Proximal Causal Inference With Text Data

0
Sign in to get full access
Overview
- This paper explores the use of text data to infer causal relationships, a task known as proximal causal inference.
- The authors propose techniques for designing text-based proxy variables that can be used to study causal effects even when direct measurements are unavailable.
- They also introduce a falsification test based on odds ratios to help validate the proposed text-based proxies.
Plain English Explanation
The paper is about using text data, such as written documents or online posts, to study cause and effect relationships. This can be useful when we can't directly measure the factors we're interested in. For example, if we want to understand how a person's job affects their health, we might not be able to directly measure their job stress or working conditions. But we could look at the words they use in emails or social media posts to get a sense of their work environment.
The researchers describe ways to create "proxy" variables from text data that can serve as stand-ins for the unmeasurable factors we're curious about. They also provide a technique to test whether these text-based proxies are valid and actually relate to the underlying causal relationships. This allows researchers to use readily available text data to shed light on important questions, even when direct measurements are difficult or impossible to obtain.
Technical Explanation
The paper introduces the problem of proximal causal inference with text data, where the goal is to infer causal relationships from observational data when direct measurements of key variables are unavailable. The authors propose methods for designing text-based proxy variables that can serve as stand-ins for these unmeasurable factors.
A key challenge is validating that the text-based proxies are in fact related to the underlying causal relationships of interest. To address this, the paper introduces an odds ratio heuristic as a falsification test to check the plausibility of the proposed proxies.
The techniques described in the paper allow researchers to leverage abundant text data to study causal questions that would otherwise be difficult or impossible to address due to missing data.
Critical Analysis
The paper provides a rigorous framework for using text data to infer causal relationships, addressing an important challenge in causal inference. The proposed proxy design and validation approach seems well-grounded and the authors demonstrate the techniques on several real-world case studies.
However, the paper does not extensively discuss potential limitations or caveats. For example, the text-based proxies may capture only certain aspects of the underlying causal factors, and their validity could depend heavily on the specific context and domain. More research is likely needed to understand the broader applicability and robustness of these methods.
Additionally, the techniques rely on strong assumptions, such as the availability of relevant text data and the ability to accurately measure textual features. In practice, data quality and preprocessing challenges could impact the effectiveness of the proposed approaches.
Conclusion
This paper presents an innovative approach to causal inference that leverages text data to overcome the challenge of missing direct measurements. By designing text-based proxy variables and validating their reliability, the researchers demonstrate how readily available text can be used to shed light on important causal questions.
While the techniques require further exploration and validation, the core ideas have the potential to significantly expand the scope of causal inference research, allowing scholars to gain insights from a wider range of observational data sources. As text data becomes increasingly abundant, methods like those described in this paper may become an essential tool in the causal inference toolkit.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Proximal Causal Inference With Text Data
Jacob M. Chen, Rohit Bhattacharya, Katherine A. Keith
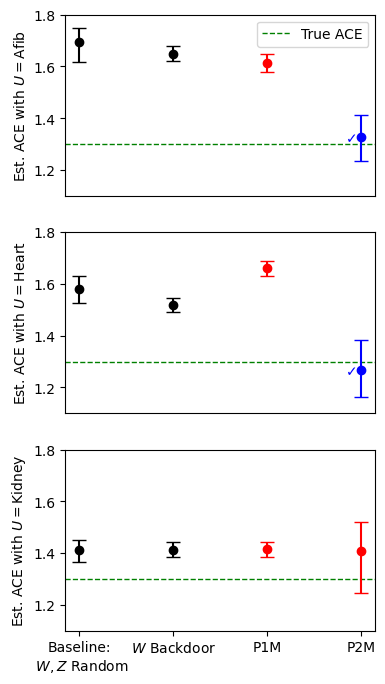
Recent text-based causal methods attempt to mitigate confounding bias by estimating proxies of confounding variables that are partially or imperfectly measured from unstructured text data. These approaches, however, assume analysts have supervised labels of the confounders given text for a subset of instances, a constraint that is sometimes infeasible due to data privacy or annotation costs. In this work, we address settings in which an important confounding variable is completely unobserved. We propose a new causal inference method that uses multiple instances of pre-treatment text data, infers two proxies from two zero-shot models on the separate instances, and applies these proxies in the proximal g-formula. We prove that our text-based proxy method satisfies identification conditions required by the proximal g-formula while other seemingly reasonable proposals do not. We evaluate our method in synthetic and semi-synthetic settings and find that it produces estimates with low bias. To address untestable assumptions associated with the proximal g-formula, we further propose an odds ratio falsification heuristic. This new combination of proximal causal inference and zero-shot classifiers expands the set of text-specific causal methods available to practitioners.
