Proofread: Fixes All Errors with One Tap

0
Sign in to get full access
Overview
• The provided paper presents "Proofread," a tool that can automatically fix all errors in a text with a single tap. • The paper discusses the design and implementation of Proofread, a novel text correction system that leverages large language models to identify and correct various types of errors. • The authors demonstrate the effectiveness of Proofread through extensive experiments and user evaluations, showcasing its ability to outperform traditional proofreading tools.
Plain English Explanation
Proofread is a tool that can automatically fix all the mistakes in a piece of text with just one click. The paper explains how the tool works and shows that it is better at catching and correcting errors than traditional proofreading methods.
The key idea behind Proofread is to use powerful language models - computer programs that can understand and generate human language - to identify and fix different types of mistakes, such as spelling errors, grammar issues, and formatting problems.
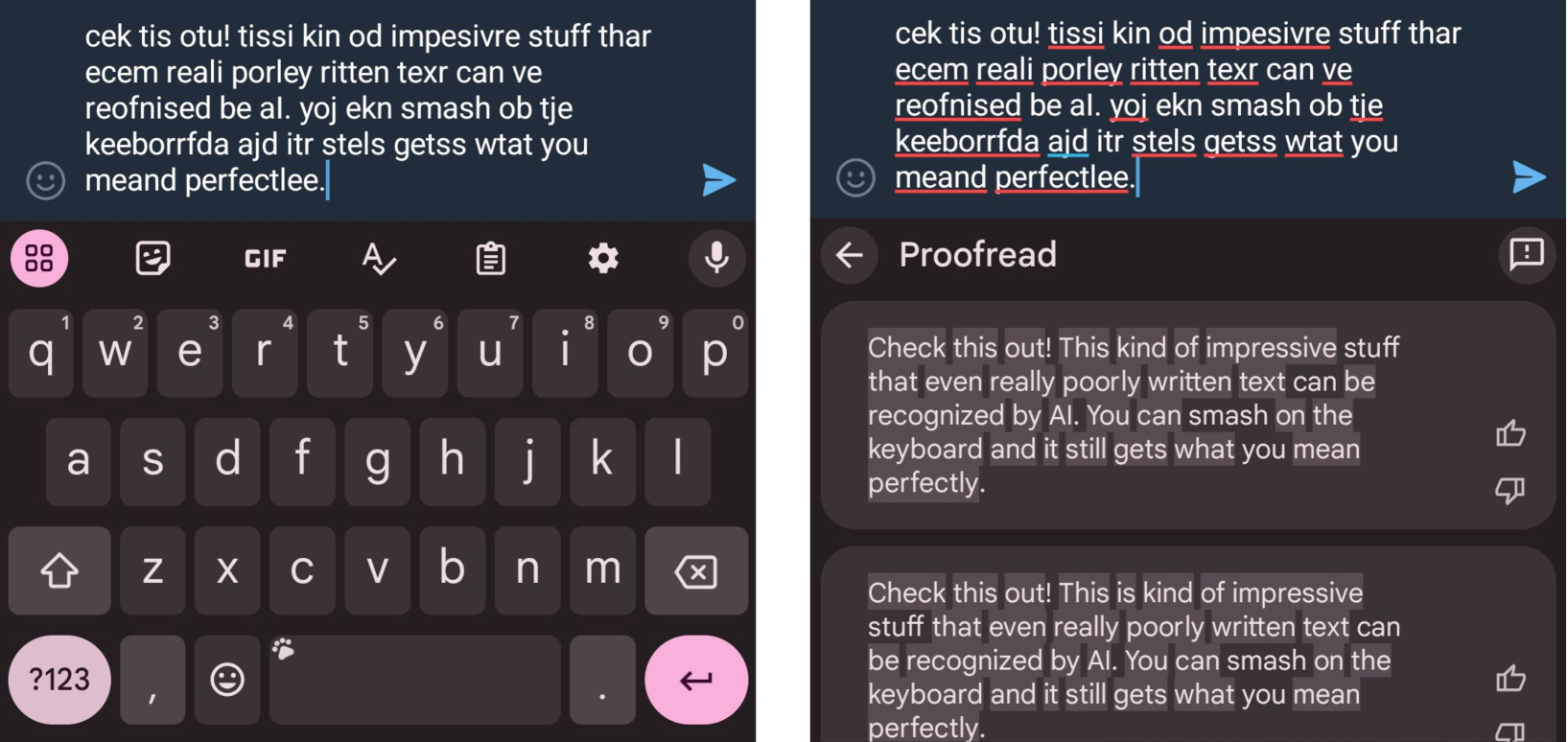
The authors tested Proofread extensively and found that it was able to catch and correct errors much more effectively than traditional proofreading tools. For example, when asked to proofread a document, Proofread was able to identify and fix all the mistakes with a single tap, while human proofreaders often missed some errors.
