Quality-Aware Translation Models: Efficient Generation and Quality Estimation in a Single Model

0
🛸
Sign in to get full access
Overview
- Neural machine translation (NMT) models typically use Maximum-a-posteriori (MAP) decoding, which assumes the model's probability score correlates with human judgment of translation quality
- Research has shown this assumption doesn't always hold, and decoding strategies like Minimum Bayes Risk (MBR) or quality-aware decoding can improve generation quality
- These approaches require an additional model to calculate a utility function during decoding, which is computationally expensive
- This paper proposes making NMT models themselves "quality-aware" by training them to estimate the quality of their own output
Plain English Explanation
Neural machine translation (NMT) models are used to translate text from one language to another. The most common way to decode these models, called Maximum-a-posteriori (MAP) decoding, assumes that the model's probability scores reflect how good the translation is according to humans.
However, research has shown this assumption is not always true. Minimum Bayes Risk (MBR) decoding and quality-aware decoding can sometimes produce better translations by optimizing for a specific metric or quality signal.
The downside of these approaches is they require an extra model to calculate the translation quality, which makes the process much slower.
In this paper, the researchers propose a new way to make NMT models "quality-aware" during training. This allows them to estimate the quality of their own output, which can then be used for faster decoding strategies like MBR or improving MAP decoding. This can provide quality gains similar to complex reranking approaches, but with the efficiency of a single pass through the model.
Technical Explanation
The paper proposes training NMT models to directly estimate the quality of their own output during training. This "quality-aware" capability is then leveraged during decoding to improve translation quality.
Specifically, the researchers add a quality estimation module to the NMT model's architecture. This module predicts a quality score for each target token the model generates. The quality scores are then used to guide the decoding process, either through Minimum Bayes Risk (MBR) decoding or by directly modifying the Maximum-a-posteriori (MAP) decoding objective.
For MBR decoding, the quality scores allow the model to dramatically reduce the size of the candidate list, resulting in a 100x speedup compared to standard MBR approaches. For MAP decoding, the quality-aware objective leads to quality improvements on par with complex reranking methods, but with the efficiency of a single pass through the model.
The researchers evaluate their approach on several language pairs and find consistent improvements in translation quality, as measured by standard metrics like BLEU and human evaluation.
Critical Analysis
The key innovation of this work is training NMT models to be "quality-aware" by having them directly estimate the quality of their own output. This represents a significant departure from the standard MAP decoding approach, which assumes the model's probability scores correlate with human judgments of quality.
One potential limitation is that the quality estimation module adds additional complexity to the model and may require more training data to learn effectively. The authors note that further research is needed to fully understand the tradeoffs between model complexity, training data requirements, and decoding efficiency.
Additionally, the paper only evaluates the approach on standard machine translation benchmarks. It would be interesting to see how it performs on more open-ended or domain-specific translation tasks, where the mismatch between model probability and human quality judgments may be more pronounced.
Overall, this work presents a promising direction for improving the generation quality of NMT models by incorporating quality awareness directly into the model architecture and training process. Further research exploring the broader applicability and potential limitations of this approach would be valuable for advancing the state of the art in neural machine translation.
Conclusion
This paper proposes a novel approach to make neural machine translation (NMT) models "quality-aware" by training them to directly estimate the quality of their own output. This quality awareness can then be leveraged to improve decoding strategies like Minimum Bayes Risk (MBR) or Maximum-a-posteriori (MAP) decoding.
The key benefits of this approach are increased decoding efficiency for MBR, and quality improvements for MAP decoding that are on par with complex reranking methods, but with the speed of a single pass through the model. This represents a significant advancement over standard decoding techniques that rely on the assumption of a correlation between model probability and human quality judgments.