Read more5/24/2024
🧪
0
Causal Discovery via Conditional Independence Testing with Proxy Variables
Mingzhou Liu, Xinwei Sun, Yu Qiao, Yizhou Wang
Distinguishing causal connections from correlations is important in many scenarios. However, the presence of unobserved variables, such as the latent confounder, can introduce bias in conditional independence testing commonly employed in constraint-based causal discovery for identifying causal relations. To address this issue, existing methods introduced proxy variables to adjust for the bias caused by unobserveness. However, these methods were either limited to categorical variables or relied on strong parametric assumptions for identification. In this paper, we propose a novel hypothesis-testing procedure that can effectively examine the existence of the causal relationship over continuous variables, without any parametric constraint. Our procedure is based on discretization, which under completeness conditions, is able to asymptotically establish a linear equation whose coefficient vector is identifiable under the causal null hypothesis. Based on this, we introduce our test statistic and demonstrate its asymptotic level and power. We validate the effectiveness of our procedure using both synthetic and real-world data.
Read more5/3/2024

0
From Text to Treatment Effects: A Meta-Learning Approach to Handling Text-Based Confounding
Henri Arno, Paloma Rabaey, Thomas Demeester
One of the central goals of causal machine learning is the accurate estimation of heterogeneous treatment effects from observational data. In recent years, meta-learning has emerged as a flexible, model-agnostic paradigm for estimating conditional average treatment effects (CATE) using any supervised model. This paper examines the performance of meta-learners when the confounding variables are embedded in text. Through synthetic data experiments, we show that learners using pre-trained text representations of confounders, in addition to tabular background variables, achieve improved CATE estimates compare to those relying solely on the tabular variables, particularly when sufficient data is available. However, due to the entangled nature of the text embeddings, these models do not fully match the performance of meta-learners with perfect confounder knowledge. These findings highlight both the potential and the limitations of pre-trained text representations for causal inference and open up interesting avenues for future research.
Read more9/25/2024
0
End-To-End Causal Effect Estimation from Unstructured Natural Language Data
Nikita Dhawan, Leonardo Cotta, Karen Ullrich, Rahul G. Krishnan, Chris J. Maddison
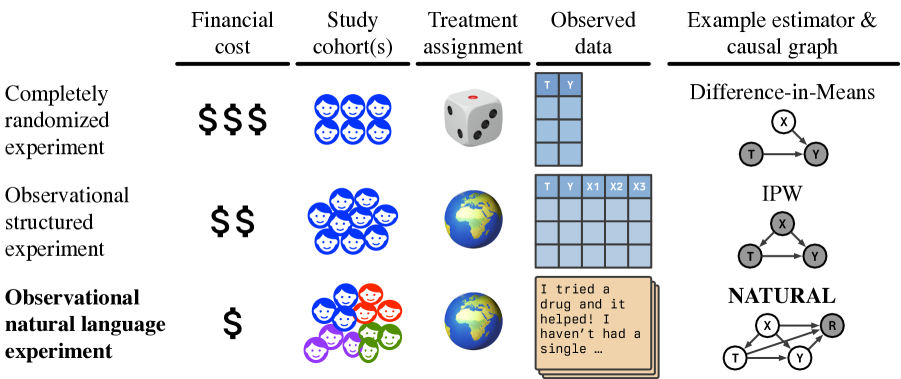
Knowing the effect of an intervention is critical for human decision-making, but current approaches for causal effect estimation rely on manual data collection and structuring, regardless of the causal assumptions. This increases both the cost and time-to-completion for studies. We show how large, diverse observational text data can be mined with large language models (LLMs) to produce inexpensive causal effect estimates under appropriate causal assumptions. We introduce NATURAL, a novel family of causal effect estimators built with LLMs that operate over datasets of unstructured text. Our estimators use LLM conditional distributions (over variables of interest, given the text data) to assist in the computation of classical estimators of causal effect. We overcome a number of technical challenges to realize this idea, such as automating data curation and using LLMs to impute missing information. We prepare six (two synthetic and four real) observational datasets, paired with corresponding ground truth in the form of randomized trials, which we used to systematically evaluate each step of our pipeline. NATURAL estimators demonstrate remarkable performance, yielding causal effect estimates that fall within 3 percentage points of their ground truth counterparts, including on real-world Phase 3/4 clinical trials. Our results suggest that unstructured text data is a rich source of causal effect information, and NATURAL is a first step towards an automated pipeline to tap this resource.
Read more8/26/2024