Prioritized experience replay-based DDQN for Unmanned Vehicle Path Planning
2406.17286
0
0
↗️
Abstract
Path planning module is a key module for autonomous vehicle navigation, which directly affects its operating efficiency and safety. In complex environments with many obstacles, traditional planning algorithms often cannot meet the needs of intelligence, which may lead to problems such as dead zones in unmanned vehicles. This paper proposes a path planning algorithm based on DDQN and combines it with the prioritized experience replay method to solve the problem that traditional path planning algorithms often fall into dead zones. A series of simulation experiment results prove that the path planning algorithm based on DDQN is significantly better than other methods in terms of speed and accuracy, especially the ability to break through dead zones in extreme environments. Research shows that the path planning algorithm based on DDQN performs well in terms of path quality and safety. These research results provide an important reference for the research on automatic navigation of autonomous vehicles.
Create account to get full access
Overview
- The paper proposes a path planning algorithm for autonomous vehicles based on Deep Double Q-Network (DDQN) and prioritized experience replay.
- The algorithm aims to address the limitations of traditional path planning algorithms, which often struggle in complex environments with many obstacles, leading to "dead zones" for unmanned vehicles.
- The researchers conducted simulations to evaluate the performance of the DDQN-based algorithm, comparing it to other methods.
Plain English Explanation
The paper focuses on path planning, which is a crucial component for autonomous vehicle navigation. This module determines the vehicle's route and directly affects its efficiency and safety. In complex environments with many obstacles, traditional path planning algorithms may not be able to handle the complexity, leading to "dead zones" where the vehicle gets stuck and cannot proceed.
To address this issue, the researchers developed a new path planning algorithm based on a Deep Reinforcement Learning technique called Deep Double Q-Network (DDQN). DDQN is a type of reinforcement learning algorithm that can learn to navigate complex environments by trial and error, similar to how a human driver might learn to navigate a new city.
The researchers also combined the DDQN algorithm with a technique called prioritized experience replay, which helps the algorithm learn more efficiently from its experiences. This helps the vehicle avoid getting stuck in dead zones, even in very challenging environments.
The researchers conducted a series of simulations to test the performance of their DDQN-based path planning algorithm. They found that it significantly outperformed other methods in terms of speed and accuracy, particularly in its ability to navigate through the tough "dead zones" that can trap traditional algorithms.
Overall, the research demonstrates that the DDQN-based path planning algorithm can provide a robust and effective solution for autonomous vehicle navigation, even in complex environments with many obstacles. This could have important implications for the development of safe and efficient self-driving cars and other autonomous vehicles.
Technical Explanation
The paper presents a path planning algorithm for autonomous vehicles based on Deep Double Q-Network (DDQN) and prioritized experience replay. DDQN is a type of deep reinforcement learning algorithm that can learn to navigate complex environments by trial and error.
The researchers designed a simulation environment to test their DDQN-based path planning algorithm. This environment included various obstacles that the autonomous vehicle had to navigate around. The algorithm was trained using the prioritized experience replay method, which helps it learn more efficiently from its experiences.
