Prediction-Feedback DETR for Temporal Action Detection

0
Sign in to get full access
Overview
- The paper proposes a new model called Prediction-Feedback DETR (PF-DETR) for temporal action detection in videos.
- PF-DETR combines the DETR (Detector Transformers) architecture with a novel prediction-feedback mechanism to improve temporal action detection performance.
- The key idea is to iteratively refine the predicted temporal action proposals based on feedback from the model's own predictions.
Plain English Explanation
Temporal action detection is the task of identifying and localizing actions in video sequences. This is an important problem in computer vision with applications in areas like video surveillance, sports analytics, and video understanding.
The proposed PF-DETR model works by first generating an initial set of temporal action proposals. It then iteratively refines these proposals based on feedback from the model's own predictions. This prediction-feedback loop allows the model to progressively improve its understanding of the video content and make more accurate action detections.
The DETR architecture used as the backbone of PF-DETR is well-suited for this task because it can efficiently process the entire video sequence and model the relationships between different actions. The prediction-feedback mechanism then helps the model focus on the most relevant temporal regions and refine its predictions accordingly.
Technical Explanation
The key technical components of PF-DETR are:
-
DETR Backbone: PF-DETR uses the DETR architecture as its base, which consists of a convolutional neural network encoder and a transformer-based decoder. This allows the model to capture both spatial and temporal information in the video.
-
Prediction-Feedback Mechanism: After the initial action proposals are generated, PF-DETR enters a iterative prediction-feedback loop. In each iteration, the model uses its previous predictions to refine the input features and generate updated action proposals. This feedback process helps the model converge to more accurate temporal action detections.
-
Optimization: PF-DETR is trained end-to-end using a combination of detection, localization, and classification losses. The prediction-feedback mechanism is also incorporated into the training process to encourage the model to learn effective refinement strategies.
The experiments conducted in the paper demonstrate that PF-DETR outperforms state-of-the-art temporal action detection methods on several benchmark datasets. The prediction-feedback approach is shown to be particularly effective for long-range and complex action sequences.
Critical Analysis
The paper provides a thorough evaluation of PF-DETR and compares it to other leading temporal action detection models. However, a few limitations and areas for future work are worth noting:
-
Dataset Bias: The experiments are conducted on standard benchmark datasets, which may not fully capture the diversity and complexity of real-world video data. Further testing on more diverse and challenging datasets would be valuable.
-
Computational Efficiency: The iterative prediction-feedback mechanism adds computational overhead to the model, which could limit its deployment in some real-time applications. Exploring ways to improve the efficiency of this process would be an interesting direction for future research.
-
Generalization: While PF-DETR demonstrates strong performance, it would be useful to investigate how well the model generalizes to different video domains and action types. Evaluating its robustness and adaptability would provide a more comprehensive understanding of its capabilities.
Conclusion
The Prediction-Feedback DETR model proposed in this paper represents an innovative approach to temporal action detection in videos. By leveraging the strengths of the DETR architecture and introducing a novel prediction-feedback mechanism, PF-DETR is able to achieve state-of-the-art performance on benchmark datasets.
The ability to iteratively refine action proposals based on the model's own predictions is a key contribution of this work, as it allows PF-DETR to better capture the complex temporal dynamics of video content. This technique could have broader applications in other video understanding tasks, such as action recognition and video summarization.
