Prompting Large Language Models for Zero-shot Essay Scoring via Multi-trait Specialization
2404.04941
0
0
Abstract
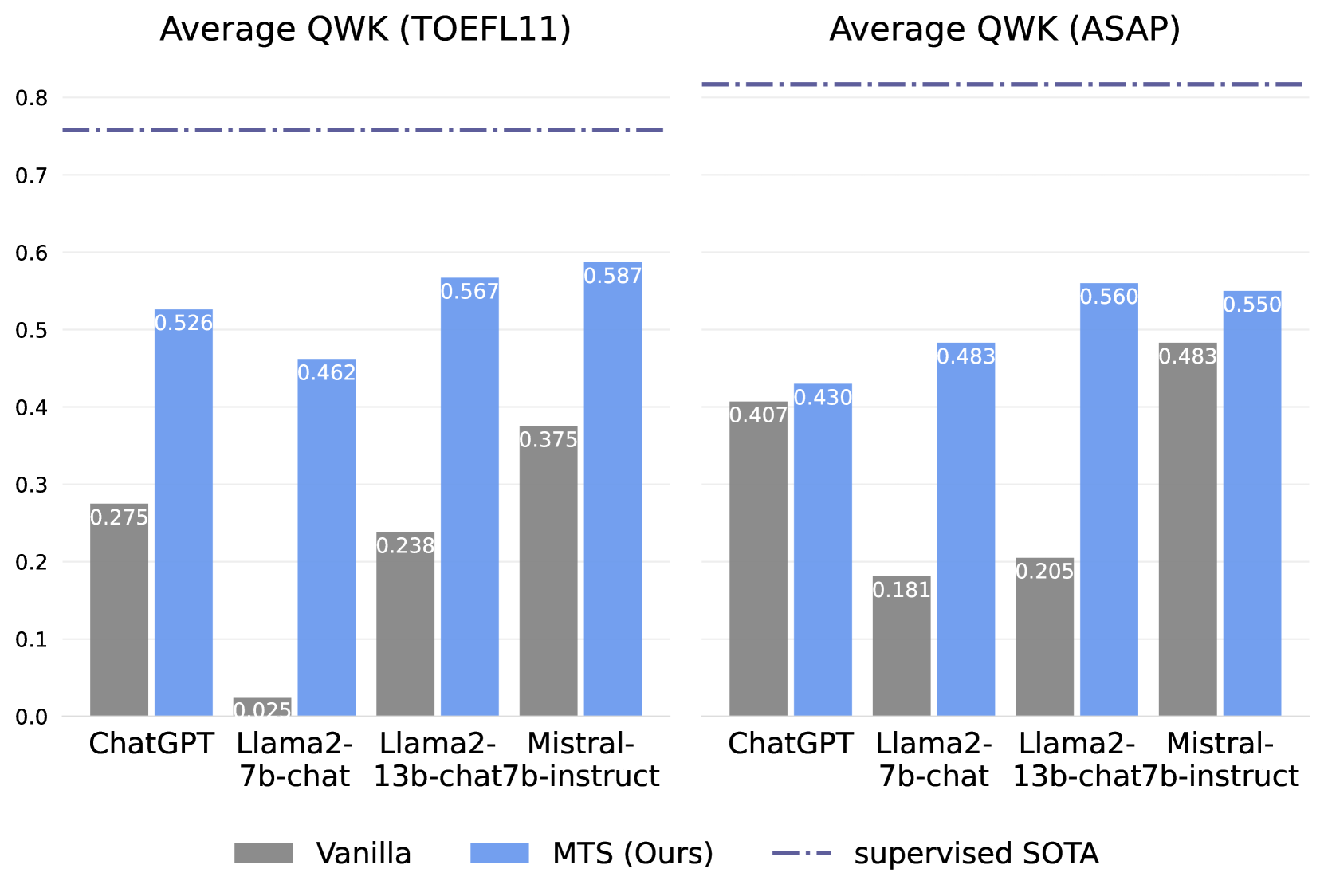
Advances in automated essay scoring (AES) have traditionally relied on labeled essays, requiring tremendous cost and expertise for their acquisition. Recently, large language models (LLMs) have achieved great success in various tasks, but their potential is less explored in AES. In this paper, we propose Multi Trait Specialization (MTS), a zero-shot prompting framework to elicit essay scoring capabilities in LLMs. Specifically, we leverage ChatGPT to decompose writing proficiency into distinct traits and generate scoring criteria for each trait. Then, an LLM is prompted to extract trait scores from several conversational rounds, each round scoring one of the traits based on the scoring criteria. Finally, we derive the overall score via trait averaging and min-max scaling. Experimental results on two benchmark datasets demonstrate that MTS consistently outperforms straightforward prompting (Vanilla) in average QWK across all LLMs and datasets, with maximum gains of 0.437 on TOEFL11 and 0.355 on ASAP. Additionally, with the help of MTS, the small-sized Llama2-13b-chat substantially outperforms ChatGPT, facilitating an effective deployment in real applications.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores a novel approach to zero-shot essay scoring using large language models (LLMs) with multi-trait specialization.
