PromptRobust: Towards Evaluating the Robustness of Large Language Models on Adversarial Prompts

0
💬
Sign in to get full access
Overview
- This paper introduces PromptRobust, a robustness benchmark designed to measure the resilience of Large Language Models (LLMs) to adversarial prompts.
- The study uses a variety of adversarial textual attacks targeting prompts at different levels: character, word, sentence, and semantic.
- The adversarial prompts are designed to mimic plausible user errors like typos or synonyms and evaluate how slight deviations can affect LLM outcomes while maintaining semantic integrity.
- The prompts are tested on diverse tasks including sentiment analysis, natural language inference, reading comprehension, machine translation, and math problem-solving.
- The findings demonstrate that contemporary LLMs are not robust to adversarial prompts, and the paper presents a comprehensive analysis to understand the mystery behind prompt robustness and its transferability.
- The paper offers insightful robustness analysis and pragmatic recommendations for prompt composition, beneficial to both researchers and everyday users.
Plain English Explanation
Large Language Models (LLMs) are a type of artificial intelligence that can understand and generate human-like text. They are being used increasingly across many industries and fields, such as academia and industry.
However, the researchers behind this paper found that these LLMs are not very resilient to small changes in the prompts (the instructions or questions) given to them. Imagine you're asking a very smart assistant a question, but you accidentally misspell a word or use a slightly different synonym. The researchers found that these tiny changes can significantly affect the model's response, even if the overall meaning of the prompt is still clear.
To test this, the researchers created a benchmark called PromptRobust. They generated thousands of "adversarial prompts" - prompts that had been deliberately altered in small ways, like adding a typo or switching a word for a similar one. They then used these prompts to test the LLMs on a variety of tasks, like analyzing sentiment, answering questions, and solving math problems.
The results showed that the LLMs struggled with these adversarial prompts, even when the changes were minor and the overall meaning was still clear. This suggests that LLMs may not be as robust or reliable as we'd like, especially in real-world situations where users might not always type perfect prompts.
The researchers provide some insights into why LLMs have this weakness and offer recommendations for how to make them more resilient to small prompt variations. This is important for researchers, developers, and everyday users who rely on these powerful language models.
Technical Explanation
The PromptRobust benchmark introduced in this paper is designed to measure the resilience of Large Language Models (LLMs) to adversarial prompts. The researchers created a diverse set of 4,788 adversarial prompts that target prompts at different levels: character, word, sentence, and semantic.
These adversarial prompts are crafted to mimic plausible user errors, such as typos or using synonyms, in order to evaluate how slight deviations can affect LLM outcomes while maintaining semantic integrity. The prompts are then used to test LLM performance on a variety of tasks, including sentiment analysis, natural language inference, reading comprehension, machine translation, and math problem-solving.
The study finds that contemporary LLMs are not robust to these adversarial prompts, even when the changes are minor. The researchers present a comprehensive analysis to understand the underlying reasons for this lack of prompt robustness and its transferability across different tasks and models.
The paper also offers insightful robustness analysis and pragmatic recommendations for prompt composition. These insights can be beneficial for both researchers working to improve LLM robustness, as well as everyday users who rely on these models in their daily lives.
Critical Analysis
The PromptRobust study provides valuable insights into the limitations of current LLMs, particularly their vulnerability to small changes in prompts. The researchers have done a commendable job in designing a robust benchmark and thoroughly evaluating LLM performance across a diverse range of tasks and datasets.
One potential limitation of the study is that it focuses solely on textual adversarial attacks, while LLMs may also be susceptible to other types of perturbations, such as those involving code or numerical data. Additionally, the paper does not delve into the underlying reasons for the lack of prompt robustness in detail, and further research may be needed to fully understand the mechanisms behind this phenomenon.
The researchers' recommendations for prompt composition are a useful starting point, but it would be interesting to see if other techniques, such as adversarial training or prompt engineering, could be employed to improve LLM robustness to adversarial prompts. Overall, this paper makes a valuable contribution to the ongoing discussion around the robustness and reliability of Large Language Models.
Conclusion
The PromptRobust study highlights a critical issue with the current state of Large Language Models (LLMs) - their lack of resilience to seemingly minor changes in the prompts they receive. The researchers have developed a comprehensive benchmark to measure this prompt robustness, and their findings demonstrate that contemporary LLMs struggle to maintain performance when faced with adversarial prompts.
