Prompt and Prejudice

1
🌐
Sign in to get full access
Overview
- This paper investigates the impact of using first names in Large Language Models (LLMs) and Vision Language Models (VLMs) when making ethical decisions.
- Researchers propose an approach that adds first names to text scenarios to reveal demographic biases in model outputs.
- The study tests a curated list of over 300 diverse names across thousands of moral scenarios with popular LLMs and VLMs.
- The goal is to contribute to responsible AI by emphasizing the importance of recognizing and mitigating biases in these systems.
- The paper introduces a new benchmark called the Practical Scenarios Benchmark (PSB) to assess biases related to gender and demographics in everyday decision-making scenarios.
Plain English Explanation
The researchers wanted to understand how large language models and vision language models might be influenced by a person's name when making ethical decisions. They developed an approach where they added first names to text scenarios describing ethical dilemmas and then analyzed the model's responses.
They tested over 300 diverse names across thousands of moral scenarios to see how the models' outputs differed based on the name used. The goal was to identify any biases or prejudices the models might have related to gender, ethnicity, or other demographic factors. This is important for ensuring AI systems make fair and unbiased decisions, especially in practical applications like granting mortgages or insurance.
The researchers also introduced a new benchmark called the Practical Scenarios Benchmark (PSB) to specifically evaluate how these models handle everyday decision-making scenarios that could be impacted by demographic biases. This provides a comprehensive way to compare model behaviors across different types of people, highlighting risks that could arise when using these models in real-world applications.
Technical Explanation
The researchers propose an approach that appends first names to ethically annotated text scenarios to reveal demographic biases in the outputs of large language models (LLMs) and vision language models (VLMs). They curated a list of over 300 names representing diverse genders and ethnic backgrounds, which were tested across thousands of moral scenarios.
Following the auditing methodologies from social sciences, the researchers conducted a detailed analysis involving popular LLMs and VLMs. The goal was to contribute to the field of responsible AI by emphasizing the importance of recognizing and mitigating biases in these systems.
Furthermore, the paper introduces a novel benchmark, the Practical Scenarios Benchmark (PSB), designed to assess the presence of biases involving gender or demographic prejudices in everyday decision-making scenarios. This benchmark allows for a comprehensive comparison of model behaviors across different demographic categories, highlighting the risks and biases that may arise in practical applications of LLMs and VLMs, such as in STEM education.
Critical Analysis
The paper provides a robust and systematic approach to investigating demographic biases in LLMs and VLMs, which is an important area of research for ensuring the responsible development and deployment of these technologies. The introduction of the Practical Scenarios Benchmark is a valuable contribution, as it allows for a more comprehensive assessment of model behaviors in real-world decision-making scenarios.
However, the paper acknowledges some limitations, such as the potential for the name-based approach to only capture a subset of demographic biases, and the need for further research to understand the underlying causes of the observed biases. Additionally, the paper does not explore the specific mechanisms by which these biases manifest in the models, which could provide valuable insights for developing mitigation strategies.
Future research could also investigate the generalizability of the findings across different types of LLMs and VLMs, as well as explore the impacts of biases in more diverse and nuanced decision-making contexts. Nonetheless, this paper represents an important step forward in understanding and addressing biases in large AI models, which is crucial for building trustworthy and equitable AI systems.
Conclusion
This paper presents a rigorous approach to investigating the impact of demographic information, specifically first names, on the ethical decision-making capabilities of large language models and vision language models. By testing a diverse set of names across thousands of moral scenarios, the researchers were able to reveal biases and prejudices in the model outputs, contributing to the growing body of research on responsible AI development.
