QUEST: Quality-Aware Metropolis-Hastings Sampling for Machine Translation

0
Sign in to get full access
Overview
- This paper introduces a new sampling method called QUEST (Quality-Aware Metropolis-Hastings Sampling) for improving machine translation quality.
- QUEST aims to generate higher-quality translations by incorporating a quality-aware objective function into the Metropolis-Hastings sampling process.
- The authors demonstrate that QUEST outperforms standard sampling approaches in terms of translation quality on several benchmark datasets.
Plain English Explanation
The paper presents a new technique called QUEST (Quality-Aware Metropolis-Hastings Sampling) that can be used to improve the quality of machine translations. Machine translation is the process of automatically translating text from one language to another, and it's a task that is challenging for computers to perform well.
The key idea behind QUEST is to modify the way the computer selects candidate translations during the translation process. Normally, the computer would simply try to find the most probable translation based on the language model it has been trained on. QUEST, on the other hand, also considers the
The authors achieve this by incorporating a "quality-aware" objective function into the Metropolis-Hastings sampling algorithm, which is a common technique used in machine translation. This means that QUEST not only tries to find probable translations, but also translations that are high in quality according to certain criteria.
The authors show that this approach leads to better translation quality on several standard benchmark datasets, compared to traditional sampling methods. This is an important result, as improving the quality of machine translations has significant real-world applications, such as Chasing Comet: Leveraging Minimum Bayes Risk Decoding or GentransLate: Large Language Models Are Generative, Multilingual.
Technical Explanation
The paper introduces a new sampling method called QUEST (Quality-Aware Metropolis-Hastings Sampling) for machine translation. The key innovation is the incorporation of a quality-aware objective function into the Metropolis-Hastings sampling process.
Typically, machine translation systems use a language model to generate candidate translations and then select the most probable one. QUEST, on the other hand, also considers the
To do this, the authors define a quality-aware objective function that evaluates the fluency, adequacy, and other attributes of the candidate translations. This quality-aware objective is then used within the Metropolis-Hastings sampling algorithm to guide the search towards higher-quality translations.
The authors evaluate QUEST on several benchmark datasets for machine translation and show that it outperforms standard sampling approaches in terms of translation quality. This includes datasets used in other related work such as Guiding Large Language Models to Post-Edit and Contrastive Preference Optimization: Pushing the Boundaries of LLM Performance.
Critical Analysis
The paper presents a novel and promising approach to improving machine translation quality through quality-aware sampling. The key strength of the QUEST method is its ability to go beyond simply finding the most probable translations and instead optimize for translations that are high in quality according to various metrics.
However, the paper does not provide a detailed analysis of the computational complexity or runtime performance of the QUEST method compared to standard sampling approaches. This is an important consideration, as the additional quality-aware objective function may come at the cost of increased computational overhead.
Additionally, the paper does not explore the robustness of the QUEST method to different types of input data or language pairs. It would be valuable to see how the method performs on a wider range of scenarios, including low-resource language pairs or noisy input text, as this would provide a more comprehensive understanding of its strengths and limitations.
Finally, the paper could benefit from a more thorough discussion of the potential real-world applications and implications of the QUEST method, beyond the standard machine translation benchmarks. For example, how might this approach be leveraged in practical translation use cases, such as Iterative Translation Refinement with Large Language Models?
Conclusion
The QUEST method presented in this paper represents a promising step forward in improving the quality of machine translations. By incorporating a quality-aware objective function into the Metropolis-Hastings sampling process, the authors demonstrate that it is possible to generate translations that are not only probabilistically likely, but also of higher overall quality.
The results on benchmark datasets are encouraging and suggest that this approach could have meaningful real-world applications. However, further research is needed to fully understand the computational and performance trade-offs, as well as the robustness of the method to different types of input and language pairs.