Overall, the Prediction-Feedback DETR model demonstrates the potential of integrating advanced transformer-based architectures with iterative refinement mechanisms for tackling complex computer vision problems. As the field of video understanding continues to evolve, research like this will play a crucial role in developing more robust and versatile AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Prediction-Feedback DETR for Temporal Action Detection
Jihwan Kim, Miso Lee, Cheol-Ho Cho, Jihyun Lee, Jae-Pil Heo
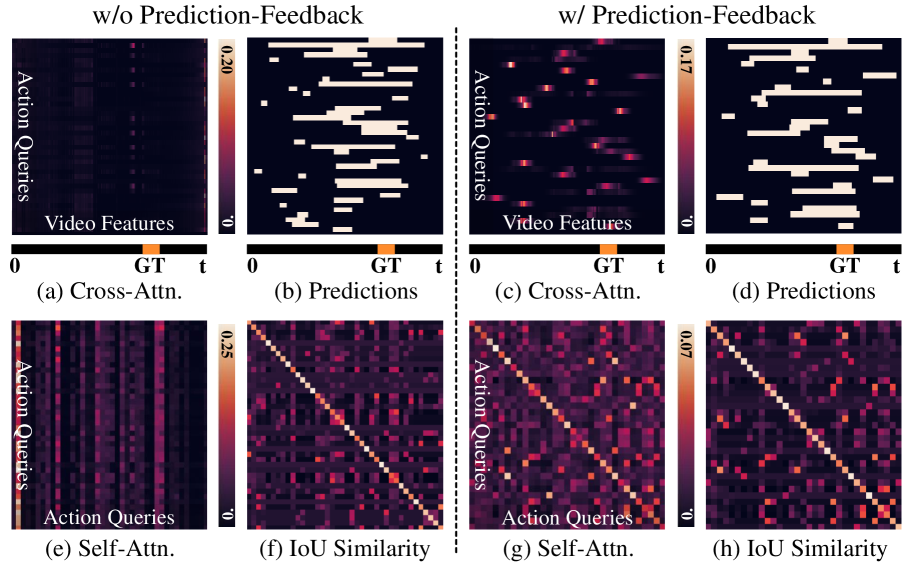
Temporal Action Detection (TAD) is fundamental yet challenging for real-world video applications. Leveraging the unique benefits of transformers, various DETR-based approaches have been adopted in TAD. However, it has recently been identified that the attention collapse in self-attention causes the performance degradation of DETR for TAD. Building upon previous research, this paper newly addresses the attention collapse problem in cross-attention within DETR-based TAD methods. Moreover, our findings reveal that cross-attention exhibits patterns distinct from predictions, indicating a short-cut phenomenon. To resolve this, we propose a new framework, Prediction-Feedback DETR (Pred-DETR), which utilizes predictions to restore the collapse and align the cross- and self-attention with predictions. Specifically, we devise novel prediction-feedback objectives using guidance from the relations of the predictions. As a result, Pred-DETR significantly alleviates the collapse and achieves state-of-the-art performance among DETR-based methods on various challenging benchmarks including THUMOS14, ActivityNet-v1.3, HACS, and FineAction.
Read more9/10/2024

0
Long-Term Pre-training for Temporal Action Detection with Transformers
Jihwan Kim, Miso Lee, Jae-Pil Heo
Temporal action detection (TAD) is challenging, yet fundamental for real-world video applications. Recently, DETR-based models for TAD have been prevailing thanks to their unique benefits. However, transformers demand a huge dataset, and unfortunately data scarcity in TAD causes a severe degeneration. In this paper, we identify two crucial problems from data scarcity: attention collapse and imbalanced performance. To this end, we propose a new pre-training strategy, Long-Term Pre-training (LTP), tailored for transformers. LTP has two main components: 1) class-wise synthesis, 2) long-term pretext tasks. Firstly, we synthesize long-form video features by merging video snippets of a target class and non-target classes. They are analogous to untrimmed data used in TAD, despite being created from trimmed data. In addition, we devise two types of long-term pretext tasks to learn long-term dependency. They impose long-term conditions such as finding second-to-fourth or short-duration actions. Our extensive experiments show state-of-the-art performances in DETR-based methods on ActivityNet-v1.3 and THUMOS14 by a large margin. Moreover, we demonstrate that LTP significantly relieves the data scarcity issues in TAD.
