Q*: Improving Multi-step Reasoning for LLMs with Deliberative Planning
2406.14283
32
0

Abstract
Large Language Models (LLMs) have demonstrated impressive capability in many natural language tasks. However, the auto-regressive generation process makes LLMs prone to produce errors, hallucinations and inconsistent statements when performing multi-step reasoning. In this paper, by casting multi-step reasoning of LLMs as a heuristic search problem, we aim to alleviate the pathology by introducing Q*, a general, versatile and agile framework for guiding LLMs decoding process with deliberative planning. By learning a plug-and-play Q-value model as heuristic function for estimating expected future rewards, our Q* can effectively guide LLMs to select the most promising next reasoning step without fine-tuning LLMs for the current task, which avoids the significant computational overhead and potential risk of performance degeneration on other tasks. Extensive experiments on GSM8K, MATH and MBPP demonstrate the superiority of our method, contributing to improving the reasoning performance of existing open-source LLMs.
Create account to get full access
Overview
- This paper, "Q*: Improving Multi-step Reasoning for LLMs with Deliberative Planning", explores a new approach to enhance the multi-step reasoning capabilities of large language models (LLMs).
- The key idea is to integrate a deliberative planning module with LLMs, allowing them to plan their actions and reasoning steps more effectively.
- The proposed framework, called Q*, combines the strengths of LLMs and a planning system to tackle complex, multi-step reasoning tasks.
Plain English Explanation
Large language models (LLMs) like GPT-3 are impressive at generating human-like text, but they often struggle with complex, multi-step reasoning tasks. This paper introduces a new approach called Q* that aims to address this limitation.
The core idea behind Q* is to combine the powerful language understanding and generation abilities of LLMs with a deliberative planning module. This planning component helps the LLM break down a problem into a series of steps, plan the best course of action, and then execute those steps in a more organized and effective manner.
Imagine you're trying to solve a complex logic puzzle. An LLM on its own might struggle to keep track of all the different pieces and come up with a coherent, multi-step solution. But with Q*, the LLM can first plan out the different moves it needs to make, step-by-step, before actually executing the solution. This planning process allows the LLM to tackle more complicated, multi-faceted problems that require sustained, logical reasoning.
The researchers demonstrate the effectiveness of Q* on a variety of challenging reasoning tasks, showing that it can outperform traditional LLMs in terms of accuracy and task completion. By blending the strengths of language models and planning systems, Q* represents a promising step towards building AI systems that can engage in more human-like, deliberative problem-solving.
Technical Explanation
The key innovation in this paper is the integration of a deliberative planning module with large language models (LLMs) to enhance their multi-step reasoning capabilities. The proposed framework, called Q*, combines an LLM with a planning system that can break down complex tasks into a sequence of actionable steps.
At the heart of Q* is a neural planner that learns to generate a plan of action given the initial problem statement and the LLM's current state of understanding. This planning module takes into account the constraints and dependencies of the task, and outputs a step-by-step plan for the LLM to execute.
The LLM then uses this plan to guide its language generation and reasoning, producing outputs that align with the planned course of action. By tightly coupling the planning and language components, Q* is able to tackle complex, multi-step problems that traditional LLMs would struggle with.
The researchers evaluate Q* on a range of reasoning tasks, including logical inference, multi-hop question answering, and procedural task completion. They find that Q* consistently outperforms standalone LLM baselines, demonstrating the value of integrating deliberative planning into language models.
One key insight from the paper is that the planning module not only guides the LLM's reasoning, but also helps it better understand and represent the underlying structure of the task. This structural awareness allows Q* to generalize better to novel problem instances, compared to LLMs that rely more on pattern matching.
Critical Analysis
The Q* framework represents an important step forward in addressing the limitations of current large language models when it comes to complex, multi-step reasoning. By incorporating a planning component, the authors have shown that LLMs can be made more systematic and deliberative in their problem-solving approach.
However, the paper also highlights some potential challenges and areas for further research. For example, the planning module in Q* is relatively simple and may struggle with more open-ended or ambiguous tasks. Integrating more advanced planning techniques, such as the ones explored in this paper, could further enhance Q*'s capabilities.
Additionally, the evaluation in this paper is limited to well-defined reasoning tasks. It would be valuable to see how Q* performs on more real-world, open-ended problems that require a combination of language understanding, planning, and execution.
Another area for future work is to better understand the interplay between the LLM and planning components in Q*. This paper provides a useful framework for analyzing the theoretical underpinnings of such hybrid systems.
Overall, the Q* framework is a promising step towards building AI systems that can engage in more human-like, deliberative problem-solving. By combining the strengths of language models and planning systems, the authors have demonstrated the potential to create more capable and transparent reasoning agents. Further research in this direction, as explored in this paper and this one, could lead to significant advancements in the field of artificial intelligence.