Overall, this paper makes a valuable contribution to the field of machine translation and opens up new avenues for exploring quality-aware sampling techniques to improve the capabilities of language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
QUEST: Quality-Aware Metropolis-Hastings Sampling for Machine Translation
Gonc{c}alo R. A. Faria, Sweta Agrawal, Ant'onio Farinhas, Ricardo Rei, Jos'e G. C. de Souza, Andr'e F. T. Martins
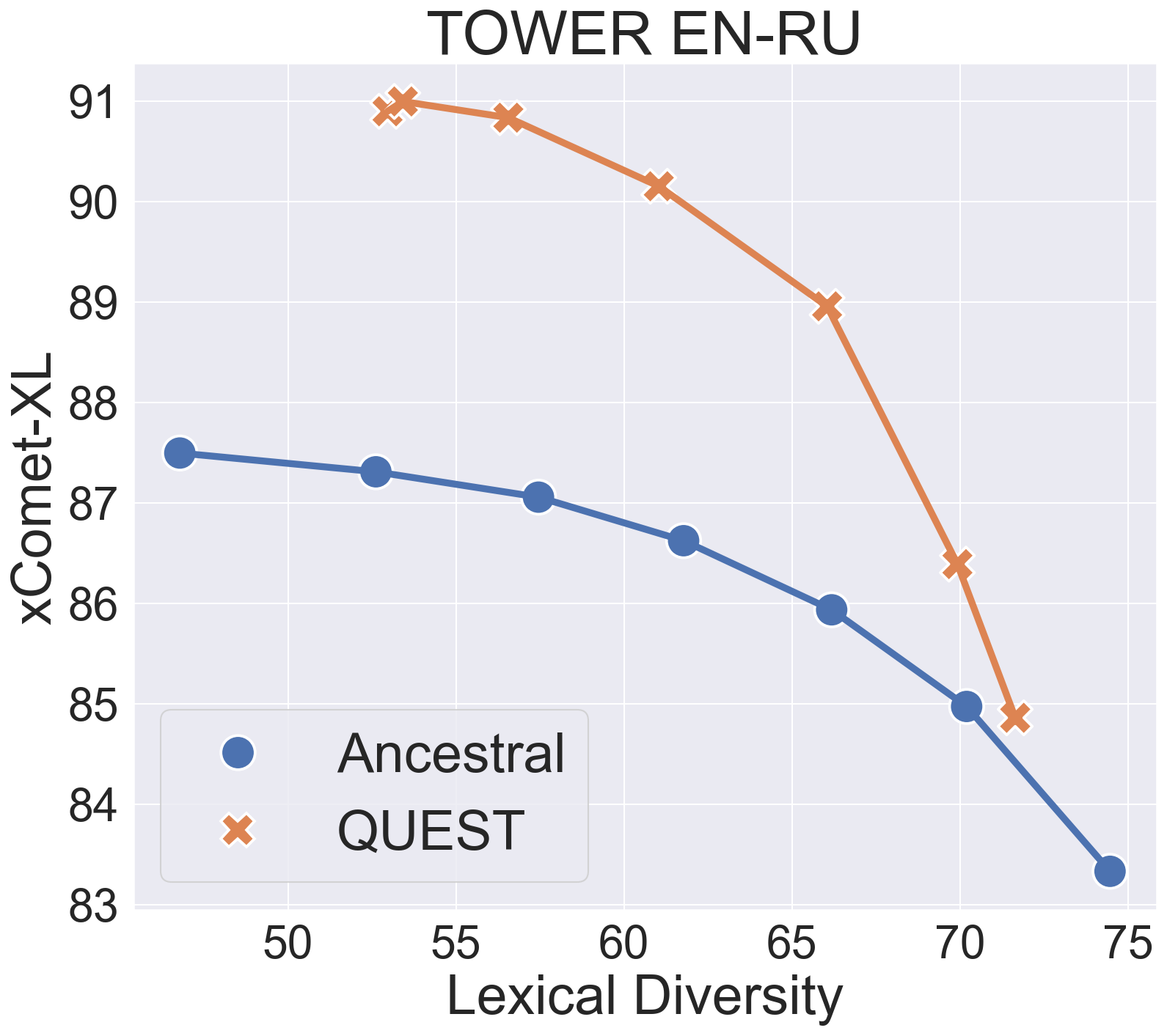
An important challenge in machine translation (MT) is to generate high-quality and diverse translations. Prior work has shown that the estimated likelihood from the MT model correlates poorly with translation quality. In contrast, quality evaluation metrics (such as COMET or BLEURT) exhibit high correlations with human judgments, which has motivated their use as rerankers (such as quality-aware and minimum Bayes risk decoding). However, relying on a single translation with high estimated quality increases the chances of gaming the metric''. In this paper, we address the problem of sampling a set of high-quality and diverse translations. We provide a simple and effective way to avoid over-reliance on noisy quality estimates by using them as the energy function of a Gibbs distribution. Instead of looking for a mode in the distribution, we generate multiple samples from high-density areas through the Metropolis-Hastings algorithm, a simple Markov chain Monte Carlo approach. The results show that our proposed method leads to high-quality and diverse outputs across multiple language pairs (English$leftrightarrow${German, Russian}) with two strong decoder-only LLMs (Alma-7b, Tower-7b).