This research has important implications for both researchers and everyday users of LLMs. It underscores the need for further work to improve the robustness and reliability of these powerful language models, which are being increasingly relied upon across a wide range of applications. The insights and recommendations provided in this paper offer a valuable starting point for addressing this challenge and paving the way for more robust and trustworthy LLMs in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
PromptRobust: Towards Evaluating the Robustness of Large Language Models on Adversarial Prompts
Kaijie Zhu, Jindong Wang, Jiaheng Zhou, Zichen Wang, Hao Chen, Yidong Wang, Linyi Yang, Wei Ye, Yue Zhang, Neil Zhenqiang Gong, Xing Xie
The increasing reliance on Large Language Models (LLMs) across academia and industry necessitates a comprehensive understanding of their robustness to prompts. In response to this vital need, we introduce PromptRobust, a robustness benchmark designed to measure LLMs' resilience to adversarial prompts. This study uses a plethora of adversarial textual attacks targeting prompts across multiple levels: character, word, sentence, and semantic. The adversarial prompts, crafted to mimic plausible user errors like typos or synonyms, aim to evaluate how slight deviations can affect LLM outcomes while maintaining semantic integrity. These prompts are then employed in diverse tasks including sentiment analysis, natural language inference, reading comprehension, machine translation, and math problem-solving. Our study generates 4,788 adversarial prompts, meticulously evaluated over 8 tasks and 13 datasets. Our findings demonstrate that contemporary LLMs are not robust to adversarial prompts. Furthermore, we present a comprehensive analysis to understand the mystery behind prompt robustness and its transferability. We then offer insightful robustness analysis and pragmatic recommendations for prompt composition, beneficial to both researchers and everyday users.
Read more7/17/2024
🤔
0
AdvPrompter: Fast Adaptive Adversarial Prompting for LLMs
Anselm Paulus, Arman Zharmagambetov, Chuan Guo, Brandon Amos, Yuandong Tian
While recently Large Language Models (LLMs) have achieved remarkable successes, they are vulnerable to certain jailbreaking attacks that lead to generation of inappropriate or harmful content. Manual red-teaming requires finding adversarial prompts that cause such jailbreaking, e.g. by appending a suffix to a given instruction, which is inefficient and time-consuming. On the other hand, automatic adversarial prompt generation often leads to semantically meaningless attacks that can easily be detected by perplexity-based filters, may require gradient information from the TargetLLM, or do not scale well due to time-consuming discrete optimization processes over the token space. In this paper, we present a novel method that uses another LLM, called the AdvPrompter, to generate human-readable adversarial prompts in seconds, $sim800times$ faster than existing optimization-based approaches. We train the AdvPrompter using a novel algorithm that does not require access to the gradients of the TargetLLM. This process alternates between two steps: (1) generating high-quality target adversarial suffixes by optimizing the AdvPrompter predictions, and (2) low-rank fine-tuning of the AdvPrompter with the generated adversarial suffixes. The trained AdvPrompter generates suffixes that veil the input instruction without changing its meaning, such that the TargetLLM is lured to give a harmful response. Experimental results on popular open source TargetLLMs show state-of-the-art results on the AdvBench dataset, that also transfer to closed-source black-box LLM APIs. Further, we demonstrate that by fine-tuning on a synthetic dataset generated by AdvPrompter, LLMs can be made more robust against jailbreaking attacks while maintaining performance, i.e. high MMLU scores.
Read more4/29/2024

0
NLPerturbator: Studying the Robustness of Code LLMs to Natural Language Variations
Junkai Chen, Zhenhao Li, Xing Hu, Xin Xia
Large language models (LLMs) achieve promising results in code generation based on a given natural language description. They have been integrated into open-source projects and commercial products to facilitate daily coding activities. The natural language description in the prompt is crucial for LLMs to comprehend users' requirements. Prior studies uncover that LLMs are sensitive to the changes in the prompts, including slight changes that look inconspicuous. However, the natural language descriptions often vary in real-world scenarios (e.g., different formats, grammar, and wording). Prior studies on the robustness of LLMs are often based on random perturbations and such perturbations may not actually happen. In this paper, we conduct a comprehensive study to investigate how are code LLMs robust to variations of natural language description in real-world scenarios. We summarize 18 categories of perturbations of natural language and 3 combinations of co-occurred categories based on our literature review and an online survey with practitioners. We propose an automated framework, NLPerturbator, which can perform perturbations of each category given a set of prompts. Through a series of experiments on code generation using six code LLMs, we find that the perturbed prompts can decrease the performance of code generation by a considerable margin (e.g., up to 21.2%, and 4.8% to 6.1% on average). Our study highlights the importance of enhancing the robustness of LLMs to real-world variations in the prompts, as well as the essentiality of attentively constructing the prompts.