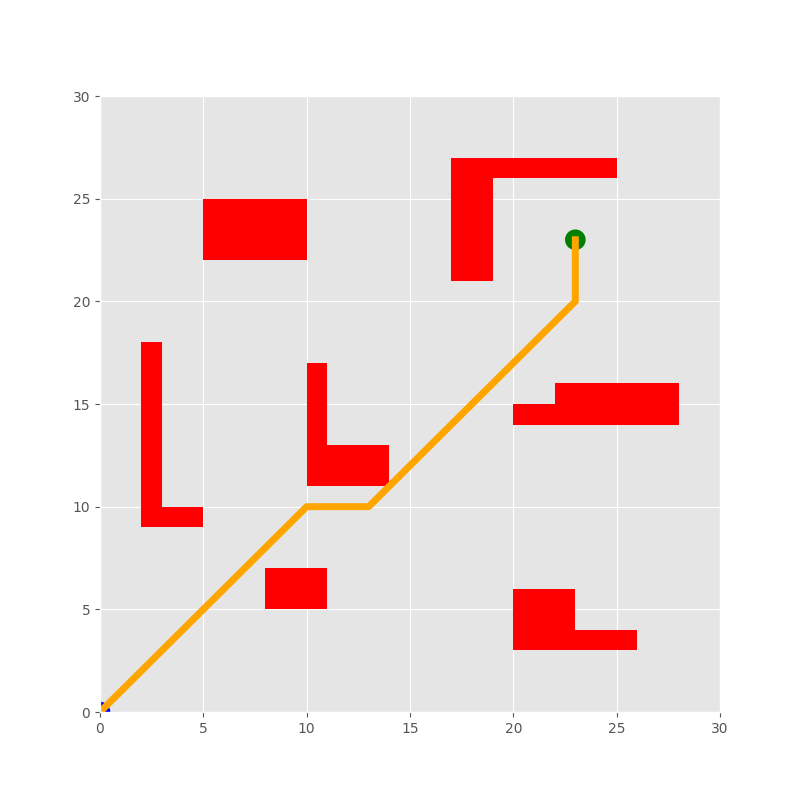
Through a series of simulation experiments, the researchers compared the performance of their DDQN-based algorithm to other traditional path planning methods. The results showed that the DDQN-based algorithm significantly outperformed the other methods in terms of speed, accuracy, and the ability to navigate through "dead zones" - areas where the vehicle would get stuck using traditional algorithms.
The paper provides detailed technical insights into the architecture and training process of the DDQN-based path planning algorithm. It also presents the experimental setup and the metrics used to evaluate the algorithm's performance.
Critical Analysis
The paper provides a compelling solution to the challenge of path planning for autonomous vehicles in complex environments. The use of DDQN, combined with prioritized experience replay, appears to be an effective approach for enabling vehicles to navigate through tight spaces and avoid getting stuck in dead zones.
However, the paper does not address some potential limitations of the proposed approach. For example, it is unclear how the algorithm would perform in real-world scenarios, where the environment may be more dynamic and unpredictable than the simulated setting. Additionally, the paper does not discuss the computational complexity and resource requirements of the DDQN-based algorithm, which could be a concern for deployment on resource-constrained autonomous vehicles.
Furthermore, the paper could have provided more insights into the failure cases or edge cases where the DDQN-based algorithm might struggle. A more comprehensive analysis of the algorithm's strengths and weaknesses would have helped readers better understand its practical applicability and limitations.
Despite these minor shortcomings, the research presented in the paper represents a significant contribution to the field of autonomous vehicle navigation. The DDQN-based path planning algorithm's demonstrated ability to navigate through complex environments and overcome dead zones is a notable achievement that could have important implications for the development of safe and efficient self-driving cars and other autonomous vehicles.
Conclusion
This paper presents a novel path planning algorithm for autonomous vehicles based on Deep Double Q-Network (DDQN) and prioritized experience replay. The proposed algorithm aims to address the limitations of traditional path planning methods, which often struggle in complex environments with many obstacles, leading to "dead zones" where the vehicle gets stuck.
The simulation experiments conducted by the researchers show that the DDQN-based algorithm significantly outperforms other methods in terms of speed, accuracy, and the ability to navigate through challenging environments. These findings suggest that the DDQN-based path planning approach could be a promising solution for enabling autonomous vehicles to navigate safely and efficiently, even in complex real-world scenarios.