Read more6/4/2024

0
Don't Rank, Combine! Combining Machine Translation Hypotheses Using Quality Estimation
Giorgos Vernikos, Andrei Popescu-Belis
Neural machine translation systems estimate probabilities of target sentences given source sentences, yet these estimates may not align with human preferences. This work introduces QE-fusion, a method that synthesizes translations using a quality estimation metric (QE), which correlates better with human judgments. QE-fusion leverages a pool of candidates sampled from a model, combining spans from different candidates using a QE metric such as CometKiwi. We compare QE-fusion against beam search and recent reranking techniques, such as Minimum Bayes Risk decoding or QE-reranking. Our method consistently improves translation quality in terms of COMET and BLEURT scores when applied to large language models (LLMs) used for translation (PolyLM, XGLM, Llama2, Mistral, ALMA, and Tower) and to multilingual translation models (NLLB), over five language pairs. Notably, QE-fusion exhibits larger improvements for LLMs due to their ability to generate diverse outputs. We demonstrate that our approach generates novel translations in over half of the cases and consistently outperforms other methods across varying numbers of candidates (5-200). Furthermore, we empirically establish that QE-fusion scales linearly with the number of candidates in the pool.
Read more6/7/2024
🛸
0
Quality-Aware Translation Models: Efficient Generation and Quality Estimation in a Single Model
Christian Tomani, David Vilar, Markus Freitag, Colin Cherry, Subhajit Naskar, Mara Finkelstein, Xavier Garcia, Daniel Cremers
Maximum-a-posteriori (MAP) decoding is the most widely used decoding strategy for neural machine translation (NMT) models. The underlying assumption is that model probability correlates well with human judgment, with better translations getting assigned a higher score by the model. However, research has shown that this assumption does not always hold, and generation quality can be improved by decoding to optimize a utility function backed by a metric or quality-estimation signal, as is done by Minimum Bayes Risk (MBR) or quality-aware decoding. The main disadvantage of these approaches is that they require an additional model to calculate the utility function during decoding, significantly increasing the computational cost. In this paper, we propose to make the NMT models themselves quality-aware by training them to estimate the quality of their own output. Using this approach for MBR decoding we can drastically reduce the size of the candidate list, resulting in a speed-up of two-orders of magnitude. When applying our method to MAP decoding we obtain quality gains similar or even superior to quality reranking approaches, but with the efficiency of single pass decoding.
Read more7/12/2024

0
Chasing COMET: Leveraging Minimum Bayes Risk Decoding for Self-Improving Machine Translation
Kamil Guttmann, Miko{l}aj Pokrywka, Adrian Charkiewicz, Artur Nowakowski
This paper explores Minimum Bayes Risk (MBR) decoding for self-improvement in machine translation (MT), particularly for domain adaptation and low-resource languages. We implement the self-improvement process by fine-tuning the model on its MBR-decoded forward translations. By employing COMET as the MBR utility metric, we aim to achieve the reranking of translations that better aligns with human preferences. The paper explores the iterative application of this approach and the potential need for language-specific MBR utility metrics. The results demonstrate significant enhancements in translation quality for all examined language pairs, including successful application to domain-adapted models and generalisation to low-resource settings. This highlights the potential of COMET-guided MBR for efficient MT self-improvement in various scenarios.
Read more5/21/2024