While further research is needed to fully understand the tradeoffs and broader applicability of this quality-aware NMT approach, this work presents a promising direction for improving the generation quality and overall performance of neural machine translation systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
0
Quality-Aware Translation Models: Efficient Generation and Quality Estimation in a Single Model
Christian Tomani, David Vilar, Markus Freitag, Colin Cherry, Subhajit Naskar, Mara Finkelstein, Xavier Garcia, Daniel Cremers
Maximum-a-posteriori (MAP) decoding is the most widely used decoding strategy for neural machine translation (NMT) models. The underlying assumption is that model probability correlates well with human judgment, with better translations getting assigned a higher score by the model. However, research has shown that this assumption does not always hold, and generation quality can be improved by decoding to optimize a utility function backed by a metric or quality-estimation signal, as is done by Minimum Bayes Risk (MBR) or quality-aware decoding. The main disadvantage of these approaches is that they require an additional model to calculate the utility function during decoding, significantly increasing the computational cost. In this paper, we propose to make the NMT models themselves quality-aware by training them to estimate the quality of their own output. Using this approach for MBR decoding we can drastically reduce the size of the candidate list, resulting in a speed-up of two-orders of magnitude. When applying our method to MAP decoding we obtain quality gains similar or even superior to quality reranking approaches, but with the efficiency of single pass decoding.
Read more7/12/2024

0
Unveiling the Power of Source: Source-based Minimum Bayes Risk Decoding for Neural Machine Translation
Boxuan Lyu, Hidetaka Kamigaito, Kotaro Funakoshi, Manabu Okumura
Maximum a posteriori decoding, a commonly used method for neural machine translation (NMT), aims to maximize the estimated posterior probability. However, high estimated probability does not always lead to high translation quality. Minimum Bayes Risk (MBR) decoding offers an alternative by seeking hypotheses with the highest expected utility. In this work, we show that Quality Estimation (QE) reranking, which uses a QE model as a reranker, can be viewed as a variant of MBR. Inspired by this, we propose source-based MBR (sMBR) decoding, a novel approach that utilizes synthetic sources generated by backward translation as ``support hypotheses'' and a