ProgGen: Generating Named Entity Recognition Datasets Step-by-step with Self-Reflexive Large Language Models

0
Sign in to get full access
Overview
- This paper introduces ProgGen, a novel approach to generating named entity recognition (NER) datasets using self-reflexive large language models (LLMs).
- The method allows for step-by-step dataset generation, enabling greater control and customization compared to traditional data collection methods.
- The authors demonstrate the effectiveness of ProgGen on several NER benchmarks, showcasing its ability to augment existing datasets and improve model performance.
Plain English Explanation
The paper presents a new way to create datasets for a specific machine learning task called named entity recognition (NER). NER is the process of identifying and classifying important words or phrases in text, like people's names, locations, organizations, and so on.
Typically, creating these NER datasets involves manually annotating large amounts of text, which can be time-consuming and expensive. The researchers behind this paper have come up with a clever solution using large language models, which are powerful AI models trained on vast amounts of text data.
Their method, called ProgGen, allows the language model to essentially generate its own NER dataset in a step-by-step manner. This gives the researchers more control and flexibility compared to traditional data collection methods. They can customize the dataset to include specific types of entities or to match the characteristics of a particular domain, like biomedicine.
The researchers show that using ProgGen-generated datasets can improve the performance of NER models on several benchmark tasks. This is an important advancement, as having high-quality, diverse NER datasets is crucial for building robust and accurate NER systems that can be deployed in real-world applications.
Technical Explanation
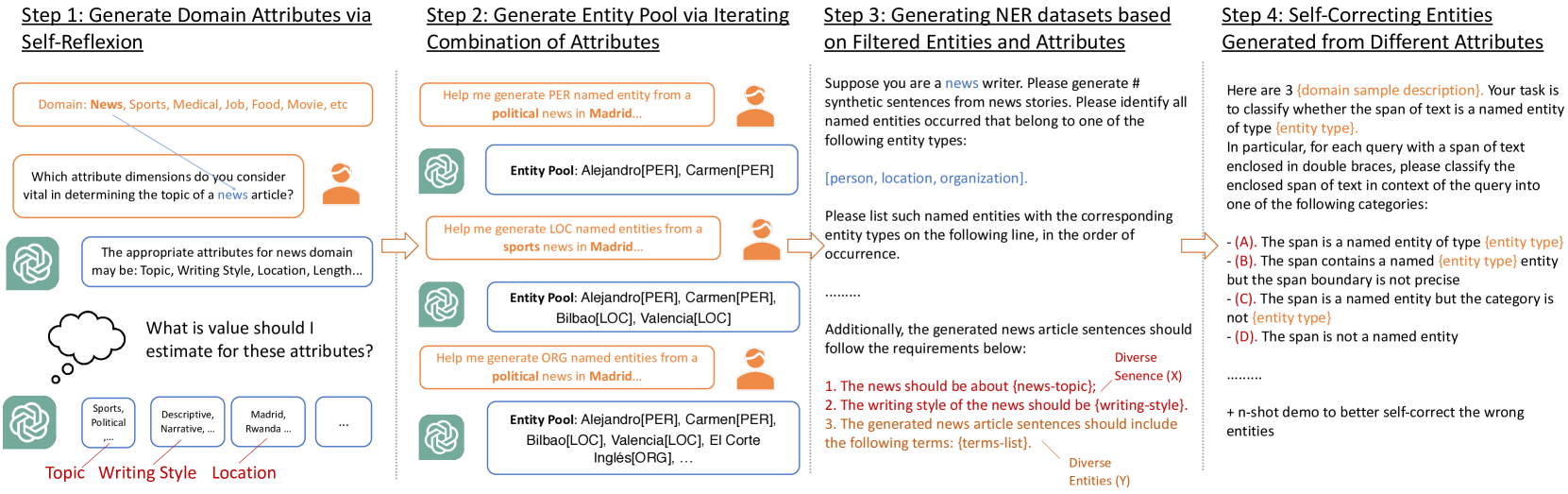
The key innovation of this paper is the ProgGen (Programmatic Generation) framework, which leverages the capabilities of self-reflexive large language models (LLMs) to generate step-by-step named entity recognition (NER) datasets.
The ProgGen approach works as follows:
- The researchers first fine-tune an LLM on a small seed dataset of labeled NER examples.
- They then use the fine-tuned model to generate new text, while simultaneously prompting it to identify and annotate named entities in the generated text.
- This process is repeated iteratively, with the model's annotations being used to update and expand the training dataset.
This step-by-step generation allows for greater control and customization compared to traditional data collection methods, which often rely on manual annotation or scraping text from the web.
The authors evaluate ProgGen on several NER benchmarks, including CoNLL 2003, OntoNotes 5.0, and domain-specific datasets. They demonstrate that ProgGen-generated datasets can outperform or match the performance of models trained on manually curated datasets, while also enabling zero-shot or few-shot NER in certain scenarios.
Critical Analysis
The ProgGen approach proposed in this paper is a promising step towards more automated and customizable dataset generation for NER tasks. By leveraging the capabilities of self-reflexive LLMs, the researchers have demonstrated a novel way to create high-quality NER datasets with greater control and flexibility.
However, the paper does not fully address some potential limitations and concerns with the approach:
- The quality and diversity of the generated datasets may be heavily dependent on the initial seed dataset and the fine-tuning process, which could introduce biases or skew the resulting data.
- The iterative nature of ProgGen could lead to compounding errors, where mistakes in the initial generations are propagated and amplified in subsequent iterations.
- The authors do not provide a comprehensive analysis of the generalization capabilities of ProgGen-generated datasets, particularly when applied to domains or entity types that are significantly different from the training data.
