QuadraNet V2: Efficient and Sustainable Training of High-Order Neural Networks with Quadratic Adaptation

0

Sign in to get full access
Overview
- The paper introduces QuadraNet V2, a novel approach for efficient and sustainable training of high-order neural networks.
- It proposes a quadratic adaptation mechanism that can improve the training efficiency and performance of these complex neural network models.
- The research aims to address the challenges associated with training and deploying high-order neural networks, which are computationally expensive and difficult to optimize.
Plain English Explanation
Neural networks are a powerful type of machine learning model that can learn to perform complex tasks by processing data in multiple layers. Traditional neural networks use linear operations, but more advanced "high-order" neural networks can capture higher-level interactions and patterns in the data by using non-linear, quadratic operations.
However, training these high-order neural networks can be very computationally intensive and challenging. The QuadraNet V2 paper introduces a new technique called "quadratic adaptation" that can make the training process more efficient and sustainable.
The key idea is to dynamically adjust the quadratic components of the neural network during training, rather than keeping them fixed. This allows the model to better adapt to the data and learn more complex representations. The researchers show that QuadraNet V2 can achieve better performance on various benchmark tasks compared to standard neural network approaches, while also being more computationally efficient.
This research could help enable the widespread use of advanced high-order neural networks, which have the potential to tackle complex real-world problems that traditional models struggle with. By making these powerful models more practical to train and deploy, the QuadraNet V2 technique represents an important step forward in the field of deep learning.
Technical Explanation
The QuadraNet V2 paper proposes a novel training approach for high-order neural networks that incorporates a quadratic adaptation mechanism. High-order neural networks can capture higher-order feature interactions by using quadratic activation functions, but they are challenging to train due to the increased model complexity and computational requirements.
The key innovation of QuadraNet V2 is the introduction of a dynamic quadratic adaptation scheme that adjusts the quadratic components of the neural network during training. This allows the model to better adapt to the data and learn more complex representations compared to standard neural networks with fixed quadratic parameters.
The researchers demonstrate the effectiveness of QuadraNet V2 through extensive experiments on various benchmark tasks, including image classification, natural language processing, and reinforcement learning. They show that QuadraNet V2 can outperform traditional neural networks in terms of predictive performance while also being more computationally efficient.
The success of QuadraNet V2 is attributed to its ability to harness the power of quadratic interactions in neural networks in a more sustainable and resource-efficient manner. This research paves the way for the broader adoption of high-order neural networks, which have the potential to tackle complex real-world problems that are beyond the capabilities of standard deep learning models.
Critical Analysis
The QuadraNet V2 paper presents a promising approach for training high-order neural networks, but it also acknowledges several limitations and areas for further research.
One potential concern is the computational overhead introduced by the quadratic adaptation mechanism, which may limit the scalability of QuadraNet V2 to very large-scale models or datasets. The authors suggest that further optimizations, such as efficient implementation of the quadratic operations, could help address this issue.
Additionally, the paper primarily focuses on the training aspect of high-order neural networks and does not delve deeply into the interpretability or explainability of the learned quadratic representations. Understanding the inner workings of these complex models is an important consideration for real-world applications, and future research could explore techniques to improve the interpretability of QuadraNet V2.
Another area for further investigation is the generalization capabilities of QuadraNet V2 beyond the specific benchmark tasks presented in the paper. Assessing the model's performance on a broader range of applications, including those with significantly different data characteristics, could provide a more comprehensive evaluation of the approach's versatility and robustness.
Despite these limitations, the QuadraNet V2 paper represents a valuable contribution to the field of deep learning, as it introduces a novel and efficient training technique for high-order neural networks. By addressing the challenges associated with these complex models, the research opens up new avenues for exploring advanced machine learning architectures and their real-world applications.
Conclusion
The QuadraNet V2 paper presents a significant advancement in the training of high-order neural networks, a class of powerful machine learning models that can capture higher-level feature interactions. By introducing a quadratic adaptation mechanism, the researchers have developed a more efficient and sustainable approach to training these complex models, which can lead to improved performance on a variety of tasks.