- The researchers developed a method to prompt LLMs to evaluate essays across multiple traits, such as content, organization, and style, without requiring any task-specific fine-tuning.
- The proposed technique aims to make essay scoring more accessible and scalable by leveraging the general capabilities of pre-trained LLMs.
Plain English Explanation
The paper describes a way to use powerful language AI models, called large language models (LLMs), to automatically score essays without having to extensively train the models on essay data first. Typically, to get an AI system to accurately evaluate essays, you would need to provide it with many examples of scored essays so it can learn what good essays look like. This paper's approach is different - it shows how you can prompt or instruct the LLM to assess essays across multiple key traits, like content, organization, and style, without that extensive training.
The key insight is that LLMs, like GPT-3, have such broad language understanding that you can guide them to perform new tasks, like essay scoring, just by giving them the right prompts or instructions. This makes the essay scoring process more accessible and scalable, since you don't need to build a specialized essay-scoring model from scratch. Instead, you can leverage the general capabilities of pre-trained LLMs.
Technical Explanation
The core of the paper's approach is a "multi-trait decomposition" technique. This involves designing prompts that ask the LLM to evaluate an essay along multiple dimensions, like:
- Content: How well-developed and substantive is the essay's content?
- Organization: How coherent and logically structured is the essay?
- Style: How effective is the essay's style, tone, and use of language?
By getting the LLM to provide scores or ratings for each of these traits, the researchers can then combine them into an overall essay score. This zero-shot approach, where the LLM performs the scoring task without any fine-tuning, is a key innovation.
The paper reports experiments using the GPT-3 LLM to score essays from the Automated Student Assessment Prize (ASAP) dataset. The results show the multi-trait prompting approach can achieve performance competitive with task-specific fine-tuned models, demonstrating the potential of this technique.
Critical Analysis
The paper makes a compelling case for the value of zero-shot essay scoring using pre-trained LLMs. By avoiding the need for extensive fine-tuning on essay data, this approach could make high-quality essay evaluation more accessible and scalable.
That said, the paper acknowledges some limitations. The multi-trait prompting technique may not work as well for more complex or open-ended essay types. Additionally, the researchers note that LLMs can sometimes exhibit biases or inconsistencies in their evaluations.
Further research could explore ways to make the prompting process more robust and generalizable. For example, investigating prompt engineering techniques or developing methods to fine-tune LLMs on small amounts of data could help expand the capabilities of zero-shot essay scoring.
Conclusion
This paper presents a novel approach to leveraging the power of large language models for the valuable task of essay scoring. By enabling zero-shot, multi-trait evaluation of essays, the researchers have demonstrated a way to make high-quality essay assessment more accessible and scalable.
While the technique has some limitations, the core insight - that pre-trained LLMs can be prompted to perform new tasks without extensive fine-tuning - is an important step forward. As language AI continues to advance, techniques like this could have significant implications for education, writing assessment, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Can Large Language Models Automatically Score Proficiency of Written Essays?