Conclusion
The Q* framework presented in this paper represents an important advancement in the quest to improve the multi-step reasoning capabilities of large language models. By integrating a deliberative planning module, the authors have shown how LLMs can be made more systematic and effective at tackling complex, multi-faceted problems.
The key insights from this work are the power of combining language understanding and generation with explicit planning, and the benefits of imbuing LLMs with a deeper structural awareness of the tasks they are trying to solve. These ideas have the potential to drive significant progress in building more capable and transparent AI systems that can engage in human-like, deliberative problem-solving.
While the current evaluation of Q* is promising, further research is needed to explore its performance on more open-ended, real-world tasks, and to integrate more advanced planning techniques. Nonetheless, this paper lays the groundwork for an exciting new direction in the field of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

LLMs Can't Plan, But Can Help Planning in LLM-Modulo Frameworks
Subbarao Kambhampati, Karthik Valmeekam, Lin Guan, Mudit Verma, Kaya Stechly, Siddhant Bhambri, Lucas Saldyt, Anil Murthy
0
0
There is considerable confusion about the role of Large Language Models (LLMs) in planning and reasoning tasks. On one side are over-optimistic claims that LLMs can indeed do these tasks with just the right prompting or self-verification strategies. On the other side are perhaps over-pessimistic claims that all that LLMs are good for in planning/reasoning tasks are as mere translators of the problem specification from one syntactic format to another, and ship the problem off to external symbolic solvers. In this position paper, we take the view that both these extremes are misguided. We argue that auto-regressive LLMs cannot, by themselves, do planning or self-verification (which is after all a form of reasoning), and shed some light on the reasons for misunderstandings in the literature. We will also argue that LLMs should be viewed as universal approximate knowledge sources that have much more meaningful roles to play in planning/reasoning tasks beyond simple front-end/back-end format translators. We present a vision of {bf LLM-Modulo Frameworks} that combine the strengths of LLMs with external model-based verifiers in a tighter bi-directional interaction regime. We will show how the models driving the external verifiers themselves can be acquired with the help of LLMs. We will also argue that rather than simply pipelining LLMs and symbolic components, this LLM-Modulo Framework provides a better neuro-symbolic approach that offers tighter integration between LLMs and symbolic components, and allows extending the scope of model-based planning/reasoning regimes towards more flexible knowledge, problem and preference specifications.
6/13/2024
💬
Plan of Thoughts: Heuristic-Guided Problem Solving with Large Language Models
Houjun Liu
0
0
While language models (LMs) offer significant capability in zero-shot reasoning tasks across a wide range of domains, they do not perform satisfactorily in problems which requires multi-step reasoning. Previous approaches to mitigate this involves breaking a larger, multi-step task into sub-tasks and asking the language model to generate proposals (thoughts) for each sub-task and using exhaustive planning approaches such as DFS to compose a solution. In this work, we leverage this idea to introduce two new contributions: first, we formalize a planning-based approach to perform multi-step problem solving with LMs via Partially Observable Markov Decision Processes (POMDPs), with the LM's own reflections about the value of a state used as a search heuristic; second, leveraging the online POMDP solver POMCP, we demonstrate a superior success rate of 89.4% on the Game of 24 task as compared to existing approaches while also offering better anytime performance characteristics than fixed tree-search which is used previously. Taken together, these contributions allow modern LMs to decompose and solve larger-scale reasoning tasks more effectively.
