Q-Bench+: A Benchmark for Multi-modal Foundation Models on Low-level Vision from Single Images to Pairs

0

Sign in to get full access
Overview
- The paper presents a new benchmark dataset called LLVisionQA+ for evaluating multi-modal foundation models on low-level vision tasks like image description and visual question answering.
- The dataset covers a range of single image and image pair tasks, aiming to provide a comprehensive assessment of multi-modal model capabilities.
- The paper also reports initial results on the benchmark using several prominent multi-modal models, providing insights into their performance and limitations.
Plain English Explanation
The paper introduces a new dataset called LLVisionQA+ that is designed to test the abilities of large language models (LLMs) to work with visual information. These multi-modal models are trained on both text and images, and the LLVisionQA+ benchmark evaluates how well they can perform tasks like describing single images and answering questions about image pairs.
The goal is to provide a comprehensive assessment of these models' "low-level" vision capabilities - the ability to perceive and reason about basic visual elements, rather than just recognizing high-level objects or scenes. This is an important capability for models that aim to understand and interact with the real world.
The paper presents initial results using several prominent multi-modal models on the LLVisionQA+ benchmark. These results give insights into the current strengths and limitations of these models when it comes to low-level visual understanding.
Technical Explanation
The LLVisionQA+ dataset consists of over 100,000 images and associated text annotations, spanning single image and image pair tasks. The single image tasks include image description and visual question answering, while the image pair tasks focus on comparing and reasoning about relationships between two images.
The authors evaluate several well-known multi-modal models on the LLVisionQA+ benchmark, including CLIP, ViLBERT, and FLORENCE. They find that these models generally perform well on single image tasks, but struggle more on the more complex image pair reasoning tasks.
The paper provides a detailed analysis of the models' performance, highlighting areas where they excel and where they fall short. For example, the models show strong performance on tasks like identifying objects and colors, but have more difficulty with spatial and relational reasoning.
Critical Analysis
The authors acknowledge several limitations of the LLVisionQA+ benchmark, such as the potential for bias in the dataset and the need for more complex reasoning tasks. They also note that the benchmark only evaluates a narrow set of low-level vision capabilities, and call for the development of even more comprehensive multi-modal benchmarks in the future.
One potential issue not discussed in the paper is the reliance on existing multi-modal models, which may not fully capture the potential of emerging architectures and training approaches. As the field of multi-modal AI continues to rapidly evolve, it will be important to regularly update and expand benchmarks like LLVisionQA+ to keep pace with the latest advancements.
Conclusion
The LLVisionQA+ benchmark presents a valuable tool for assessing the low-level visual understanding capabilities of multi-modal foundation models. The initial results provide important insights into the current state of the art, and the authors' call for more comprehensive multi-modal benchmarks is well-justified.
As multi-modal AI continues to advance, tools like LLVisionQA+ will play a crucial role in tracking progress, identifying areas for improvement, and ultimately driving the development of models that can truly understand and interact with the complex visual world around us.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Q-Bench+: A Benchmark for Multi-modal Foundation Models on Low-level Vision from Single Images to Pairs
Zicheng Zhang, Haoning Wu, Erli Zhang, Guangtao Zhai, Weisi Lin
The rapid development of Multi-modality Large Language Models (MLLMs) has navigated a paradigm shift in computer vision, moving towards versatile foundational models. However, evaluating MLLMs in low-level visual perception and understanding remains a yet-to-explore domain. To this end, we design benchmark settings to emulate human language responses related to low-level vision: the low-level visual perception (A1) via visual question answering related to low-level attributes (e.g. clarity, lighting); and the low-level visual description (A2), on evaluating MLLMs for low-level text descriptions. Furthermore, given that pairwise comparison can better avoid ambiguity of responses and has been adopted by many human experiments, we further extend the low-level perception-related question-answering and description evaluations of MLLMs from single images to image pairs. Specifically, for perception (A1), we carry out the LLVisionQA+ dataset, comprising 2,990 single images and 1,999 image pairs each accompanied by an open-ended question about its low-level features; for description (A2), we propose the LLDescribe+ dataset, evaluating MLLMs for low-level descriptions on 499 single images and 450 pairs. Additionally, we evaluate MLLMs on assessment (A3) ability, i.e. predicting score, by employing a softmax-based approach to enable all MLLMs to generate quantifiable quality ratings, tested against human opinions in 7 image quality assessment (IQA) datasets. With 24 MLLMs under evaluation, we demonstrate that several MLLMs have decent low-level visual competencies on single images, but only GPT-4V exhibits higher accuracy on pairwise comparisons than single image evaluations (like humans). We hope that our benchmark will motivate further research into uncovering and enhancing these nascent capabilities of MLLMs. Datasets will be available at https://github.com/Q-Future/Q-Bench.
