Pushing the Limits of Zero-shot End-to-End Speech Translation
2402.10422
0
0

Abstract
Data scarcity and the modality gap between the speech and text modalities are two major obstacles of end-to-end Speech Translation (ST) systems, thus hindering their performance. Prior work has attempted to mitigate these challenges by leveraging external MT data and optimizing distance metrics that bring closer the speech-text representations. However, achieving competitive results typically requires some ST data. For this reason, we introduce ZeroSwot, a method for zero-shot ST that bridges the modality gap without any paired ST data. Leveraging a novel CTC compression and Optimal Transport, we train a speech encoder using only ASR data, to align with the representation space of a massively multilingual MT model. The speech encoder seamlessly integrates with the MT model at inference, enabling direct translation from speech to text, across all languages supported by the MT model. Our experiments show that we can effectively close the modality gap without ST data, while our results on MuST-C and CoVoST demonstrate our method's superiority over not only previous zero-shot models, but also supervised ones, achieving state-of-the-art results.
Create account to get full access
Overview
- This paper explores the capabilities and limitations of zero-shot end-to-end speech translation (ZEST), where a speech translation model is trained on data from two languages but can translate between any pair of those languages without additional fine-tuning.
- The researchers investigate several key ingredients that enable effective ZEST, including the use of multilingual pre-training, cross-lingual prompting, and model architectural choices.
- The paper presents techniques to improve ZEST performance and provide a comprehensive analysis of the factors that influence ZEST performance.
Plain English Explanation
The paper looks at a type of language translation system called "zero-shot end-to-end speech translation" (ZEST). In a ZEST system, the model is trained on speech data from two or more languages, but then can translate between any pair of those languages without needing additional training.
The researchers explore what makes ZEST systems work well. They find that using multilingual pre-training - where the model is first trained on a large amount of multilingual data - is crucial. They also show that cross-lingual prompting - providing the model with helpful information about the languages involved - can significantly boost performance.
Additionally, the choice of model architecture matters a lot. The researchers experiment with different model designs to find the best configuration for ZEST. Overall, the paper provides a detailed look at the technical ingredients needed to build effective zero-shot speech translation systems.
Technical Explanation
The paper investigates the capabilities and limitations of zero-shot end-to-end speech translation (ZEST), which enables translating between language pairs without additional fine-tuning. The researchers explore several key ingredients that enable effective ZEST:
-
Multilingual Pre-training: The paper shows that initializing the ZEST model with weights from a multilingual pre-trained model, such as mT5, is crucial for achieving good zero-shot performance.
-
Cross-lingual Prompting: The researchers experiment with various prompting techniques, including cross-lingual prompting, to provide the model with helpful information about the source and target languages.
-
Model Architecture: The paper explores the impact of different model architectures, including encoder-decoder and cascaded designs, on ZEST performance.
-
Multilingual Fine-tuning: The researchers investigate the benefits of fine-tuning the pre-trained ZEST model on a small amount of multilingual data to further improve its zero-shot capabilities.
The paper presents comprehensive experiments and analyses to understand the factors that influence ZEST performance, providing insights into the technical requirements for building effective zero-shot speech translation systems.
Critical Analysis
The paper provides a thorough investigation of ZEST and offers several valuable insights. However, the researchers acknowledge some limitations of their work:
-
Data Scarcity: The paper focuses on a relatively small set of languages, as most publicly available speech translation datasets are limited in their language coverage. Expanding the research to a wider range of languages could reveal additional challenges.
-
Computational Costs: The multilingual pre-training and fine-tuning approaches used in the paper can be computationally expensive, which may limit the practical deployment of ZEST systems, especially in resource-constrained environments.
-
Real-world Performance: The paper primarily evaluates ZEST performance on standard benchmarks, but its performance in real-world, noisy, and unpredictable environments remains to be studied.
Future research could explore techniques to reduce the computational costs of ZEST, investigate its robustness in diverse real-world scenarios, and expand the language coverage to better understand the capabilities and limitations of this technology.