Watheq Mansour, Salam Albatarni, Sohaila Eltanbouly, Tamer Elsayed
0
0
Although several methods were proposed to address the problem of automated essay scoring (AES) in the last 50 years, there is still much to desire in terms of effectiveness. Large Language Models (LLMs) are transformer-based models that demonstrate extraordinary capabilities on various tasks. In this paper, we test the ability of LLMs, given their powerful linguistic knowledge, to analyze and effectively score written essays. We experimented with two popular LLMs, namely ChatGPT and Llama. We aim to check if these models can do this task and, if so, how their performance is positioned among the state-of-the-art (SOTA) models across two levels, holistically and per individual writing trait. We utilized prompt-engineering tactics in designing four different prompts to bring their maximum potential to this task. Our experiments conducted on the ASAP dataset revealed several interesting observations. First, choosing the right prompt depends highly on the model and nature of the task. Second, the two LLMs exhibited comparable average performance in AES, with a slight advantage for ChatGPT. Finally, despite the performance gap between the two LLMs and SOTA models in terms of predictions, they provide feedback to enhance the quality of the essays, which can potentially help both teachers and students.
4/17/2024

Improving Language Model-Based Zero-Shot Text-to-Speech Synthesis with Multi-Scale Acoustic Prompts
Shun Lei, Yixuan Zhou, Liyang Chen, Dan Luo, Zhiyong Wu, Xixin Wu, Shiyin Kang, Tao Jiang, Yahui Zhou, Yuxing Han, Helen Meng
0
0
Zero-shot text-to-speech (TTS) synthesis aims to clone any unseen speaker's voice without adaptation parameters. By quantizing speech waveform into discrete acoustic tokens and modeling these tokens with the language model, recent language model-based TTS models show zero-shot speaker adaptation capabilities with only a 3-second acoustic prompt of an unseen speaker. However, they are limited by the length of the acoustic prompt, which makes it difficult to clone personal speaking style. In this paper, we propose a novel zero-shot TTS model with the multi-scale acoustic prompts based on a neural codec language model VALL-E. A speaker-aware text encoder is proposed to learn the personal speaking style at the phoneme-level from the style prompt consisting of multiple sentences. Following that, a VALL-E based acoustic decoder is utilized to model the timbre from the timbre prompt at the frame-level and generate speech. The experimental results show that our proposed method outperforms baselines in terms of naturalness and speaker similarity, and can achieve better performance by scaling out to a longer style prompt.
4/10/2024
🤿
Can GPT-4 do L2 analytic assessment?
Stefano Bann`o, Hari Krishna Vydana, Kate M. Knill, Mark J. F. Gales
0
0
Automated essay scoring (AES) to evaluate second language (L2) proficiency has been a firmly established technology used in educational contexts for decades. Although holistic scoring has seen advancements in AES that match or even exceed human performance, analytic scoring still encounters issues as it inherits flaws and shortcomings from the human scoring process. The recent introduction of large language models presents new opportunities for automating the evaluation of specific aspects of L2 writing proficiency. In this paper, we perform a series of experiments using GPT-4 in a zero-shot fashion on a publicly available dataset annotated with holistic scores based on the Common European Framework of Reference and aim to extract detailed information about their underlying analytic components. We observe significant correlations between the automatically predicted analytic scores and multiple features associated with the individual proficiency components.
