Plan of Thoughts: Heuristic-Guided Problem Solving with Large Language Models
2404.19055
0
0
💬
Abstract
While language models (LMs) offer significant capability in zero-shot reasoning tasks across a wide range of domains, they do not perform satisfactorily in problems which requires multi-step reasoning. Previous approaches to mitigate this involves breaking a larger, multi-step task into sub-tasks and asking the language model to generate proposals (thoughts) for each sub-task and using exhaustive planning approaches such as DFS to compose a solution. In this work, we leverage this idea to introduce two new contributions: first, we formalize a planning-based approach to perform multi-step problem solving with LMs via Partially Observable Markov Decision Processes (POMDPs), with the LM's own reflections about the value of a state used as a search heuristic; second, leveraging the online POMDP solver POMCP, we demonstrate a superior success rate of 89.4% on the Game of 24 task as compared to existing approaches while also offering better anytime performance characteristics than fixed tree-search which is used previously. Taken together, these contributions allow modern LMs to decompose and solve larger-scale reasoning tasks more effectively.
Create account to get full access
Overview
- Language models (LMs) can excel at zero-shot reasoning tasks, but struggle with multi-step problems
- Previous approaches involve breaking larger tasks into sub-tasks and using search algorithms to compose solutions
- This paper introduces two key contributions:
- A planning-based approach to multi-step problem-solving with LMs using Partially Observable Markov Decision Processes (POMDPs)
- Leveraging the online POMDP solver POMCP to achieve a 89.4% success rate on the Game of 24 task, with better anytime performance than fixed tree-search
Plain English Explanation
Large language models (LLMs) like GPT-3 are incredibly capable at a wide variety of tasks, from answering questions to generating text. However, they struggle when it comes to solving problems that require multiple steps of reasoning. Previous research has looked at ways to address this by breaking down larger tasks into smaller sub-tasks, and then using search algorithms to piece together a full solution.
In this paper, the researchers take a different approach. They formalize the problem-solving process as a Partially Observable Markov Decision Process (POMDP), where the LLM's own reflections on the value of each state are used as a heuristic to guide the search. By leveraging an online POMDP solver called POMCP, they are able to achieve a 89.4% success rate on the Game of 24 task - a significant improvement over previous approaches.
This work demonstrates how modern LLMs can be used to tackle more complex, multi-step reasoning tasks by incorporating their language understanding capabilities into a principled planning framework. This could have important implications for building AI systems that can solve real-world problems more effectively.
Technical Explanation
The key idea behind this research is to formalize the process of multi-step problem-solving with LMs as a Partially Observable Markov Decision Process (POMDP). In a POMDP, the agent (in this case, the LM) must make decisions based on incomplete information about the current state of the environment.
The researchers leverage the LM's own reflections on the value of each state as a search heuristic to guide the planning process. This is implemented using the POMCP algorithm, an online POMDP solver that can efficiently explore the search space and compose solutions to the overall task.
To evaluate their approach, the researchers applied it to the Game of 24 task, where the goal is to combine a set of numbers using basic arithmetic operations to reach the target value of 24. They found that their POMDP-based method achieved a 89.4% success rate, significantly outperforming previous approaches that relied on fixed tree-search.
Importantly, the POMDP-based method also demonstrated better "anytime" performance, meaning it could return a reasonably good solution even if the search was interrupted before completion. This is a valuable property for real-world applications where computation time may be limited.
Critical Analysis
The researchers have made a compelling case for their POMDP-based approach to multi-step problem-solving with LMs. By leveraging the LM's own reflections on the value of different states, they are able to guide the search process more effectively than previous methods that relied on fixed tree-search.
However, it's worth noting that the Game of 24 task, while challenging, is still a relatively constrained and well-defined problem. It remains to be seen how well this approach would scale to more open-ended, real-world problems that may involve greater ambiguity and uncertainty.
Additionally, the paper does not delve into the potential limitations or failure modes of this approach. For example, it's possible that the LM's value estimates could be biased or inaccurate in certain situations, leading the search process astray. Further research and testing would be needed to better understand the robustness and generalizability of this method.
Finally, it would be interesting to explore how this POMDP-based approach could be combined with other techniques, such as the use of smaller, more specialized language models to assist the larger LM, potentially further enhancing its multi-step reasoning capabilities.