reference-free quality estimation metric as the utility function, marking the first work to solely use sources in MBR decoding. Experiments show that sMBR significantly outperforms QE reranking and is competitive with standard MBR decoding. Furthermore, sMBR calls the utility function fewer times compared to MBR. Our findings suggest that sMBR is a promising approach for high-quality NMT decoding.
Read more6/18/2024
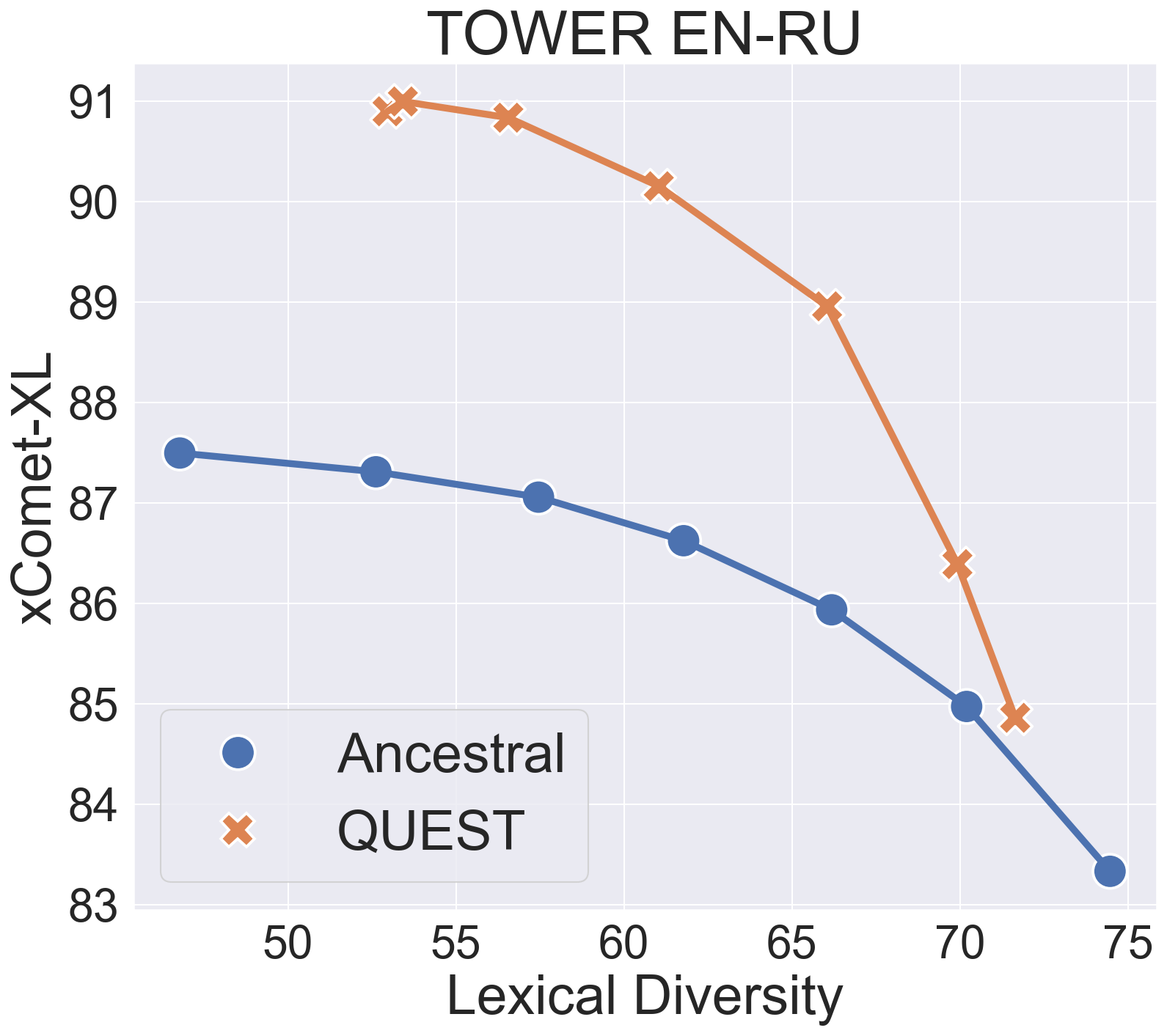
0
QUEST: Quality-Aware Metropolis-Hastings Sampling for Machine Translation
Gonc{c}alo R. A. Faria, Sweta Agrawal, Ant'onio Farinhas, Ricardo Rei, Jos'e G. C. de Souza, Andr'e F. T. Martins
An important challenge in machine translation (MT) is to generate high-quality and diverse translations. Prior work has shown that the estimated likelihood from the MT model correlates poorly with translation quality. In contrast, quality evaluation metrics (such as COMET or BLEURT) exhibit high correlations with human judgments, which has motivated their use as rerankers (such as quality-aware and minimum Bayes risk decoding). However, relying on a single translation with high estimated quality increases the chances of gaming the metric''. In this paper, we address the problem of sampling a set of high-quality and diverse translations. We provide a simple and effective way to avoid over-reliance on noisy quality estimates by using them as the energy function of a Gibbs distribution. Instead of looking for a mode in the distribution, we generate multiple samples from high-density areas through the Metropolis-Hastings algorithm, a simple Markov chain Monte Carlo approach. The results show that our proposed method leads to high-quality and diverse outputs across multiple language pairs (English$leftrightarrow${German, Russian}) with two strong decoder-only LLMs (Alma-7b, Tower-7b).
Read more6/4/2024
🛠️
0
Direct Preference Optimization for Neural Machine Translation with Minimum Bayes Risk Decoding
Guangyu Yang, Jinghong Chen, Weizhe Lin, Bill Byrne
Minimum Bayes Risk (MBR) decoding can significantly improve translation performance of Multilingual Large Language Models (MLLMs). However, MBR decoding is computationally expensive. We show how the recently developed Reinforcement Learning technique, Direct Preference Optimization (DPO), can fine-tune MLLMs to get the gains of MBR without any additional computation in inference. Our method uses only a small monolingual fine-tuning set and yields significantly improved performance on multiple NMT test sets compared to MLLMs without DPO.
Read more4/15/2024