the most high-quality and useful information to meet their needs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
Predicting Question Quality on StackOverflow with Neural Networks
Mohammad Al-Ramahi, Izzat Alsmadi, Abdullah Wahbeh
The wealth of information available through the Internet and social media is unprecedented. Within computing fields, websites such as Stack Overflow are considered important sources for users seeking solutions to their computing and programming issues. However, like other social media platforms, Stack Overflow contains a mixture of relevant and irrelevant information. In this paper, we evaluated neural network models to predict the quality of questions on Stack Overflow, as an example of Question Answering (QA) communities. Our results demonstrate the effectiveness of neural network models compared to baseline machine learning models, achieving an accuracy of 80%. Furthermore, our findings indicate that the number of layers in the neural network model can significantly impact its performance.
Read more4/24/2024
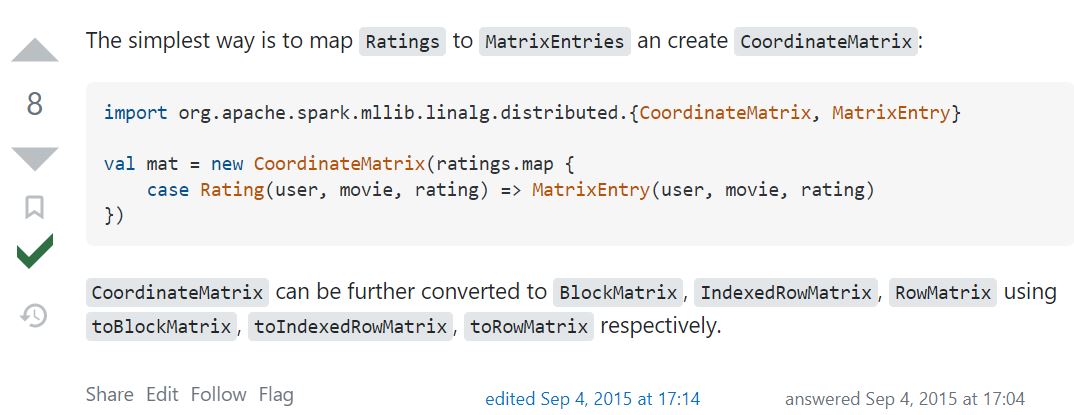
0
Studying and Recommending Information Highlighting in Stack Overflow Answers
Shahla Shaan Ahmed (Peter), Shaowei Wang (Peter), Yuan Tian (Peter), Tse-Hsun (Peter), Chen, Haoxiang Zhang
Context: Navigating the knowledge of Stack Overflow (SO) remains challenging. To make the posts vivid to users, SO allows users to write and edit posts with Markdown or HTML so that users can leverage various formatting styles (e.g., bold, italic, and code) to highlight the important information. Nonetheless, there have been limited studies on the highlighted information. Objective: We carried out the first large-scale exploratory study on the information highlighted in SO answers in our recent study. To extend our previous study, we develop approaches to automatically recommend highlighted content with formatting styles using neural network architectures initially designed for the Named Entity Recognition task. Method: In this paper, we studied 31,169,429 answers of Stack Overflow. For training recommendation models, we choose CNN-based and BERT-based models for each type of formatting (i.e., Bold, Italic, Code, and Heading) using the information highlighting dataset we collected from SO answers. Results: Our models achieve a precision ranging from 0.50 to 0.72 for different formatting types. It is easier to build a model to recommend Code than other types. Models for text formatting types (i.e., Heading, Bold, and Italic) suffer low recall. Our analysis of failure cases indicates that the majority of the failure cases are due to missing identification. One explanation is that the models are easy to learn the frequent highlighted words while struggling to learn less frequent words (i.g., long-tail knowledge). Conclusion: Our findings suggest that it is possible to develop recommendation models for highlighting information for answers with different formatting styles on Stack Overflow.
Read more4/29/2024

0
Evaluating the Quality of Answers in Political Q&A Sessions with Large Language Models
R. Michael Alvarez, Jacob Morrier
This paper introduces a new approach for measuring the quality of answers in political question-and-answer sessions. We propose to measure answer quality based on the degree to which it allows to infer the initial question accurately. This measure of answer quality reflects how well the answer engages with and addresses the initial question. Drawing an analogy with semantic search, we demonstrate that this measurement approach can be implemented by fine-tuning a large language model on the corpus of observed questions and answers without additional labeled data. We showcase our approach within the context of the Question Period in the Canadian House of Commons, providing valuable insights into the correlates of answer quality. Our findings reveal significant variations in answer quality based on the party affiliation of the members of Parliament asking the question. Additionally, we find a meaningful correlation between answer quality and the topic raised in the question.
Read more8/29/2024

0
StackOverflowVQA: Stack Overflow Visual Question Answering Dataset
Motahhare Mirzaei, Mohammad Javad Pirhadi, Sauleh Eetemadi
In recent years, people have increasingly used AI to help them with their problems by asking questions on different topics. One of these topics can be software-related and programming questions. In this work, we focus on the questions which need the understanding of images in addition to the question itself. We introduce the StackOverflowVQA dataset, which includes questions from StackOverflow that have one or more accompanying images. This is the first VQA dataset that focuses on software-related questions and contains multiple human-generated full-sentence answers. Additionally, we provide a baseline for answering the questions with respect to images in the introduced dataset using the GIT model. All versions of the dataset are available at https://huggingface.co/mirzaei2114.
Read more5/20/2024