Conclusion
This paper presents a novel approach to enabling large language models to tackle more complex, multi-step reasoning tasks. By formulating the problem-solving process as a POMDP and leveraging the LM's own reflections as a search heuristic, the researchers have demonstrated significant improvements in success rates and anytime performance compared to previous methods.
While there are still open questions and potential limitations to address, this work represents an important step forward in bridging the gap between the impressive zero-shot capabilities of LMs and their ability to engage in more structured, multi-step reasoning. As AI systems continue to become more sophisticated, approaches like this could play a crucial role in unlocking the full potential of language models to tackle real-world problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
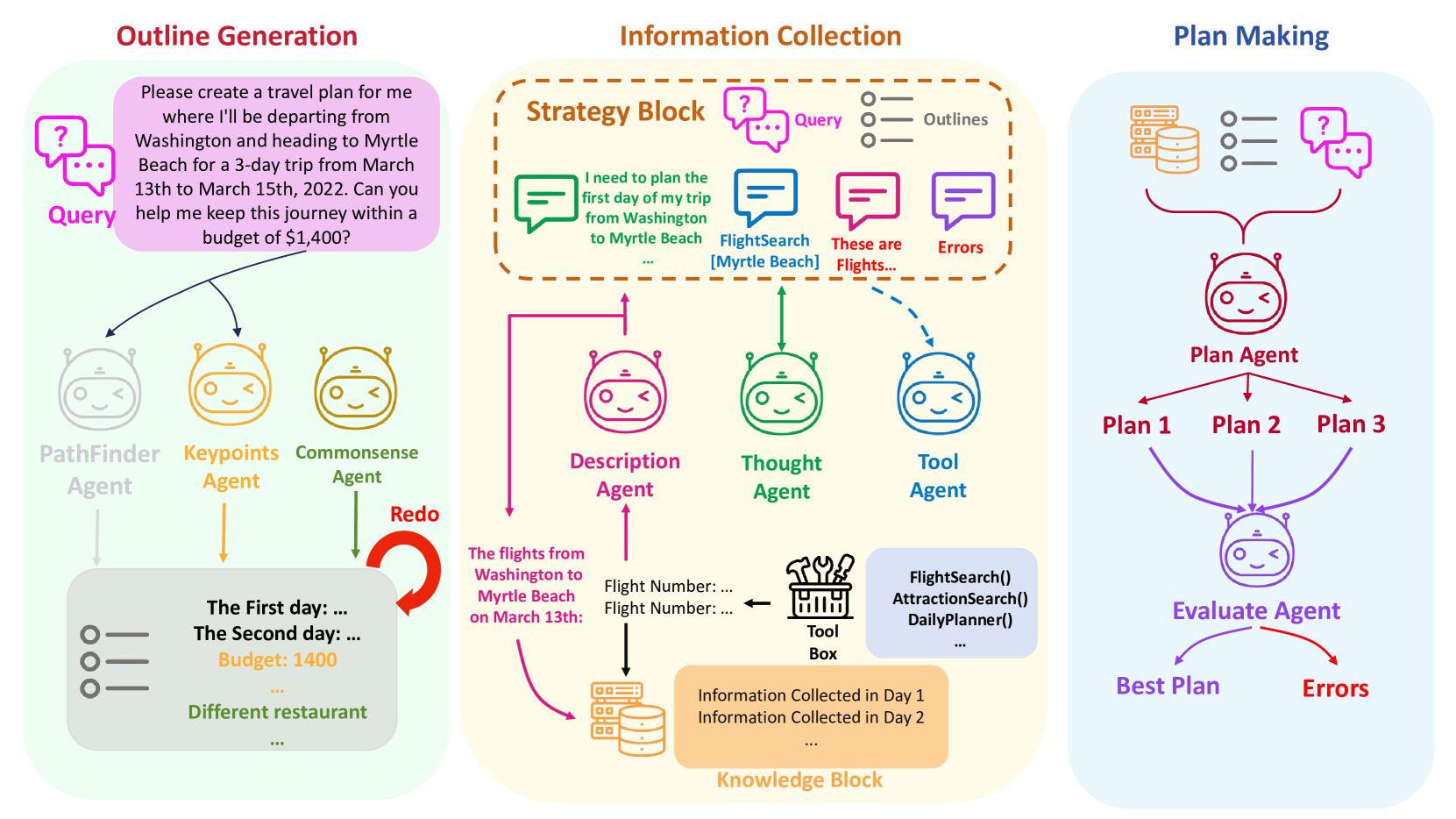
A Human-Like Reasoning Framework for Multi-Phases Planning Task with Large Language Models
Chengxing Xie, Difan Zou
0
0
Recent studies have highlighted their proficiency in some simple tasks like writing and coding through various reasoning strategies. However, LLM agents still struggle with tasks that require comprehensive planning, a process that challenges current models and remains a critical research issue. In this study, we concentrate on travel planning, a Multi-Phases planning problem, that involves multiple interconnected stages, such as outlining, information gathering, and planning, often characterized by the need to manage various constraints and uncertainties. Existing reasoning approaches have struggled to effectively address this complex task. Our research aims to address this challenge by developing a human-like planning framework for LLM agents, i.e., guiding the LLM agent to simulate various steps that humans take when solving Multi-Phases problems. Specifically, we implement several strategies to enable LLM agents to generate a coherent outline for each travel query, mirroring human planning patterns. Additionally, we integrate Strategy Block and Knowledge Block into our framework: Strategy Block facilitates information collection, while Knowledge Block provides essential information for detailed planning. Through our extensive experiments, we demonstrate that our framework significantly improves the planning capabilities of LLM agents, enabling them to tackle the travel planning task with improved efficiency and effectiveness. Our experimental results showcase the exceptional performance of the proposed framework; when combined with GPT-4-Turbo, it attains $10times$ the performance gains in comparison to the baseline framework deployed on GPT-4-Turbo.
5/29/2024
Reinforcement Learning Problem Solving with Large Language Models
Sina Gholamian, Domingo Huh
0
0