Read more7/1/2024
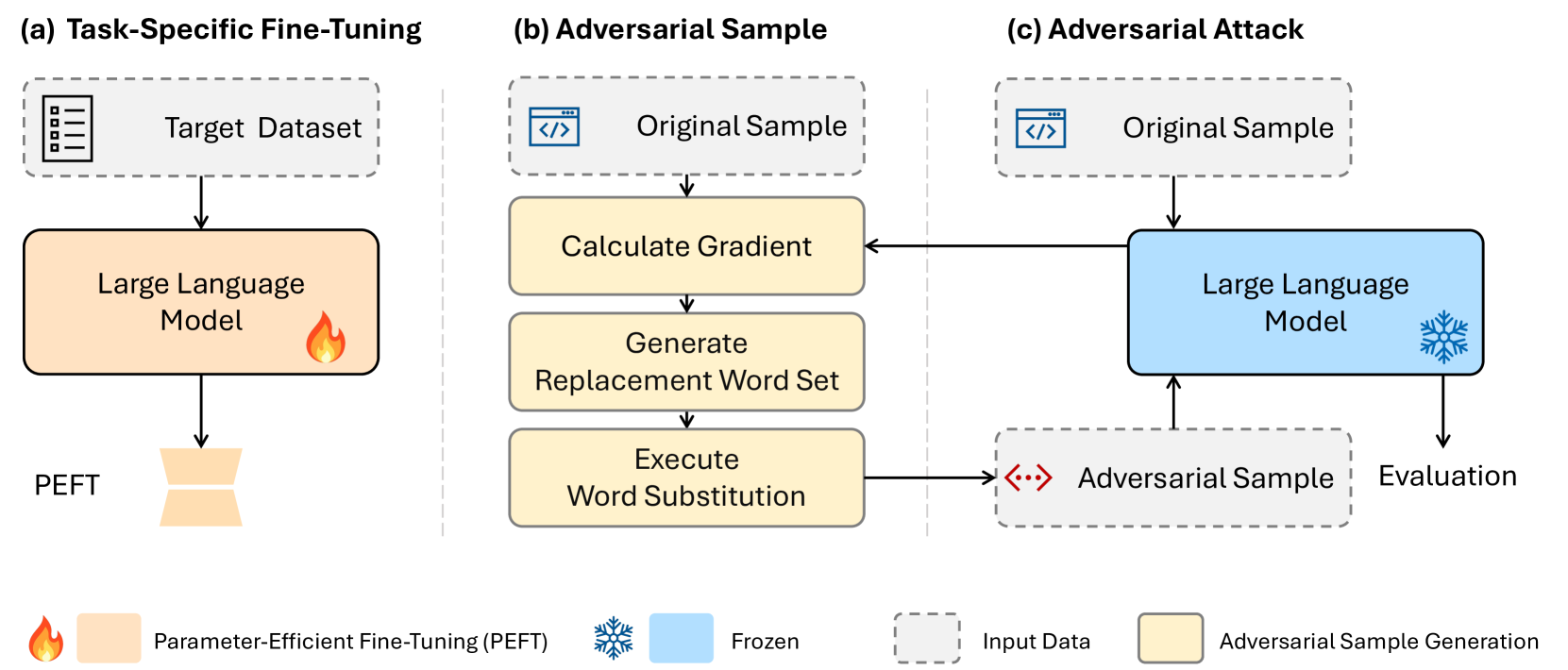
0
Assessing Adversarial Robustness of Large Language Models: An Empirical Study
Zeyu Yang, Zhao Meng, Xiaochen Zheng, Roger Wattenhofer
Large Language Models (LLMs) have revolutionized natural language processing, but their robustness against adversarial attacks remains a critical concern. We presents a novel white-box style attack approach that exposes vulnerabilities in leading open-source LLMs, including Llama, OPT, and T5. We assess the impact of model size, structure, and fine-tuning strategies on their resistance to adversarial perturbations. Our comprehensive evaluation across five diverse text classification tasks establishes a new benchmark for LLM robustness. The findings of this study have far-reaching implications for the reliable deployment of LLMs in real-world applications and contribute to the advancement of trustworthy AI systems.
Read more9/16/2024