The success of QuadraNet V2 highlights the potential of leveraging quadratic interactions in neural networks, which can unlock new capabilities for tackling complex real-world problems. While the paper identifies areas for further research, such as computational efficiency and model interpretability, the overall contribution of this work is a important step forward in advancing the field of deep learning and its practical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
QuadraNet V2: Efficient and Sustainable Training of High-Order Neural Networks with Quadratic Adaptation
Chenhui Xu, Xinyao Wang, Fuxun Yu, Jinjun Xiong, Xiang Chen
Machine learning is evolving towards high-order models that necessitate pre-training on extensive datasets, a process associated with significant overheads. Traditional models, despite having pre-trained weights, are becoming obsolete due to architectural differences that obstruct the effective transfer and initialization of these weights. To address these challenges, we introduce a novel framework, QuadraNet V2, which leverages quadratic neural networks to create efficient and sustainable high-order learning models. Our method initializes the primary term of the quadratic neuron using a standard neural network, while the quadratic term is employed to adaptively enhance the learning of data non-linearity or shifts. This integration of pre-trained primary terms with quadratic terms, which possess advanced modeling capabilities, significantly augments the information characterization capacity of the high-order network. By utilizing existing pre-trained weights, QuadraNet V2 reduces the required GPU hours for training by 90% to 98.4% compared to training from scratch, demonstrating both efficiency and effectiveness.
Read more5/10/2024
0
LoQT: Low Rank Adapters for Quantized Training
Sebastian Loeschcke, Mads Toftrup, Michael J. Kastoryano, Serge Belongie, V'esteinn Sn{ae}bjarnarson
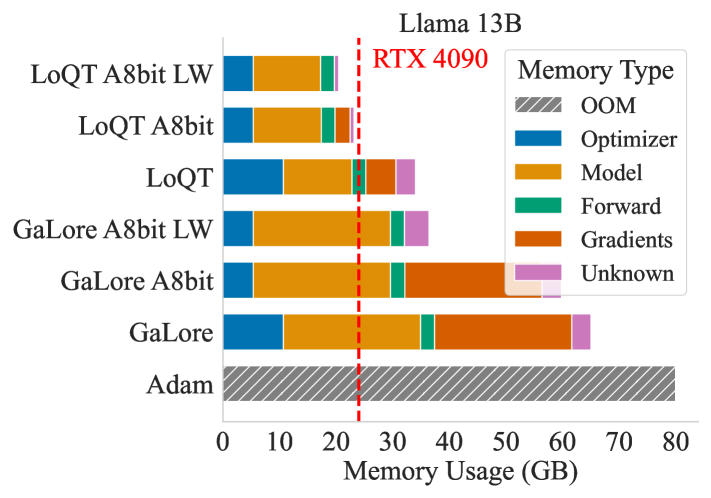
Training of large neural networks requires significant computational resources. Despite advances using low-rank adapters and quantization, pretraining of models such as LLMs on consumer hardware has not been possible without model sharding, offloading during training, or per-layer gradient updates. To address these limitations, we propose LoQT, a method for efficiently training quantized models. LoQT uses gradient-based tensor factorization to initialize low-rank trainable weight matrices that are periodically merged into quantized full-rank weight matrices. Our approach is suitable for both pretraining and fine-tuning of models, which we demonstrate experimentally for language modeling and downstream task adaptation. We find that LoQT enables efficient training of models up to 7B parameters on a consumer-grade 24GB GPU. We also demonstrate the feasibility of training a 13B parameter model using per-layer gradient updates on the same hardware.