Large Language Models (LLMs) encapsulate an extensive amount of world knowledge, and this has enabled their application in various domains to improve the performance of a variety of Natural Language Processing (NLP) tasks. This has also facilitated a more accessible paradigm of conversation-based interactions between humans and AI systems to solve intended problems. However, one interesting avenue that shows untapped potential is the use of LLMs as Reinforcement Learning (RL) agents to enable conversational RL problem solving. Therefore, in this study, we explore the concept of formulating Markov Decision Process-based RL problems as LLM prompting tasks. We demonstrate how LLMs can be iteratively prompted to learn and optimize policies for specific RL tasks. In addition, we leverage the introduced prompting technique for episode simulation and Q-Learning, facilitated by LLMs. We then show the practicality of our approach through two detailed case studies for Research Scientist and Legal Matter Intake workflows.
4/30/2024

Q*: Improving Multi-step Reasoning for LLMs with Deliberative Planning
Chaojie Wang, Yanchen Deng, Zhiyi Lv, Zeng Liang, Jujie He, Shuicheng Yan, An Bo
0
0
Large Language Models (LLMs) have demonstrated impressive capability in many natural language tasks. However, the auto-regressive generation process makes LLMs prone to produce errors, hallucinations and inconsistent statements when performing multi-step reasoning. In this paper, by casting multi-step reasoning of LLMs as a heuristic search problem, we aim to alleviate the pathology by introducing Q*, a general, versatile and agile framework for guiding LLMs decoding process with deliberative planning. By learning a plug-and-play Q-value model as heuristic function for estimating expected future rewards, our Q* can effectively guide LLMs to select the most promising next reasoning step without fine-tuning LLMs for the current task, which avoids the significant computational overhead and potential risk of performance degeneration on other tasks. Extensive experiments on GSM8K, MATH and MBPP demonstrate the superiority of our method, contributing to improving the reasoning performance of existing open-source LLMs.
6/28/2024
💬
Large Language Models as Planning Domain Generators
James Oswald, Kavitha Srinivas, Harsha Kokel, Junkyu Lee, Michael Katz, Shirin Sohrabi
0
0
Developing domain models is one of the few remaining places that require manual human labor in AI planning. Thus, in order to make planning more accessible, it is desirable to automate the process of domain model generation. To this end, we investigate if large language models (LLMs) can be used to generate planning domain models from simple textual descriptions. Specifically, we introduce a framework for automated evaluation of LLM-generated domains by comparing the sets of plans for domain instances. Finally, we perform an empirical analysis of 7 large language models, including coding and chat models across 9 different planning domains, and under three classes of natural language domain descriptions. Our results indicate that LLMs, particularly those with high parameter counts, exhibit a moderate level of proficiency in generating correct planning domains from natural language descriptions. Our code is available at https://github.com/IBM/NL2PDDL.
5/14/2024