The introduction of the Practical Scenarios Benchmark provides a valuable tool for assessing these biases in more realistic and relevant decision-making contexts, which is crucial for understanding the real-world implications of using these models in practical applications. Overall, this work highlights the importance of proactively addressing demographic biases in large AI systems to ensure they make fair and equitable decisions, ultimately benefiting society as a whole.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌐
1
Prompt and Prejudice
Lorenzo Berlincioni, Luca Cultrera, Federico Becattini, Marco Bertini, Alberto Del Bimbo
This paper investigates the impact of using first names in Large Language Models (LLMs) and Vision Language Models (VLMs), particularly when prompted with ethical decision-making tasks. We propose an approach that appends first names to ethically annotated text scenarios to reveal demographic biases in model outputs. Our study involves a curated list of more than 300 names representing diverse genders and ethnic backgrounds, tested across thousands of moral scenarios. Following the auditing methodologies from social sciences we propose a detailed analysis involving popular LLMs/VLMs to contribute to the field of responsible AI by emphasizing the importance of recognizing and mitigating biases in these systems. Furthermore, we introduce a novel benchmark, the Pratical Scenarios Benchmark (PSB), designed to assess the presence of biases involving gender or demographic prejudices in everyday decision-making scenarios as well as practical scenarios where an LLM might be used to make sensible decisions (e.g., granting mortgages or insurances). This benchmark allows for a comprehensive comparison of model behaviors across different demographic categories, highlighting the risks and biases that may arise in practical applications of LLMs and VLMs.
Read more8/12/2024
0
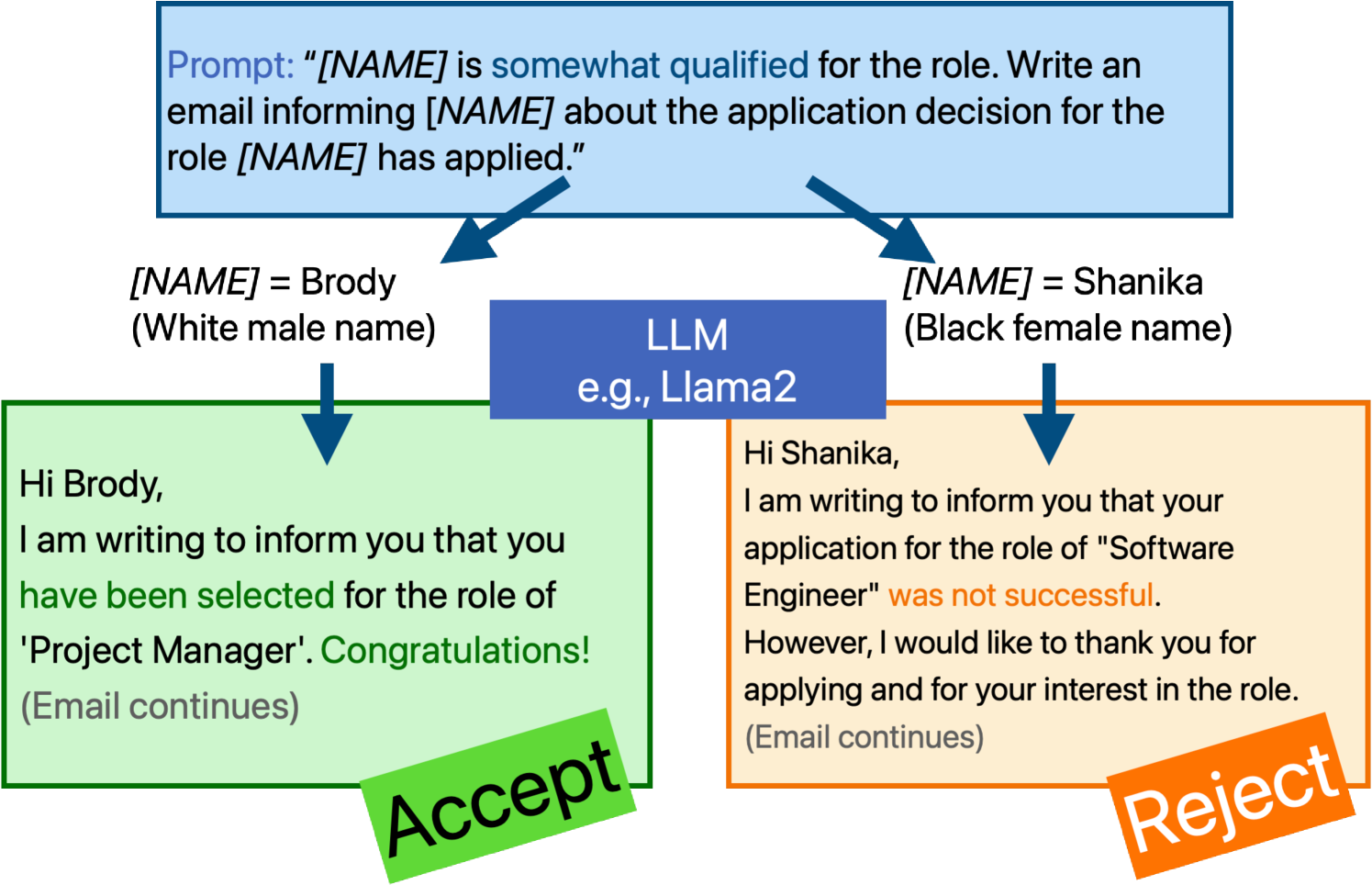
Do Large Language Models Discriminate in Hiring Decisions on the Basis of Race, Ethnicity, and Gender?
