Prompt-Time Ontology-Driven Symbolic Knowledge Capture with Large Language Models

0
💬
Sign in to get full access
Overview
- Large language models (LLMs) used in personal assistants must consider users' personal information and preferences
- However, LLMs lack the ability to learn from user interactions
- This paper explores capturing personal information from user prompts using ontology and knowledge-graph approaches
Plain English Explanation
The paper explores how large language models (LLMs) used in personal assistant applications can better understand and personalize to individual users. LLMs are powerful AI systems that can generate human-like text, but they currently lack the ability to learn from and adapt to each user's unique preferences and information.
The researchers propose using ontology and knowledge-graph approaches to capture personal details from user prompts and interactions. This would allow the LLM to build a model of the user's information and tailor its responses accordingly, similar to how CuriousLLM uses reasoning to answer questions.
The key idea is to use a pre-existing ontology that models personal information, called the KNOW ontology, to train the LLM on these concepts. Then the researchers evaluate how well the LLM is able to extract and retain personal details from a custom dataset they created.
Technical Explanation
The paper proposes a method to enable large language models (LLMs) to better understand and utilize users' personal information and preferences. The researchers use a subset of the KNOW ontology, which models personal information, to train the LLM on these concepts.
They then evaluate the success of this knowledge capture using a specially constructed dataset. The dataset contains prompts designed to elicit personal information, and the researchers assess how well the LLM is able to extract and retain these details.
The goal is to develop LLMs that can learn from user interactions and tailor their responses accordingly, improving the personalization and user experience of applications like personal assistants. The publicly available code and datasets from this research can be used to further explore this area.
Critical Analysis
The paper presents a novel approach to enabling large language models (LLMs) to better understand and utilize users' personal information. However, the researchers acknowledge several limitations and areas for further work.
One key limitation is the reliance on a pre-existing ontology, the KNOW ontology, to model personal information. While this provides a solid foundation, the ontology may not capture all the nuances and complexities of individual user data. Further research could explore building more comprehensive and flexible ontologies tailored to specific application domains.
Additionally, the evaluation dataset used in the study may not fully represent the diverse range of personal information and prompts that could arise in real-world applications. More extensive testing with a broader and more realistic dataset would be valuable to further validate the approach.
While the paper demonstrates the potential of this ontology-based method, there are also open questions around the privacy implications of LLMs accessing and modeling users' personal data. Addressing these privacy concerns will be crucial for the successful deployment of such personalization techniques.
Conclusion
This paper explores a promising approach to enabling large language models (LLMs) to better understand and utilize users' personal information and preferences. By leveraging ontology and knowledge-graph techniques, the researchers show how LLMs can be trained to extract and retain relevant personal details from user prompts.
This work has important implications for the development of more personalized and user-centric AI applications, such as personal assistants. By adapting to individual users' needs and preferences, these systems can provide a more tailored and engaging experience.
However, the research also highlights the need for further exploration of privacy-preserving techniques and more comprehensive ontologies to model the complexities of personal user data. As the field of AI continues to advance, addressing these challenges will be essential for creating trustworthy and ethical personalization technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Prompt-Time Ontology-Driven Symbolic Knowledge Capture with Large Language Models
Tolga c{C}oplu, Arto Bendiken, Andrii Skomorokhov, Eduard Bateiko, Stephen Cobb