Read more8/13/2024

0
MMBench: Is Your Multi-modal Model an All-around Player?
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, Kai Chen, Dahua Lin
Large vision-language models (VLMs) have recently achieved remarkable progress, exhibiting impressive multimodal perception and reasoning abilities. However, effectively evaluating these large VLMs remains a major challenge, hindering future development in this domain. Traditional benchmarks like VQAv2 or COCO Caption provide quantitative performance measurements but lack fine-grained ability assessment and robust evaluation metrics. Meanwhile, subjective benchmarks, such as OwlEval, offer comprehensive evaluations of a model's abilities by incorporating human labor, which is not scalable and may display significant bias. In response to these challenges, we propose MMBench, a bilingual benchmark for assessing the multi-modal capabilities of VLMs. MMBench methodically develops a comprehensive evaluation pipeline, primarily comprised of the following key features: 1. MMBench is meticulously curated with well-designed quality control schemes, surpassing existing similar benchmarks in terms of the number and variety of evaluation questions and abilities; 2. MMBench introduces a rigorous CircularEval strategy and incorporates large language models to convert free-form predictions into pre-defined choices, which helps to yield accurate evaluation results for models with limited instruction-following capabilities. 3. MMBench incorporates multiple-choice questions in both English and Chinese versions, enabling an apples-to-apples comparison of VLMs' performance under a bilingual context. To summarize, MMBench is a systematically designed objective benchmark for a robust and holistic evaluation of vision-language models. We hope MMBench will assist the research community in better evaluating their models and facilitate future progress in this area. The evalutation code of MMBench has been integrated into VLMEvalKit: https://github.com/open-compass/VLMEvalKit.
Read more8/21/2024

0
A Survey on Benchmarks of Multimodal Large Language Models
Jian Li, Weiheng Lu, Hao Fei, Meng Luo, Ming Dai, Min Xia, Yizhang Jin, Zhenye Gan, Ding Qi, Chaoyou Fu, Ying Tai, Wankou Yang, Yabiao Wang, Chengjie Wang
Multimodal Large Language Models (MLLMs) are gaining increasing popularity in both academia and industry due to their remarkable performance in various applications such as visual question answering, visual perception, understanding, and reasoning. Over the past few years, significant efforts have been made to examine MLLMs from multiple perspectives. This paper presents a comprehensive review of 200 benchmarks and evaluations for MLLMs, focusing on (1)perception and understanding, (2)cognition and reasoning, (3)specific domains, (4)key capabilities, and (5)other modalities. Finally, we discuss the limitations of the current evaluation methods for MLLMs and explore promising future directions. Our key argument is that evaluation should be regarded as a crucial discipline to support the development of MLLMs better. For more details, please visit our GitHub repository: https://github.com/swordlidev/Evaluation-Multimodal-LLMs-Survey.