Read more9/10/2024
0
Training-efficient density quantum machine learning
Brian Coyle, El Amine Cherrat, Nishant Jain, Natansh Mathur, Snehal Raj, Skander Kazdaghli, Iordanis Kerenidis
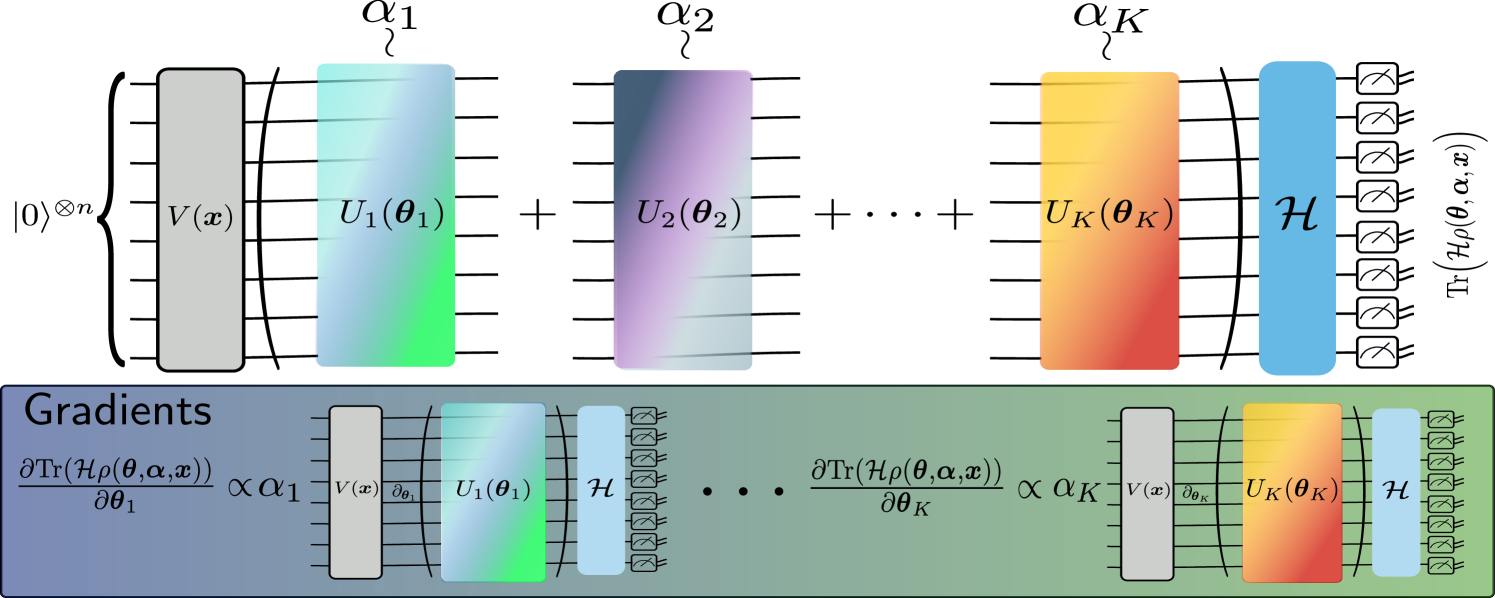
Quantum machine learning requires powerful, flexible and efficiently trainable models to be successful in solving challenging problems. In this work, we present density quantum neural networks, a learning model incorporating randomisation over a set of trainable unitaries. These models generalise quantum neural networks using parameterised quantum circuits, and allow a trade-off between expressibility and efficient trainability, particularly on quantum hardware. We demonstrate the flexibility of the formalism by applying it to two recently proposed model families. The first are commuting-block quantum neural networks (QNNs) which are efficiently trainable but may be limited in expressibility. The second are orthogonal (Hamming-weight preserving) quantum neural networks which provide well-defined and interpretable transformations on data but are challenging to train at scale on quantum devices. Density commuting QNNs improve capacity with minimal gradient complexity overhead, and density orthogonal neural networks admit a quadratic-to-constant gradient query advantage with minimal to no performance loss. We conduct numerical experiments on synthetic translationally invariant data and MNIST image data with hyperparameter optimisation to support our findings. Finally, we discuss the connection to post-variational quantum neural networks, measurement-based quantum machine learning and the dropout mechanism.
Read more5/31/2024

0
EPTQ: Enhanced Post-Training Quantization via Hessian-guided Network-wise Optimization
Ofir Gordon, Elad Cohen, Hai Victor Habi, Arnon Netzer
Quantization is a key method for deploying deep neural networks on edge devices with limited memory and computation resources. Recent improvements in Post-Training Quantization (PTQ) methods were achieved by an additional local optimization process for learning the weight quantization rounding policy. However, a gap exists when employing network-wise optimization with small representative datasets. In this paper, we propose a new method for enhanced PTQ (EPTQ) that employs a network-wise quantization optimization process, which benefits from considering cross-layer dependencies during optimization. EPTQ enables network-wise optimization with a small representative dataset using a novel sample-layer attention score based on a label-free Hessian matrix upper bound. The label-free approach makes our method suitable for the PTQ scheme. We give a theoretical analysis for the said bound and use it to construct a knowledge distillation loss that guides the optimization to focus on the more sensitive layers and samples. In addition, we leverage the Hessian upper bound to improve the weight quantization parameters selection by focusing on the more sensitive elements in the weight tensors. Empirically, by employing EPTQ we achieve state-of-the-art results on various models, tasks, and datasets, including ImageNet classification, COCO object detection, and Pascal-VOC for semantic segmentation.
Read more9/27/2024