5/1/2024
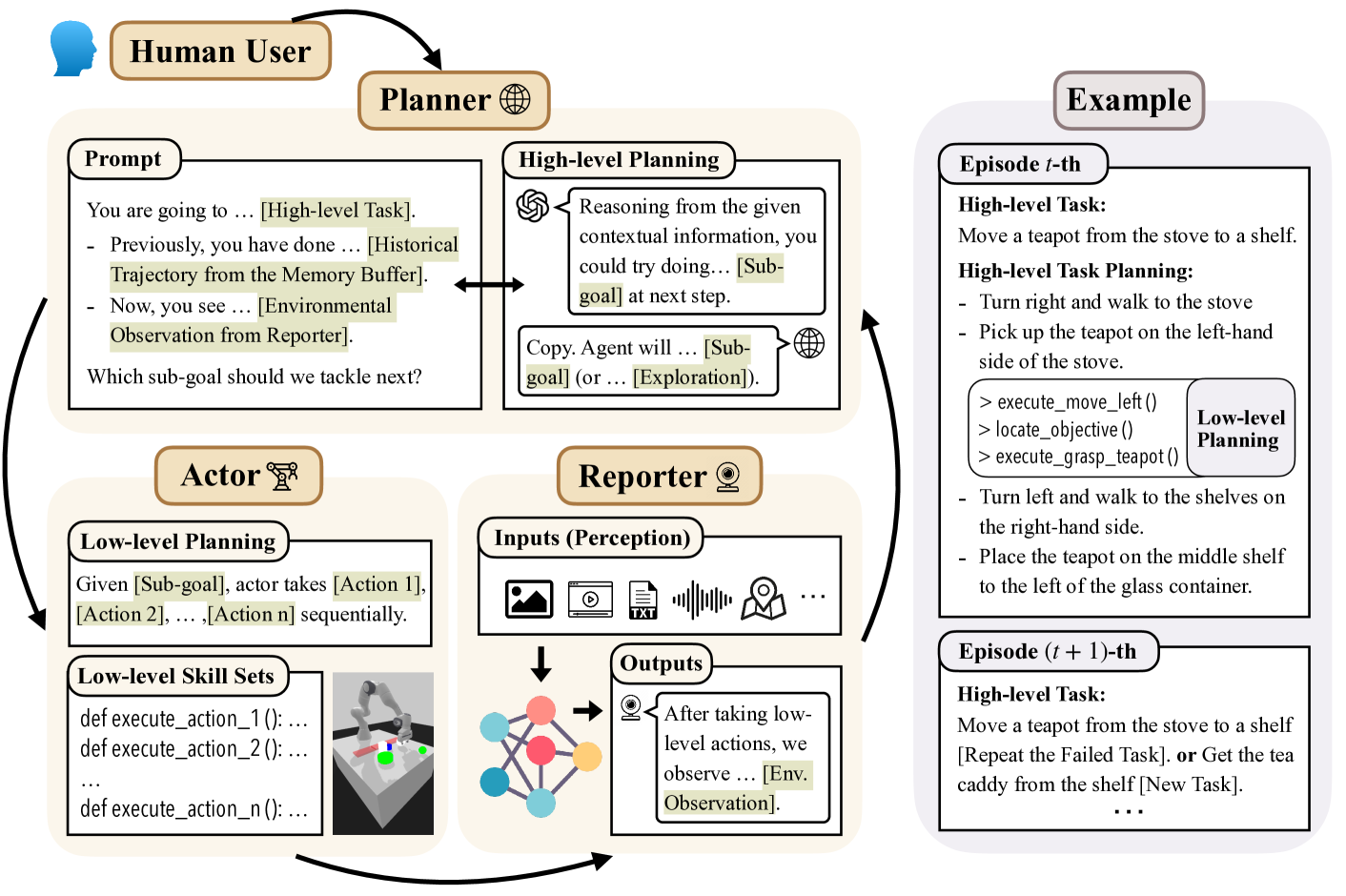
From Words to Actions: Unveiling the Theoretical Underpinnings of LLM-Driven Autonomous Systems
Jianliang He, Siyu Chen, Fengzhuo Zhang, Zhuoran Yang
0
0
In this work, from a theoretical lens, we aim to understand why large language model (LLM) empowered agents are able to solve decision-making problems in the physical world. To this end, consider a hierarchical reinforcement learning (RL) model where the LLM Planner and the Actor perform high-level task planning and low-level execution, respectively. Under this model, the LLM Planner navigates a partially observable Markov decision process (POMDP) by iteratively generating language-based subgoals via prompting. Under proper assumptions on the pretraining data, we prove that the pretrained LLM Planner effectively performs Bayesian aggregated imitation learning (BAIL) through in-context learning. Additionally, we highlight the necessity for exploration beyond the subgoals derived from BAIL by proving that naively executing the subgoals returned by LLM leads to a linear regret. As a remedy, we introduce an $epsilon$-greedy exploration strategy to BAIL, which is proven to incur sublinear regret when the pretraining error is small. Finally, we extend our theoretical framework to include scenarios where the LLM Planner serves as a world model for inferring the transition model of the environment and to multi-agent settings, enabling coordination among multiple Actors.
