PVAFN: Point-Voxel Attention Fusion Network with Multi-Pooling Enhancing for 3D Object Detection

0

Sign in to get full access
Overview
- This paper proposes a novel 3D object detection network called PVAFN (Point-Voxel Attention Fusion Network) that combines point-based and voxel-based approaches to improve detection performance.
- The key innovations include a point-voxel attention fusion module to effectively integrate multi-scale features, and a multi-pooling enhancement module to capture richer semantic information.
- Experiments on popular 3D object detection benchmarks demonstrate that PVAFN outperforms state-of-the-art methods, highlighting its effectiveness in leveraging both point-wise and grid-based representations.
Plain English Explanation
The paper introduces a new deep learning model called PVAFN (Point-Voxel Attention Fusion Network) for the task of 3D object detection. 3D object detection is the process of identifying and localizing objects in 3D space, such as in point cloud data captured by sensors like LiDAR.
PVAFN combines two common approaches for 3D object detection - point-based methods that directly process the unstructured 3D point cloud data, and voxel-based methods that convert the point cloud into a structured grid-like representation. The key idea is to leverage the strengths of both approaches to achieve better detection performance.
Specifically, PVAFN has two main innovations:
-
Point-Voxel Attention Fusion Module: This module allows the network to effectively integrate multi-scale features from both the point-based and voxel-based representations, using an attention mechanism to selectively focus on the most relevant information.
-
Multi-Pooling Enhancement Module: This module employs multiple pooling operations to capture richer semantic information about the 3D objects, beyond what a single pooling method can provide.
The authors evaluate PVAFN on standard 3D object detection benchmarks and show that it outperforms other state-of-the-art methods. This demonstrates the power of combining point-based and voxel-based approaches, and the effectiveness of the attention fusion and multi-pooling modules in improving 3D object detection.
Technical Explanation
The paper proposes a Point-Voxel Attention Fusion Network (PVAFN) for the task of 3D object detection. PVAFN leverages both point-based and voxel-based representations to effectively capture the 3D object features.
The key components of PVAFN include:
-
Point-Voxel Attention Fusion Module: This module takes in the point-based features and the voxel-based features, and uses an attention mechanism to selectively integrate the most relevant information from each representation. This allows PVAFN to benefit from the strengths of both approaches.
-
Multi-Pooling Enhancement Module: This module applies multiple pooling operations (e.g., max pooling, average pooling, and adaptive pooling) to the fused features, in order to capture richer semantic information about the 3D objects. The resulting multi-scale features are then used for the final object detection.
The authors conduct extensive experiments on popular 3D object detection benchmarks, including KITTI and nuScenes. The results show that PVAFN outperforms other state-of-the-art 3D object detection methods, demonstrating the effectiveness of the proposed point-voxel attention fusion and multi-pooling enhancement techniques.
Critical Analysis
The paper presents a strong technical contribution in the field of 3D object detection, with a well-designed network architecture and thorough experimental validation. However, a few potential limitations and areas for further research can be considered:
-
Computational Complexity: While the attention fusion and multi-pooling modules enhance the network's performance, they may also increase the computational complexity and inference time of the model. The authors could explore ways to optimize the architecture for better efficiency, especially for real-time applications.
-
Generalization to Other Datasets: The evaluation is primarily focused on the KITTI and nuScenes datasets, which have their own unique characteristics. It would be valuable to assess the model's generalization capabilities on a wider range of 3D object detection benchmarks, including indoor or specialized datasets, to better understand its broader applicability.
-
Interpretability and Explainability: The attention mechanism and multi-pooling operations in PVAFN can be seen as "black boxes" to some extent. Providing more insights into how these components contribute to the improved detection performance could enhance the interpretability of the model and lead to further advancements in the field.
-
Real-World Deployment Considerations: While the paper demonstrates strong performance on academic benchmarks, the authors could discuss potential challenges and considerations for deploying PVAFN in real-world 3D object detection scenarios, such as handling sensor noise, occlusions, and varying environmental conditions.
Overall, the PVAFN model presents a promising step forward in leveraging the complementary strengths of point-based and voxel-based representations for 3D object detection. Further exploration of the model's efficiency, generalization, and real-world applicability could lead to even more impactful advancements in this important computer vision task.
Conclusion
This paper introduces the Point-Voxel Attention Fusion Network (PVAFN), a novel deep learning model for 3D object detection. PVAFN combines point-based and voxel-based approaches through a point-voxel attention fusion module and a multi-pooling enhancement module, effectively capturing multi-scale features and rich semantic information.
The experimental results demonstrate that PVAFN outperforms state-of-the-art 3D object detection methods on popular benchmarks, highlighting the benefits of integrating point-based and voxel-based representations. While the paper presents a strong technical contribution, further research could explore ways to optimize the model's efficiency, assess its generalization capabilities, and provide more insights into the interpretability of the attention and multi-pooling components.