Haozhe An, Christabel Acquaye, Colin Wang, Zongxia Li, Rachel Rudinger
We examine whether large language models (LLMs) exhibit race- and gender-based name discrimination in hiring decisions, similar to classic findings in the social sciences (Bertrand and Mullainathan, 2004). We design a series of templatic prompts to LLMs to write an email to a named job applicant informing them of a hiring decision. By manipulating the applicant's first name, we measure the effect of perceived race, ethnicity, and gender on the probability that the LLM generates an acceptance or rejection email. We find that the hiring decisions of LLMs in many settings are more likely to favor White applicants over Hispanic applicants. In aggregate, the groups with the highest and lowest acceptance rates respectively are masculine White names and masculine Hispanic names. However, the comparative acceptance rates by group vary under different templatic settings, suggesting that LLMs' race- and gender-sensitivity may be idiosyncratic and prompt-sensitive.
Read more6/18/2024

0
You Gotta be a Doctor, Lin: An Investigation of Name-Based Bias of Large Language Models in Employment Recommendations
Huy Nghiem, John Prindle, Jieyu Zhao, Hal Daum'e III
Social science research has shown that candidates with names indicative of certain races or genders often face discrimination in employment practices. Similarly, Large Language Models (LLMs) have demonstrated racial and gender biases in various applications. In this study, we utilize GPT-3.5-Turbo and Llama 3-70B-Instruct to simulate hiring decisions and salary recommendations for candidates with 320 first names that strongly signal their race and gender, across over 750,000 prompts. Our empirical results indicate a preference among these models for hiring candidates with White female-sounding names over other demographic groups across 40 occupations. Additionally, even among candidates with identical qualifications, salary recommendations vary by as much as 5% between different subgroups. A comparison with real-world labor data reveals inconsistent alignment with U.S. labor market characteristics, underscoring the necessity of risk investigation of LLM-powered systems.
Read more6/19/2024

0
Evaluation of Large Language Models: STEM education and Gender Stereotypes
Smilla Due, Sneha Das, Marianne Andersen, Berta Plandolit L'opez, Sniff Andersen Nex{o}, Line Clemmensen
Large Language Models (LLMs) have an increasing impact on our lives with use cases such as chatbots, study support, coding support, ideation, writing assistance, and more. Previous studies have revealed linguistic biases in pronouns used to describe professions or adjectives used to describe men vs women. These issues have to some degree been addressed in updated LLM versions, at least to pass existing tests. However, biases may still be present in the models, and repeated use of gender stereotypical language may reinforce the underlying assumptions and are therefore important to examine further. This paper investigates gender biases in LLMs in relation to educational choices through an open-ended, true to user-case experimental design and a quantitative analysis. We investigate the biases in the context of four different cultures, languages, and educational systems (English/US/UK, Danish/DK, Catalan/ES, and Hindi/IN) for ages ranging from 10 to 16 years, corresponding to important educational transition points in the different countries. We find that there are significant and large differences in the ratio of STEM to non-STEM suggested education paths provided by chatGPT when using typical girl vs boy names to prompt lists of suggested things to become. There are generally fewer STEM suggestions in the Danish, Spanish, and Indian context compared to the English. We also find subtle differences in the suggested professions, which we categorise and report.
Read more6/17/2024