Conclusion
This paper presents a comprehensive study of zero-shot end-to-end speech translation (ZEST), a promising approach that can translate between language pairs without the need for additional fine-tuning. The researchers identify several key ingredients, such as multilingual pre-training, cross-lingual prompting, and model architectural choices, that are essential for building effective ZEST systems.
The insights and techniques described in this paper could pave the way for more accessible and versatile speech translation technologies, with the potential to break down language barriers and facilitate cross-cultural communication. As the field of ZEST continues to evolve, further research will be needed to address the remaining challenges and unlock the full potential of this technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Can We Achieve High-quality Direct Speech-to-Speech Translation without Parallel Speech Data?
Qingkai Fang, Shaolei Zhang, Zhengrui Ma, Min Zhang, Yang Feng
0
0
Recently proposed two-pass direct speech-to-speech translation (S2ST) models decompose the task into speech-to-text translation (S2TT) and text-to-speech (TTS) within an end-to-end model, yielding promising results. However, the training of these models still relies on parallel speech data, which is extremely challenging to collect. In contrast, S2TT and TTS have accumulated a large amount of data and pretrained models, which have not been fully utilized in the development of S2ST models. Inspired by this, in this paper, we first introduce a composite S2ST model named ComSpeech, which can seamlessly integrate any pretrained S2TT and TTS models into a direct S2ST model. Furthermore, to eliminate the reliance on parallel speech data, we propose a novel training method ComSpeech-ZS that solely utilizes S2TT and TTS data. It aligns representations in the latent space through contrastive learning, enabling the speech synthesis capability learned from the TTS data to generalize to S2ST in a zero-shot manner. Experimental results on the CVSS dataset show that when the parallel speech data is available, ComSpeech surpasses previous two-pass models like UnitY and Translatotron 2 in both translation quality and decoding speed. When there is no parallel speech data, ComSpeech-ZS lags behind name by only 0.7 ASR-BLEU and outperforms the cascaded models.
6/12/2024

XTTS: a Massively Multilingual Zero-Shot Text-to-Speech Model
Edresson Casanova, Kelly Davis, Eren Golge, Gorkem Goknar, Iulian Gulea, Logan Hart, Aya Aljafari, Joshua Meyer, Reuben Morais, Samuel Olayemi, Julian Weber
0
0
Most Zero-shot Multi-speaker TTS (ZS-TTS) systems support only a single language. Although models like YourTTS, VALL-E X, Mega-TTS 2, and Voicebox explored Multilingual ZS-TTS they are limited to just a few high/medium resource languages, limiting the applications of these models in most of the low/medium resource languages. In this paper, we aim to alleviate this issue by proposing and making publicly available the XTTS system. Our method builds upon the Tortoise model and adds several novel modifications to enable multilingual training, improve voice cloning, and enable faster training and inference. XTTS was trained in 16 languages and achieved state-of-the-art (SOTA) results in most of them.
6/10/2024
End-to-End Speech-to-Text Translation: A Survey
Nivedita Sethiya, Chandresh Kumar Maurya
0
0
Speech-to-text translation pertains to the task of converting speech signals in a language to text in another language. It finds its application in various domains, such as hands-free communication, dictation, video lecture transcription, and translation, to name a few. Automatic Speech Recognition (ASR), as well as Machine Translation(MT) models, play crucial roles in traditional ST translation, enabling the conversion of spoken language in its original form to written text and facilitating seamless cross-lingual communication. ASR recognizes spoken words, while MT translates the transcribed text into the target language. Such disintegrated models suffer from cascaded error propagation and high resource and training costs. As a result, researchers have been exploring end-to-end (E2E) models for ST translation. However, to our knowledge, there is no comprehensive review of existing works on E2E ST. The present survey, therefore, discusses the work in this direction. Our attempt has been to provide a comprehensive review of models employed, metrics, and datasets used for ST tasks, providing challenges and future research direction with new insights. We believe this review will be helpful to researchers working on various applications of ST models.