Read more9/10/2024
0
Spatial-Temporal Graph Enhanced DETR Towards Multi-Frame 3D Object Detection
Yifan Zhang, Zhiyu Zhu, Junhui Hou, Dapeng Wu
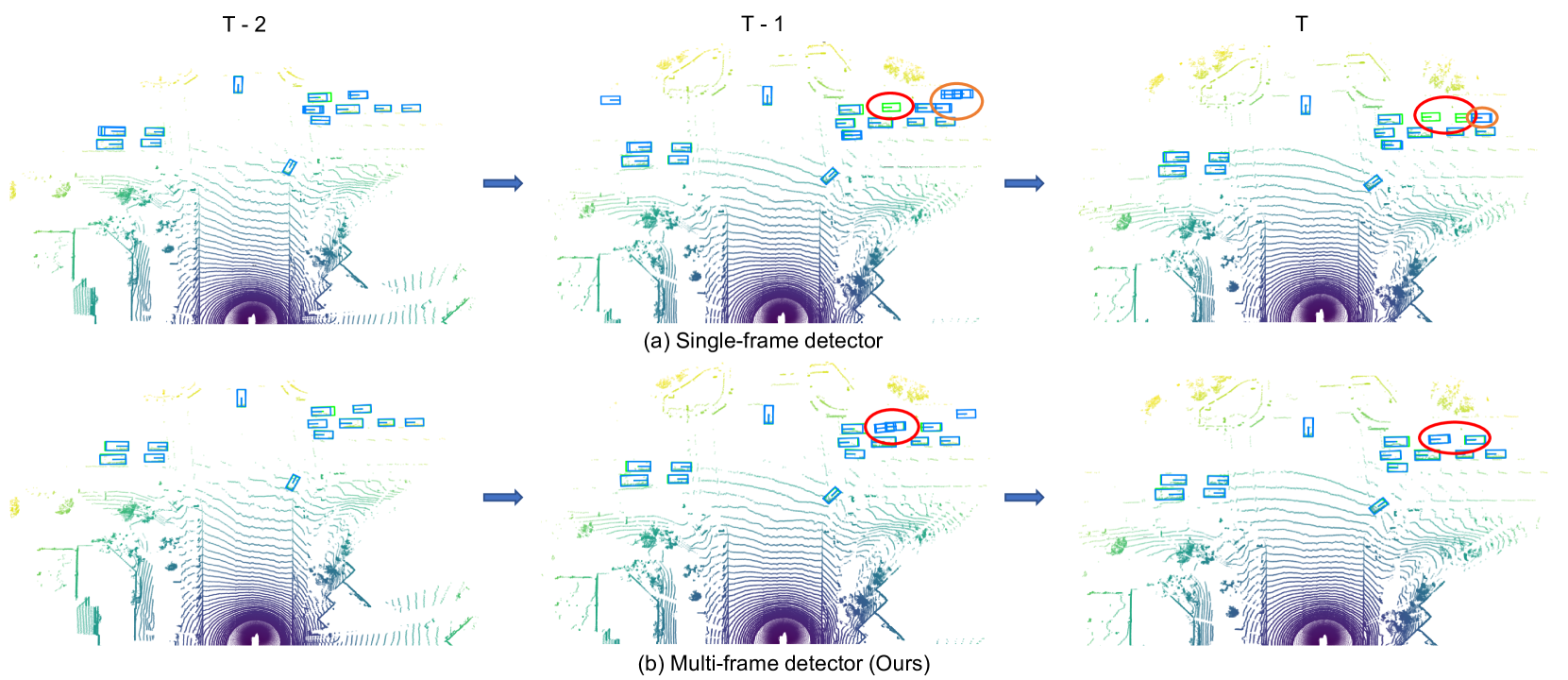
The Detection Transformer (DETR) has revolutionized the design of CNN-based object detection systems, showcasing impressive performance. However, its potential in the domain of multi-frame 3D object detection remains largely unexplored. In this paper, we present STEMD, a novel end-to-end framework that enhances the DETR-like paradigm for multi-frame 3D object detection by addressing three key aspects specifically tailored for this task. First, to model the inter-object spatial interaction and complex temporal dependencies, we introduce the spatial-temporal graph attention network, which represents queries as nodes in a graph and enables effective modeling of object interactions within a social context. To solve the problem of missing hard cases in the proposed output of the encoder in the current frame, we incorporate the output of the previous frame to initialize the query input of the decoder. Finally, it poses a challenge for the network to distinguish between the positive query and other highly similar queries that are not the best match. And similar queries are insufficiently suppressed and turn into redundant prediction boxes. To address this issue, our proposed IoU regularization term encourages similar queries to be distinct during the refinement. Through extensive experiments, we demonstrate the effectiveness of our approach in handling challenging scenarios, while incurring only a minor additional computational overhead. The code is publicly available at https://github.com/Eaphan/STEMD.