In applications such as personal assistants, large language models (LLMs) must consider the user's personal information and preferences. However, LLMs lack the inherent ability to learn from user interactions. This paper explores capturing personal information from user prompts using ontology and knowledge-graph approaches. We use a subset of the KNOW ontology, which models personal information, to train the language model on these concepts. We then evaluate the success of knowledge capture using a specially constructed dataset. Our code and datasets are publicly available at https://github.com/HaltiaAI/paper-PTODSKC
Read more5/24/2024
0
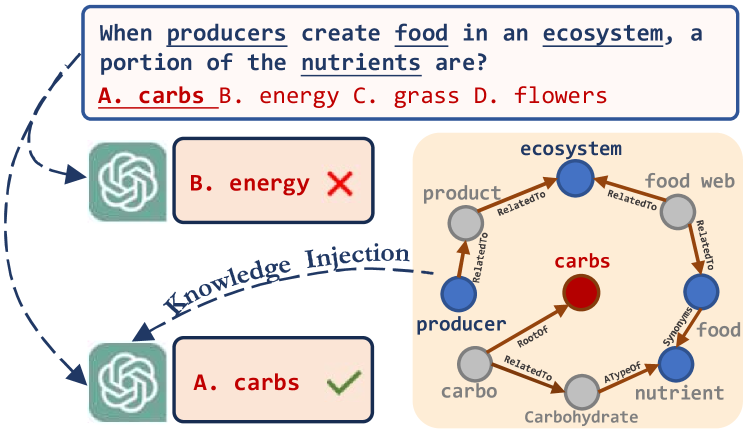
KnowGPT: Knowledge Graph based Prompting for Large Language Models
Qinggang Zhang, Junnan Dong, Hao Chen, Daochen Zha, Zailiang Yu, Xiao Huang
Large Language Models (LLMs) have demonstrated remarkable capabilities in many real-world applications. Nonetheless, LLMs are often criticized for their tendency to produce hallucinations, wherein the models fabricate incorrect statements on tasks beyond their knowledge and perception. To alleviate this issue, researchers have explored leveraging the factual knowledge in knowledge graphs (KGs) to ground the LLM's responses in established facts and principles. However, most state-of-the-art LLMs are closed-source, making it challenging to develop a prompting framework that can efficiently and effectively integrate KGs into LLMs with hard prompts only. Generally, existing KG-enhanced LLMs usually suffer from three critical issues, including huge search space, high API costs, and laborious prompt engineering, that impede their widespread application in practice. To this end, we introduce a novel Knowledge Graph based PrompTing framework, namely KnowGPT, to enhance LLMs with domain knowledge. KnowGPT contains a knowledge extraction module to extract the most informative knowledge from KGs, and a context-aware prompt construction module to automatically convert extracted knowledge into effective prompts. Experiments on three benchmarks demonstrate that KnowGPT significantly outperforms all competitors. Notably, KnowGPT achieves a 92.6% accuracy on OpenbookQA leaderboard, comparable to human-level performance.
Read more6/5/2024

0
KNOW: A Real-World Ontology for Knowledge Capture with Large Language Models
Arto Bendiken
We present KNOW--the Knowledge Navigator Ontology for the World--the first ontology designed to capture everyday knowledge to augment large language models (LLMs) in real-world generative AI use cases such as personal AI assistants. Our domain is human life, both its everyday concerns and its major milestones. We have limited the initial scope of the modeled concepts to only established human universals: spacetime (places, events) plus social (people, groups, organizations). The inclusion criteria for modeled concepts are pragmatic, beginning with universality and utility. We compare and contrast previous work such as Schema.org and Cyc--as well as attempts at a synthesis of knowledge graphs and language models--noting how LLMs already encode internally much of the commonsense tacit knowledge that took decades to capture in the Cyc project. We also make available code-generated software libraries for the 12 most popular programming languages, enabling the direct use of ontology concepts in software engineering. We emphasize simplicity and developer experience in promoting AI interoperability.
Read more5/31/2024
0
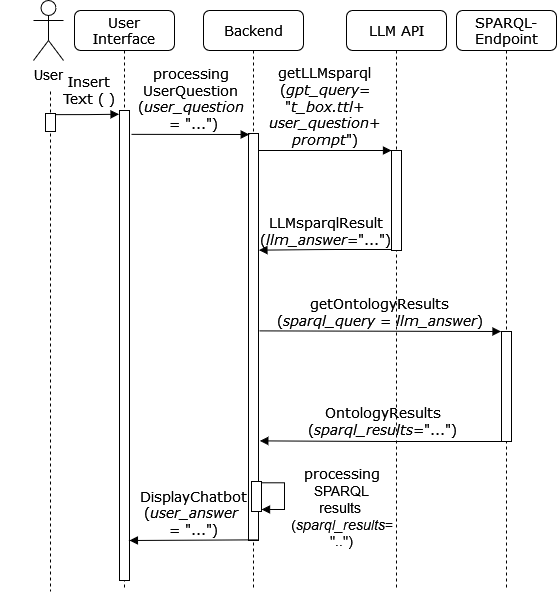
Chatbot-Based Ontology Interaction Using Large Language Models and Domain-Specific Standards
Jonathan Reif, Tom Jeleniewski, Milapji Singh Gill, Felix Gehlhoff, Alexander Fay
The following contribution introduces a concept that employs Large Language Models (LLMs) and a chatbot interface to enhance SPARQL query generation for ontologies, thereby facilitating intuitive access to formalized knowledge. Utilizing natural language inputs, the system converts user inquiries into accurate SPARQL queries that strictly query the factual content of the ontology, effectively preventing misinformation or fabrication by the LLM. To enhance the quality and precision of outcomes, additional textual information from established domain-specific standards is integrated into the ontology for precise descriptions of its concepts and relationships. An experimental study assesses the accuracy of generated SPARQL queries, revealing significant benefits of using LLMs for querying ontologies and highlighting areas for future research.
Read more8/6/2024