Read more9/9/2024
0
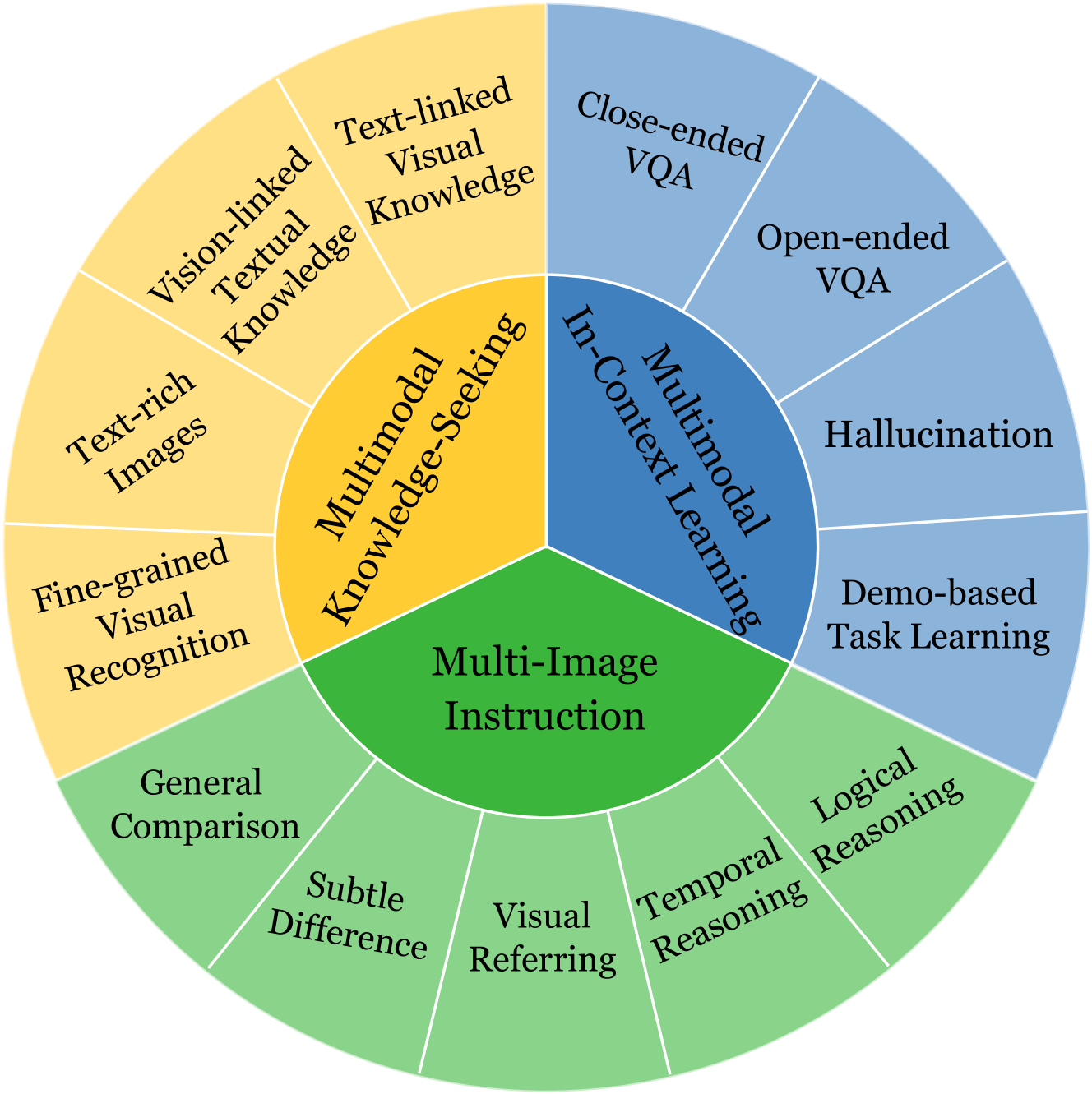
MIBench: Evaluating Multimodal Large Language Models over Multiple Images
Haowei Liu, Xi Zhang, Haiyang Xu, Yaya Shi, Chaoya Jiang, Ming Yan, Ji Zhang, Fei Huang, Chunfeng Yuan, Bing Li, Weiming Hu
Built on the power of LLMs, numerous multimodal large language models (MLLMs) have recently achieved remarkable performance on various vision-language tasks across multiple benchmarks. However, most existing MLLMs and benchmarks primarily focus on single-image input scenarios, leaving the performance of MLLMs when handling realistic multiple images remain underexplored. Although a few benchmarks consider multiple images, their evaluation dimensions and samples are very limited. Therefore, in this paper, we propose a new benchmark MIBench, to comprehensively evaluate fine-grained abilities of MLLMs in multi-image scenarios. Specifically, MIBench categorizes the multi-image abilities into three scenarios: multi-image instruction (MII), multimodal knowledge-seeking (MKS) and multimodal in-context learning (MIC), and constructs 13 tasks with a total of 13K annotated samples. During data construction, for MII and MKS, we extract correct options from manual annotations and create challenging distractors to obtain multiple-choice questions. For MIC, to enable an in-depth evaluation, we set four sub-tasks and transform the original datasets into in-context learning formats. We evaluate several open-source MLLMs and close-source MLLMs on the proposed MIBench. The results reveal that although current models excel in single-image tasks, they exhibit significant shortcomings when faced with multi-image inputs, such as confused fine-grained perception, limited multi-image reasoning, and unstable in-context learning. The annotated data in MIBench is available at https://huggingface.co/datasets/StarBottle/MIBench.
Read more7/23/2024