Further research is needed to address these concerns and explore the broader implications of using self-reflexive LLMs for dataset generation. Nonetheless, the ProgGen approach represents an important step forward in the quest for more efficient and customizable data collection methods for NER and other natural language processing tasks.
Conclusion
The ProgGen framework introduced in this paper offers a novel approach to generating named entity recognition (NER) datasets using self-reflexive large language models (LLMs). By enabling step-by-step dataset generation, ProgGen provides researchers and practitioners with greater control and customization capabilities compared to traditional data collection methods.
The authors demonstrate the effectiveness of ProgGen on several NER benchmarks, showing that the generated datasets can outperform or match the performance of manually curated datasets. This is a significant advancement, as high-quality, diverse NER datasets are crucial for building robust and accurate NER systems that can be deployed in real-world applications, such as biomedical text processing and entity matching.
While the ProgGen approach shows promise, further research is needed to address potential limitations and explore the broader implications of using self-reflexive LLMs for dataset generation. Nonetheless, this work represents an important step towards more efficient and customizable data collection methods for natural language processing tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ProgGen: Generating Named Entity Recognition Datasets Step-by-step with Self-Reflexive Large Language Models
Yuzhao Heng, Chunyuan Deng, Yitong Li, Yue Yu, Yinghao Li, Rongzhi Zhang, Chao Zhang
Although Large Language Models (LLMs) exhibit remarkable adaptability across domains, these models often fall short in structured knowledge extraction tasks such as named entity recognition (NER). This paper explores an innovative, cost-efficient strategy to harness LLMs with modest NER capabilities for producing superior NER datasets. Our approach diverges from the basic class-conditional prompts by instructing LLMs to self-reflect on the specific domain, thereby generating domain-relevant attributes (such as category and emotions for movie reviews), which are utilized for creating attribute-rich training data. Furthermore, we preemptively generate entity terms and then develop NER context data around these entities, effectively bypassing the LLMs' challenges with complex structures. Our experiments across both general and niche domains reveal significant performance enhancements over conventional data generation methods while being more cost-effective than existing alternatives.
Read more6/11/2024
0
Augmenting NER Datasets with LLMs: Towards Automated and Refined Annotation
Yuji Naraki, Ryosuke Yamaki, Yoshikazu Ikeda, Takafumi Horie, Hiroki Naganuma
In the field of Natural Language Processing (NLP), Named Entity Recognition (NER) is recognized as a critical technology, employed across a wide array of applications. Traditional methodologies for annotating datasets for NER models are challenged by high costs and variations in dataset quality. This research introduces a novel hybrid annotation approach that synergizes human effort with the capabilities of Large Language Models (LLMs). This approach not only aims to ameliorate the noise inherent in manual annotations, such as omissions, thereby enhancing the performance of NER models, but also achieves this in a cost-effective manner. Additionally, by employing a label mixing strategy, it addresses the issue of class imbalance encountered in LLM-based annotations. Through an analysis across multiple datasets, this method has been consistently shown to provide superior performance compared to traditional annotation methods, even under constrained budget conditions. This study illuminates the potential of leveraging LLMs to improve dataset quality, introduces a novel technique to mitigate class imbalances, and demonstrates the feasibility of achieving high-performance NER in a cost-effective way.
Read more4/3/2024
💬
0
LTNER: Large Language Model Tagging for Named Entity Recognition with Contextualized Entity Marking
Faren Yan, Peng Yu, Xin Chen
The use of LLMs for natural language processing has become a popular trend in the past two years, driven by their formidable capacity for context comprehension and learning, which has inspired a wave of research from academics and industry professionals. However, for certain NLP tasks, such as NER, the performance of LLMs still falls short when compared to supervised learning methods. In our research, we developed a NER processing framework called LTNER that incorporates a revolutionary Contextualized Entity Marking Gen Method. By leveraging the cost-effective GPT-3.5 coupled with context learning that does not require additional training, we significantly improved the accuracy of LLMs in handling NER tasks. The F1 score on the CoNLL03 dataset increased from the initial 85.9% to 91.9%, approaching the performance of supervised fine-tuning. This outcome has led to a deeper understanding of the potential of LLMs.
Read more4/9/2024
👁️
0
LLM-DER:A Named Entity Recognition Method Based on Large Language Models for Chinese Coal Chemical Domain
Le Xiao, Yunfei Xu, Jing Zhao
Domain-specific Named Entity Recognition (NER), whose goal is to recognize domain-specific entities and their categories, provides an important support for constructing domain knowledge graphs. Currently, deep learning-based methods are widely used and effective in NER tasks, but due to the reliance on large-scale labeled data. As a result, the scarcity of labeled data in a specific domain will limit its application.Therefore, many researches started to introduce few-shot methods and achieved some results. However, the entity structures in specific domains are often complex, and the current few-shot methods are difficult to adapt to NER tasks with complex features.Taking the Chinese coal chemical industry domain as an example,there exists a complex structure of multiple entities sharing a single entity, as well as multiple relationships for the same pair of entities, which affects the NER task under the sample less condition.In this paper, we propose a Large Language Models (LLMs)-based entity recognition framework LLM-DER for the domain-specific entity recognition problem in Chinese, which enriches the entity information by generating a list of relationships containing entity types through LLMs, and designing a plausibility and consistency evaluation method to remove misrecognized entities, which can effectively solve the complex structural entity recognition problem in a specific domain.The experimental results of this paper on the Resume dataset and the self-constructed coal chemical dataset Coal show that LLM-DER performs outstandingly in domain-specific entity recognition, not only outperforming the existing GPT-3.5-turbo baseline, but also exceeding the fully-supervised baseline, verifying its effectiveness in entity recognition.
Read more9/17/2024