4/30/2024
Guiding Large Language Models to Post-Edit Machine Translation with Error Annotations
Dayeon Ki, Marine Carpuat
0
0
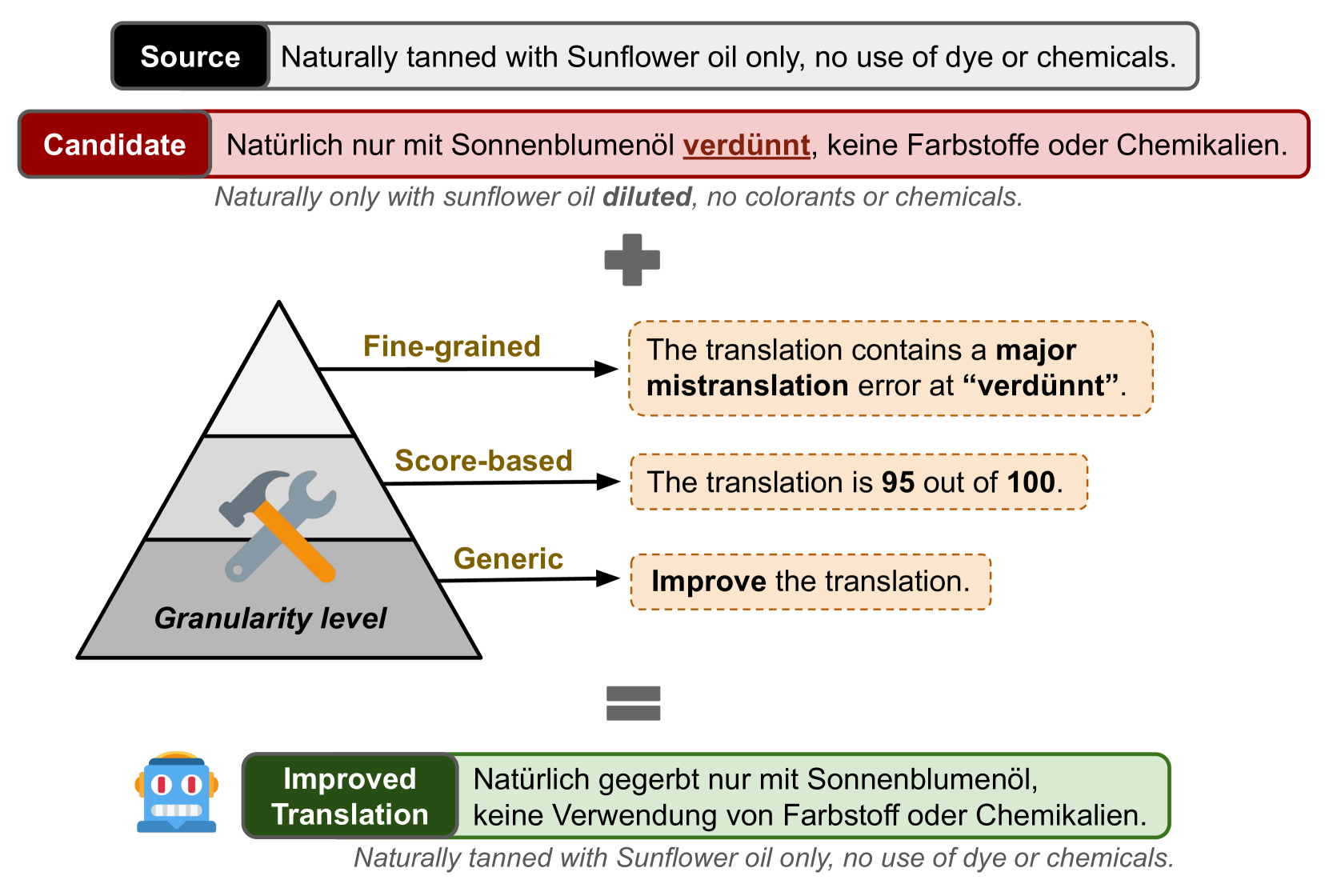
Machine Translation (MT) remains one of the last NLP tasks where large language models (LLMs) have not yet replaced dedicated supervised systems. This work exploits the complementary strengths of LLMs and supervised MT by guiding LLMs to automatically post-edit MT with external feedback on its quality, derived from Multidimensional Quality Metric (MQM) annotations. Working with LLaMA-2 models, we consider prompting strategies varying the nature of feedback provided and then fine-tune the LLM to improve its ability to exploit the provided guidance. Through experiments on Chinese-English, English-German, and English-Russian MQM data, we demonstrate that prompting LLMs to post-edit MT improves TER, BLEU and COMET scores, although the benefits of fine-grained feedback are not clear. Fine-tuning helps integrate fine-grained feedback more effectively and further improves translation quality based on both automatic and human evaluation.
4/12/2024