5/31/2024
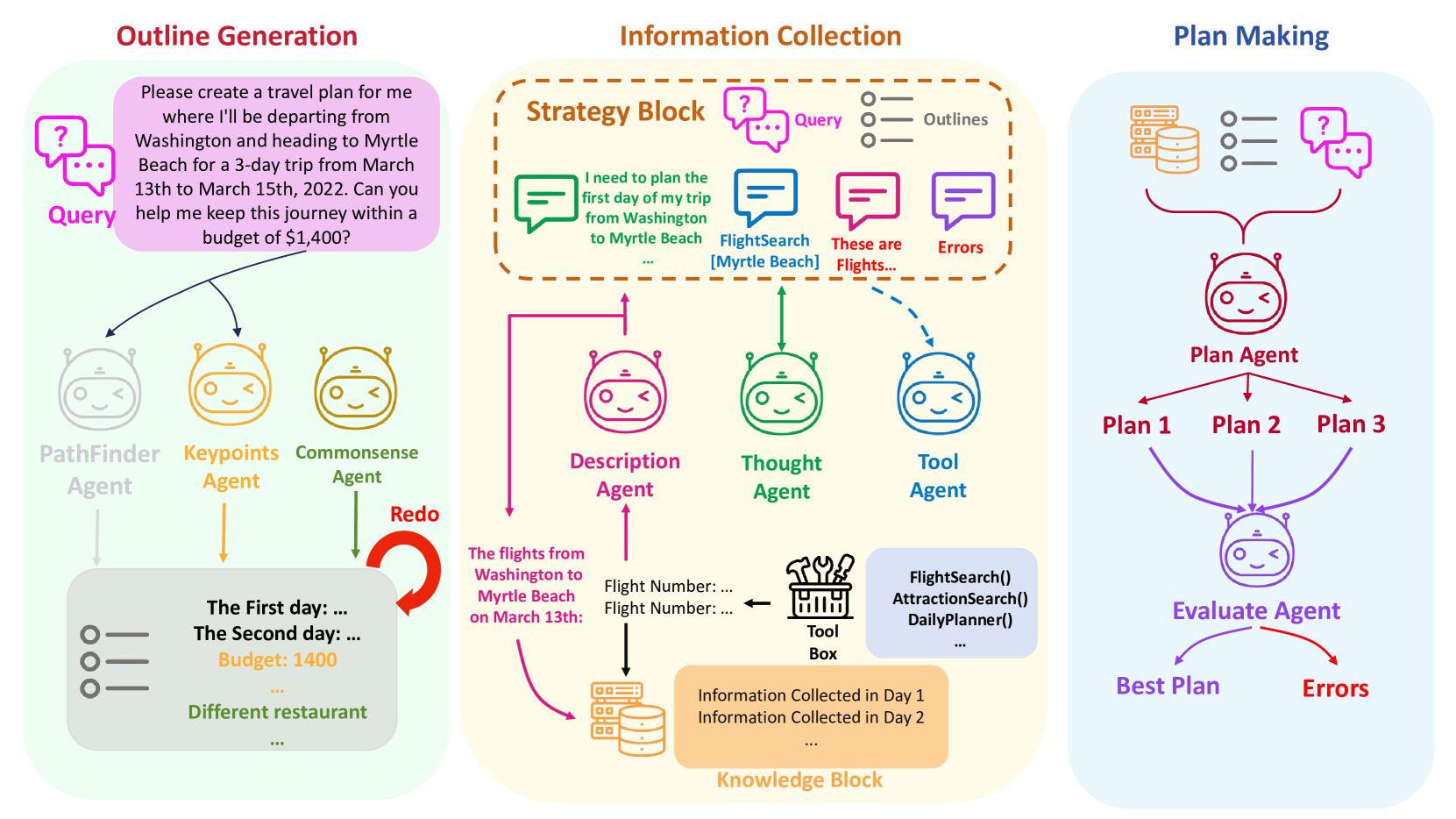
A Human-Like Reasoning Framework for Multi-Phases Planning Task with Large Language Models
Chengxing Xie, Difan Zou
0
0
Recent studies have highlighted their proficiency in some simple tasks like writing and coding through various reasoning strategies. However, LLM agents still struggle with tasks that require comprehensive planning, a process that challenges current models and remains a critical research issue. In this study, we concentrate on travel planning, a Multi-Phases planning problem, that involves multiple interconnected stages, such as outlining, information gathering, and planning, often characterized by the need to manage various constraints and uncertainties. Existing reasoning approaches have struggled to effectively address this complex task. Our research aims to address this challenge by developing a human-like planning framework for LLM agents, i.e., guiding the LLM agent to simulate various steps that humans take when solving Multi-Phases problems. Specifically, we implement several strategies to enable LLM agents to generate a coherent outline for each travel query, mirroring human planning patterns. Additionally, we integrate Strategy Block and Knowledge Block into our framework: Strategy Block facilitates information collection, while Knowledge Block provides essential information for detailed planning. Through our extensive experiments, we demonstrate that our framework significantly improves the planning capabilities of LLM agents, enabling them to tackle the travel planning task with improved efficiency and effectiveness. Our experimental results showcase the exceptional performance of the proposed framework; when combined with GPT-4-Turbo, it attains $10times$ the performance gains in comparison to the baseline framework deployed on GPT-4-Turbo.
5/29/2024