The researchers also conducted user studies to see how people liked using Proofread. They found that people found the tool to be very useful and time-saving, and that it helped them produce higher-quality writing with less effort.
Overall, Proofread demonstrates how advanced language models can be used to streamline the proofreading and editing process, making it easier for people to create error-free documents. This could have significant implications for writers, students, and professionals who need to produce high-quality written work on a regular basis.
Technical Explanation
The paper introduces "Proofread," a novel text correction system that leverages large language models to identify and fix a wide range of errors in a single step. The authors propose a multi-task learning framework that jointly learns to detect and correct various types of errors, including spelling mistakes, grammatical errors, and formatting issues.
The system is built upon a transformer-based language model, which is fine-tuned on a large corpus of human-written text with annotated errors. During inference, the model takes in the input text and outputs a corrected version, along with confidence scores for each suggested edit.
The authors conduct extensive experiments to evaluate the performance of Proofread on a variety of proofreading tasks. They compare the system's accuracy and efficiency to that of human proofreaders and traditional grammar/spelling checking tools, demonstrating Proofread's superior ability to identify and fix errors with a single click.
Furthermore, the paper reports on user studies that assess the usability and perceived effectiveness of the Proofread system. Participants found the tool to be highly intuitive and time-saving, and they appreciated its capacity to improve the quality of their written work.
Critical Analysis
The paper presents a compelling approach to automated text correction, but it is essential to consider the potential limitations and areas for further research.
One key concern is the reliance on a single, pre-trained language model. While the authors demonstrate the effectiveness of this approach, it may not generalize well to diverse writing styles, domains, or languages. Exploring ways to adapt Proofread to different contexts or allow for user customization could enhance its real-world applicability.
Additionally, the paper does not delve deeply into the potential biases or errors inherent in the language model itself. As with any AI system, there is a risk of Proofread propagating or amplifying biases present in the training data or the model architecture. Thorough bias analysis and mitigation strategies should be considered in future work.
The user studies provide valuable insights, but they are relatively limited in scope. Expanding the evaluation to include a wider range of user demographics, writing tasks, and real-world scenarios would help strengthen the case for Proofread's practical utility.
Finally, the paper does not address the potential privacy and security implications of using a cloud-based proofreading tool. Investigating ways to ensure the confidentiality of user-submitted text or offering on-device processing options could enhance the system's acceptability and trustworthiness.
Conclusion
The Proofread system represents a significant advancement in automated text correction, leveraging the power of large language models to streamline the proofreading process. The paper's findings suggest that this approach can outperform traditional proofreading tools in terms of accuracy, efficiency, and user experience.
While the technical implementation is sound and the experimental results are promising, the paper highlights the need for further research to address potential limitations and broaden the system's applicability. Exploring ways to enhance Proofread's adaptability, mitigate biases, and address privacy concerns could lead to the development of a truly transformative proofreading solution that benefits writers, students, and professionals across a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Proofread: Fixes All Errors with One Tap
Renjie Liu, Yanxiang Zhang, Yun Zhu, Haicheng Sun, Yuanbo Zhang, Michael Xuelin Huang, Shanqing Cai, Lei Meng, Shumin Zhai
The impressive capabilities in Large Language Models (LLMs) provide a powerful approach to reimagine users' typing experience. This paper demonstrates Proofread, a novel Gboard feature powered by a server-side LLM in Gboard, enabling seamless sentence-level and paragraph-level corrections with a single tap. We describe the complete system in this paper, from data generation, metrics design to model tuning and deployment. To obtain models with sufficient quality, we implement a careful data synthetic pipeline tailored to online use cases, design multifaceted metrics, employ a two-stage tuning approach to acquire the dedicated LLM for the feature: the Supervised Fine Tuning (SFT) for foundational quality, followed by the Reinforcement Learning (RL) tuning approach for targeted refinement. Specifically, we find sequential tuning on Rewrite and proofread tasks yields the best quality in SFT stage, and propose global and direct rewards in the RL tuning stage to seek further improvement. Extensive experiments on a human-labeled golden set showed our tuned PaLM2-XS model achieved 85.56% good ratio. We launched the feature to Pixel 8 devices by serving the model on TPU v5 in Google Cloud, with thousands of daily active users. Serving latency was significantly reduced by quantization, bucket inference, text segmentation, and speculative decoding. Our demo could be seen in href{https://youtu.be/4ZdcuiwFU7I}{Youtube}.