The research presented in this paper provides an important reference for the development of autonomous vehicle navigation systems and could have far-reaching implications for the future of self-driving technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
Adaptive speed planning for Unmanned Vehicle Based on Deep Reinforcement Learning
Hao Liu, Yi Shen, Wenjing Zhou, Yuelin Zou, Chang Zhou, Shuyao He
0
0
In order to solve the problem of frequent deceleration of unmanned vehicles when approaching obstacles, this article uses a Deep Q-Network (DQN) and its extension, the Double Deep Q-Network (DDQN), to develop a local navigation system that adapts to obstacles while maintaining optimal speed planning. By integrating improved reward functions and obstacle angle determination methods, the system demonstrates significant enhancements in maneuvering capabilities without frequent decelerations. Experiments conducted in simulated environments with varying obstacle densities confirm the effectiveness of the proposed method in achieving more stable and efficient path planning.
4/29/2024
🏅
New!Research on Autonomous Robots Navigation based on Reinforcement Learning
Zixiang Wang, Hao Yan, Yining Wang, Zhengjia Xu, Zhuoyue Wang, Zhizhong Wu
0
0
Reinforcement learning continuously optimizes decision-making based on real-time feedback reward signals through continuous interaction with the environment, demonstrating strong adaptive and self-learning capabilities. In recent years, it has become one of the key methods to achieve autonomous navigation of robots. In this work, an autonomous robot navigation method based on reinforcement learning is introduced. We use the Deep Q Network (DQN) and Proximal Policy Optimization (PPO) models to optimize the path planning and decision-making process through the continuous interaction between the robot and the environment, and the reward signals with real-time feedback. By combining the Q-value function with the deep neural network, deep Q network can handle high-dimensional state space, so as to realize path planning in complex environments. Proximal policy optimization is a strategy gradient-based method, which enables robots to explore and utilize environmental information more efficiently by optimizing policy functions. These methods not only improve the robot's navigation ability in the unknown environment, but also enhance its adaptive and self-learning capabilities. Through multiple training and simulation experiments, we have verified the effectiveness and robustness of these models in various complex scenarios.
7/4/2024
🤿
Deep Reinforcement Learning for Mobile Robot Path Planning
Hao Liu, Yi Shen, Shuangjiang Yu, Zijun Gao, Tong Wu
0
0
Path planning is an important problem with the the applications in many aspects, such as video games, robotics etc. This paper proposes a novel method to address the problem of Deep Reinforcement Learning (DRL) based path planning for a mobile robot. We design DRL-based algorithms, including reward functions, and parameter optimization, to avoid time-consuming work in a 2D environment. We also designed an Two-way search hybrid A* algorithm to improve the quality of local path planning. We transferred the designed algorithm to a simple embedded environment to test the computational load of the algorithm when running on a mobile robot. Experiments show that when deployed on a robot platform, the DRL-based algorithm in this article can achieve better planning results and consume less computing resources.
4/11/2024
Multi-AGV Path Planning Method via Reinforcement Learning and Particle Filters
Shao Shuo
0
0
Thanks to its robust learning and search stabilities,the reinforcement learning (RL) algorithm has garnered increasingly significant attention and been exten-sively applied in Automated Guided Vehicle (AGV) path planning. However, RL-based planning algorithms have been discovered to suffer from the substantial variance of neural networks caused by environmental instability and significant fluctua-tions in system structure. These challenges manifest in slow convergence speed and low learning efficiency. To tackle this issue, this paper presents a novel multi-AGV path planning method named Particle Filters - Double Deep Q-Network (PF-DDQN)via leveraging Particle Filters (PF) and RL algorithm. Firstly, the proposed method leverages the imprecise weight values of the network as state values to formulate thestate space equation.Subsequently, the DDQN model is optimized to acquire the optimal true weight values through the iterative fusion process of neural networksand PF in order to enhance the optimization efficiency of the proposedmethod. Lastly, the performance of the proposed method is validated by different numerical simulations. The simulation results demonstrate that the proposed methoddominates the traditional DDQN algorithm in terms of path planning superiority andtraining time indicator by 92.62% and 76.88%, respectively. Therefore, the proposedmethod could be considered as a vital alternative in the field of multi-AGV path planning.
5/24/2024