Overall, the PVAFN model represents an important step forward in advancing 3D object detection, with the potential to significantly impact applications such as autonomous vehicles, robotics, and augmented reality.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PVAFN: Point-Voxel Attention Fusion Network with Multi-Pooling Enhancing for 3D Object Detection
Yidi Li, Jiahao Wen, Bin Ren, Wenhao Li, Zhenhuan Xu, Hao Guo, Hong Liu, Nicu Sebe
The integration of point and voxel representations is becoming more common in LiDAR-based 3D object detection. However, this combination often struggles with capturing semantic information effectively. Moreover, relying solely on point features within regions of interest can lead to information loss and limitations in local feature representation. To tackle these challenges, we propose a novel two-stage 3D object detector, called Point-Voxel Attention Fusion Network (PVAFN). PVAFN leverages an attention mechanism to improve multi-modal feature fusion during the feature extraction phase. In the refinement stage, it utilizes a multi-pooling strategy to integrate both multi-scale and region-specific information effectively. The point-voxel attention mechanism adaptively combines point cloud and voxel-based Bird's-Eye-View (BEV) features, resulting in richer object representations that help to reduce false detections. Additionally, a multi-pooling enhancement module is introduced to boost the model's perception capabilities. This module employs cluster pooling and pyramid pooling techniques to efficiently capture key geometric details and fine-grained shape structures, thereby enhancing the integration of local and global features. Extensive experiments on the KITTI and Waymo datasets demonstrate that the proposed PVAFN achieves competitive performance. The code and models will be available.
Read more8/28/2024
🔎
0
PVTransformer: Point-to-Voxel Transformer for Scalable 3D Object Detection
Zhaoqi Leng, Pei Sun, Tong He, Dragomir Anguelov, Mingxing Tan
3D object detectors for point clouds often rely on a pooling-based PointNet to encode sparse points into grid-like voxels or pillars. In this paper, we identify that the common PointNet design introduces an information bottleneck that limits 3D object detection accuracy and scalability. To address this limitation, we propose PVTransformer: a transformer-based point-to-voxel architecture for 3D detection. Our key idea is to replace the PointNet pooling operation with an attention module, leading to a better point-to-voxel aggregation function. Our design respects the permutation invariance of sparse 3D points while being more expressive than the pooling-based PointNet. Experimental results show our PVTransformer achieves much better performance compared to the latest 3D object detectors. On the widely used Waymo Open Dataset, our PVTransformer achieves state-of-the-art 76.5 mAPH L2, outperforming the prior art of SWFormer by +1.7 mAPH L2.
Read more5/7/2024
✨
0
PV-SSD: A Multi-Modal Point Cloud Feature Fusion Method for Projection Features and Variable Receptive Field Voxel Features
Yongxin Shao, Aihong Tan, Zhetao Sun, Enhui Zheng, Tianhong Yan, Peng Liao
LiDAR-based 3D object detection and classification is crucial for autonomous driving. However, real-time inference from extremely sparse 3D data is a formidable challenge. To address this problem, a typical class of approaches transforms the point cloud cast into a regular data representation (voxels or projection maps). Then, it performs feature extraction with convolutional neural networks. However, such methods often result in a certain degree of information loss due to down-sampling or over-compression of feature information. This paper proposes a multi-modal point cloud feature fusion method for projection features and variable receptive field voxel features (PV-SSD) based on projection and variable voxelization to solve the information loss problem. We design a two-branch feature extraction structure with a 2D convolutional neural network to extract the point cloud's projection features in bird's-eye view to focus on the correlation between local features. A voxel feature extraction branch is used to extract local fine-grained features. Meanwhile, we propose a voxel feature extraction method with variable sensory fields to reduce the information loss of voxel branches due to downsampling. It avoids missing critical point information by selecting more useful feature points based on feature point weights for the detection task. In addition, we propose a multi-modal feature fusion module for point clouds. To validate the effectiveness of our method, we tested it on the KITTI dataset and ONCE dataset.