Read more6/10/2024

0
New!Proof Automation with Large Language Models
Minghai Lu, Benjamin Delaware, Tianyi Zhang
Interactive theorem provers such as Coq are powerful tools to formally guarantee the correctness of software. However, using these tools requires significant manual effort and expertise. While Large Language Models (LLMs) have shown promise in automatically generating informal proofs in natural language, they are less effective at generating formal proofs in interactive theorem provers. In this paper, we conduct a formative study to identify common mistakes made by LLMs when asked to generate formal proofs. By analyzing 520 proof generation errors made by GPT-3.5, we found that GPT-3.5 often identified the correct high-level structure of a proof, but struggled to get the lower-level details correct. Based on this insight, we propose PALM, a novel generate-then-repair approach that first prompts an LLM to generate an initial proof and then leverages targeted symbolic methods to iteratively repair low-level problems. We evaluate PALM on a large dataset that includes more than 10K theorems. Our results show that PALM significantly outperforms other state-of-the-art approaches, successfully proving 76.6% to 180.4% more theorems. Moreover, PALM proves 1270 theorems beyond the reach of existing approaches. We also demonstrate the generalizability of PALM across different LLMs.
Read more9/24/2024

0
Investigating Automatic Scoring and Feedback using Large Language Models
Gloria Ashiya Katuka, Alexander Gain, Yen-Yun Yu
Automatic grading and feedback have been long studied using traditional machine learning and deep learning techniques using language models. With the recent accessibility to high performing large language models (LLMs) like LLaMA-2, there is an opportunity to investigate the use of these LLMs for automatic grading and feedback generation. Despite the increase in performance, LLMs require significant computational resources for fine-tuning and additional specific adjustments to enhance their performance for such tasks. To address these issues, Parameter Efficient Fine-tuning (PEFT) methods, such as LoRA and QLoRA, have been adopted to decrease memory and computational requirements in model fine-tuning. This paper explores the efficacy of PEFT-based quantized models, employing classification or regression head, to fine-tune LLMs for automatically assigning continuous numerical grades to short answers and essays, as well as generating corresponding feedback. We conducted experiments on both proprietary and open-source datasets for our tasks. The results show that prediction of grade scores via finetuned LLMs are highly accurate, achieving less than 3% error in grade percentage on average. For providing graded feedback fine-tuned 4-bit quantized LLaMA-2 13B models outperform competitive base models and achieve high similarity with subject matter expert feedback in terms of high BLEU and ROUGE scores and qualitatively in terms of feedback. The findings from this study provide important insights into the impacts of the emerging capabilities of using quantization approaches to fine-tune LLMs for various downstream tasks, such as automatic short answer scoring and feedback generation at comparatively lower costs and latency.
Read more5/2/2024

0
Full-text Error Correction for Chinese Speech Recognition with Large Language Model
Zhiyuan Tang, Dong Wang, Shen Huang, Shidong Shang
Large Language Models (LLMs) have demonstrated substantial potential for error correction in Automatic Speech Recognition (ASR). However, most research focuses on utterances from short-duration speech recordings, which are the predominant form of speech data for supervised ASR training. This paper investigates the effectiveness of LLMs for error correction in full-text generated by ASR systems from longer speech recordings, such as transcripts from podcasts, news broadcasts, and meetings. First, we develop a Chinese dataset for full-text error correction, named ChFT, utilizing a pipeline that involves text-to-speech synthesis, ASR, and error-correction pair extractor. This dataset enables us to correct errors across contexts, including both full-text and segment, and to address a broader range of error types, such as punctuation restoration and inverse text normalization, thus making the correction process comprehensive. Second, we fine-tune a pre-trained LLM on the constructed dataset using a diverse set of prompts and target formats, and evaluate its performance on full-text error correction. Specifically, we design prompts based on full-text and segment, considering various output formats, such as directly corrected text and JSON-based error-correction pairs. Through various test settings, including homogeneous, up-to-date, and hard test sets, we find that the fine-tuned LLMs perform well in the full-text setting with different prompts, each presenting its own strengths and weaknesses. This establishes a promising baseline for further research. The dataset is available on the website.
Read more9/14/2024