Read more8/14/2024
0
Adapting Short-Term Transformers for Action Detection in Untrimmed Videos
Min Yang, Huan Gao, Ping Guo, Limin Wang
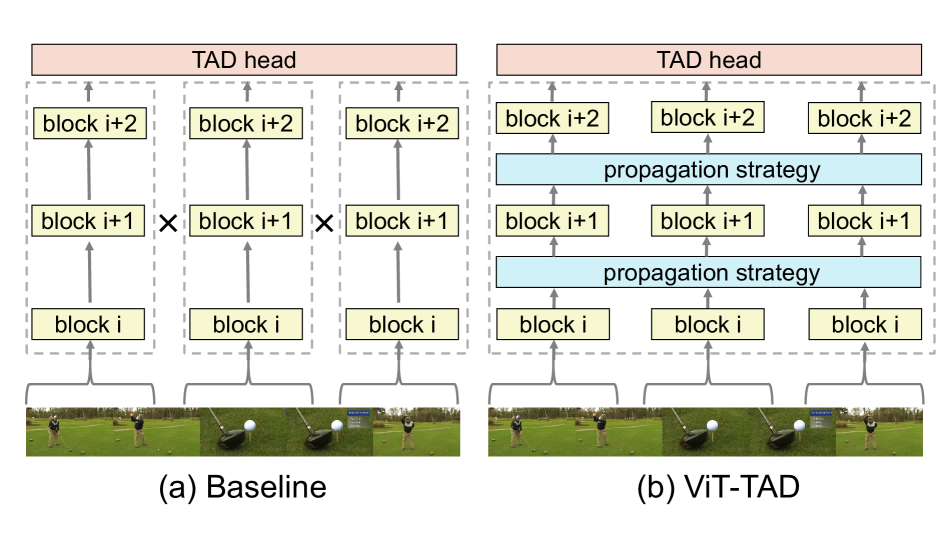
Vision Transformer (ViT) has shown high potential in video recognition, owing to its flexible design, adaptable self-attention mechanisms, and the efficacy of masked pre-training. Yet, it remains unclear how to adapt these pre-trained short-term ViTs for temporal action detection (TAD) in untrimmed videos. The existing works treat them as off-the-shelf feature extractors for each short-trimmed snippet without capturing the fine-grained relation among different snippets in a broader temporal context. To mitigate this issue, this paper focuses on designing a new mechanism for adapting these pre-trained ViT models as a unified long-form video transformer to fully unleash its modeling power in capturing inter-snippet relation, while still keeping low computation overhead and memory consumption for efficient TAD. To this end, we design effective cross-snippet propagation modules to gradually exchange short-term video information among different snippets from two levels. For inner-backbone information propagation, we introduce a cross-snippet propagation strategy to enable multi-snippet temporal feature interaction inside the backbone.For post-backbone information propagation, we propose temporal transformer layers for further clip-level modeling. With the plain ViT-B pre-trained with VideoMAE, our end-to-end temporal action detector (ViT-TAD) yields a very competitive performance to previous temporal action detectors, riching up to 69.5 average mAP on THUMOS14, 37.40 average mAP on ActivityNet-1.3 and 17.20 average mAP on FineAction.
Read more4/16/2024