Read more4/9/2024
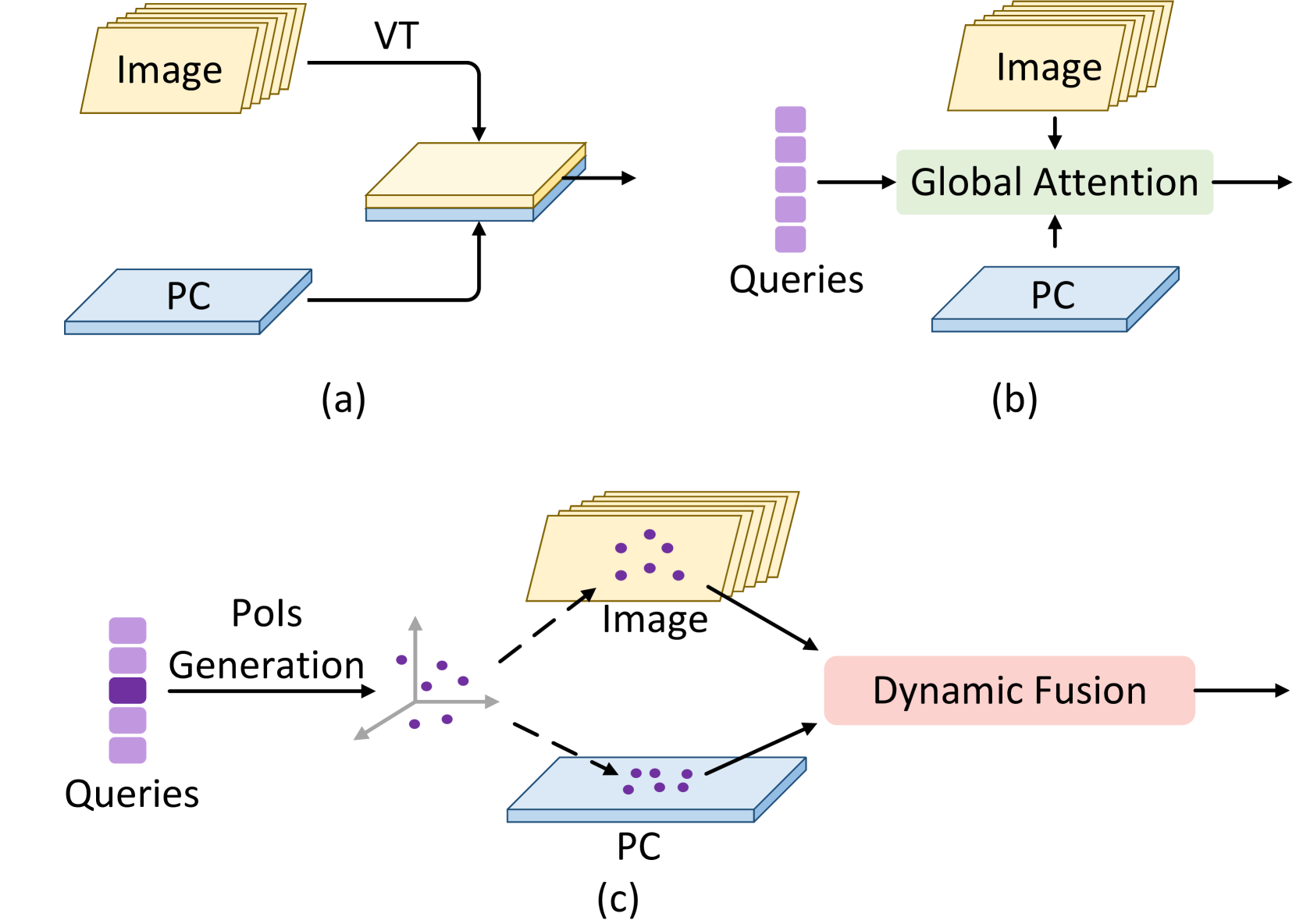
0
PoIFusion: Multi-Modal 3D Object Detection via Fusion at Points of Interest
Jiajun Deng, Sha Zhang, Feras Dayoub, Wanli Ouyang, Yanyong Zhang, Ian Reid
In this work, we present PoIFusion, a conceptually simple yet effective multi-modal 3D object detection framework to fuse the information of RGB images and LiDAR point clouds at the points of interest (PoIs). Different from the most accurate methods to date that transform multi-sensor data into a unified view or leverage the global attention mechanism to facilitate fusion, our approach maintains the view of each modality and obtains multi-modal features by computation-friendly projection and interpolation. In particular, our PoIFusion follows the paradigm of query-based object detection, formulating object queries as dynamic 3D boxes and generating a set of PoIs based on each query box. The PoIs serve as the keypoints to represent a 3D object and play the role of the basic units in multi-modal fusion. Specifically, we project PoIs into the view of each modality to sample the corresponding feature and integrate the multi-modal features at each PoI through a dynamic fusion block. Furthermore, the features of PoIs derived from the same query box are aggregated together to update the query feature. Our approach prevents information loss caused by view transformation and eliminates the computation-intensive global attention, making the multi-modal 3D object detector more applicable. We conducted extensive experiments on nuScenes and Argoverse2 datasets to evaluate our approach. Remarkably, the proposed approach achieves state-of-the-art results on both datasets without any bells and whistles, emph{i.e.}, 74.9% NDS and 73.4% mAP on nuScenes, and 31.6% CDS and 40.6% mAP on Argoverse2. The code will be made available at url{https://djiajunustc.github.io/projects/poifusion}.
Read more9/24/2024