6/11/2024
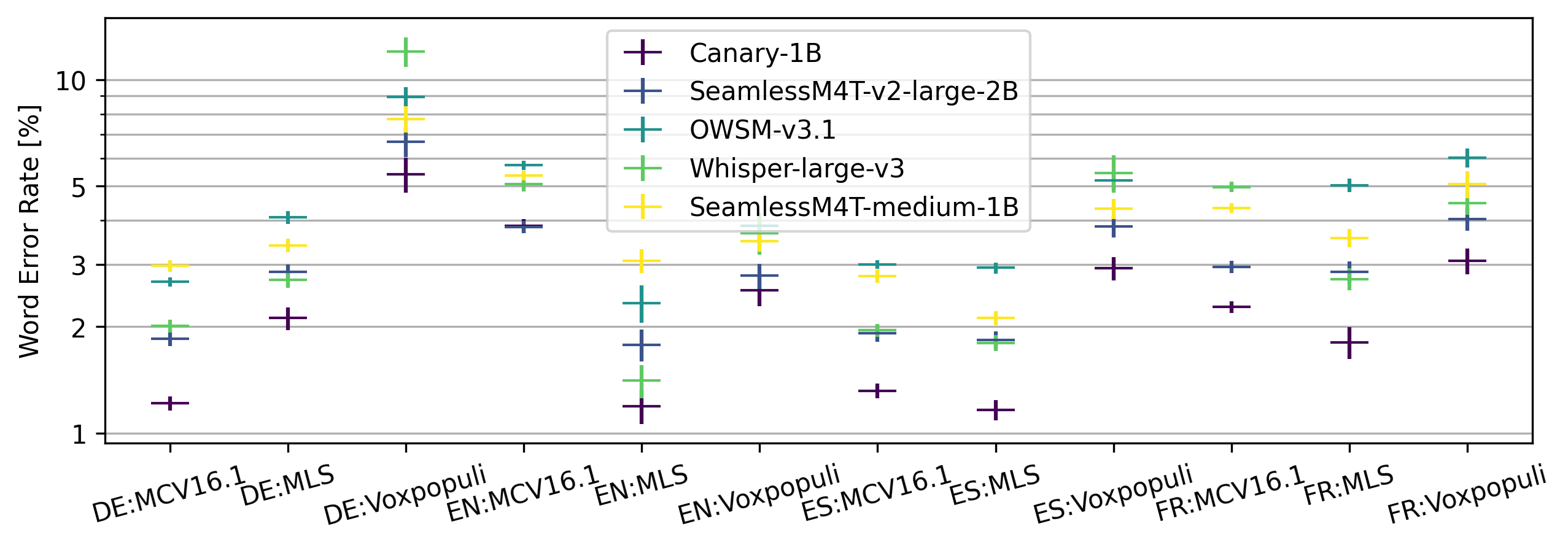
New!Less is More: Accurate Speech Recognition & Translation without Web-Scale Data
Krishna C. Puvvada, Piotr .Zelasko, He Huang, Oleksii Hrinchuk, Nithin Rao Koluguri, Kunal Dhawan, Somshubra Majumdar, Elena Rastorgueva, Zhehuai Chen, Vitaly Lavrukhin, Jagadeesh Balam, Boris Ginsburg
0
0
Recent advances in speech recognition and translation rely on hundreds of thousands of hours of Internet speech data. We argue that state-of-the art accuracy can be reached without relying on web-scale data. Canary - multilingual ASR and speech translation model, outperforms current state-of-the-art models - Whisper, OWSM, and Seamless-M4T on English, French, Spanish, and German languages, while being trained on an order of magnitude less data than these models. Three key factors enables such data-efficient model: (1) a FastConformer-based attention encoder-decoder architecture (2) training on synthetic data generated with machine translation and (3) advanced training techniques: data-balancing, dynamic data blending, dynamic bucketing and noise-robust fine-tuning. The model, weights, and training code will be open-sourced.
7/1/2024