A Shocking Amount of the Web is Machine Translated: Insights from Multi-Way Parallelism

66
Sign in to get full access
Overview
- This paper investigates the prevalence of machine-translated content on the web and provides insights into the multi-way parallelism (the alignment of text across multiple languages) of such content.
- The researchers create a large-scale corpus called MWccMatrix, which contains millions of web pages in over 100 languages, and use it to analyze the extent of machine translation on the web.
- The findings suggest that a significant portion of the web's content is machine-translated, with important implications for machine translation research, web content quality, and the understanding of multilingual language models.
Plain English Explanation
This paper looks at how much of the content on the internet is automatically translated by machines, rather than being written by humans. The researchers created a huge dataset called MWccMatrix, which contains millions of web pages in over 100 different languages. They used this dataset to study the extent of machine translation on the web.
The key finding is that a surprisingly large amount of the content on the internet is machine-translated, rather than being originally written in that language. This has important implications for how we think about machine translation and the quality of content on the web. It also affects our understanding of multilingual language models, which may be learning from a lot of machine-translated text.
Overall, this research provides valuable insights into the scale and nature of machine translation on the internet, which could help shape the future of multilingual AI.
Technical Explanation
The researchers create a large-scale corpus called MWccMatrix, which contains over 80 million web pages in more than 100 languages. They use advanced techniques to align the content across these pages, identifying which ones are machine-translated versions of the same underlying text.
Their analysis reveals that a significant percentage of the web's content, estimated at around 30-50%, is actually machine-translated. This includes not just user-generated content, but also professional and commercial web pages. The researchers also find evidence that machine translation is used extensively for indexing and crawling web content in multiple languages.
The implications of these findings are far-reaching. They suggest that the training data used for machine translation and multilingual language models may be heavily skewed towards machine-translated text, potentially limiting their performance. The prevalence of machine-translated content also raises questions about web content quality and the ability of users to critically evaluate information sources.
Critical Analysis
The researchers acknowledge several limitations to their study. The MWccMatrix corpus, while very large, may not be fully representative of the entire web. There could be biases in the web pages that are crawled and included in the dataset.
Additionally, the researchers' techniques for identifying machine-translated content, while sophisticated, may not be perfect. It's possible that some human-written content is mistakenly classified as machine-translated, or vice versa.
Further research is needed to better understand the nuances of machine translation on the web, such as how it varies across different domains, languages, and types of content. Longitudinal studies could also shed light on how the prevalence of machine translation has changed over time.
Despite these caveats, this study provides a valuable and sobering look at the current state of web content creation. It highlights the need for greater awareness and critical thinking around the origins and trustworthiness of online information, as well as the potential pitfalls in relying on machine-translated data for training AI systems.
Conclusion
This paper reveals that a surprisingly large amount of the web's content is machine-translated, rather than being originally written in that language. This has important implications for machine translation research, the quality and reliability of web content, and our understanding of multilingual language models.
The researchers' insights could help shape the future of multilingual AI by highlighting the need to better account for the prevalence of machine-translated text in training data and web content. This study serves as an important wake-up call for both researchers and internet users to be more critical and discerning about the origins and quality of online information.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
66
A Shocking Amount of the Web is Machine Translated: Insights from Multi-Way Parallelism
Brian Thompson, Mehak Preet Dhaliwal, Peter Frisch, Tobias Domhan, Marcello Federico
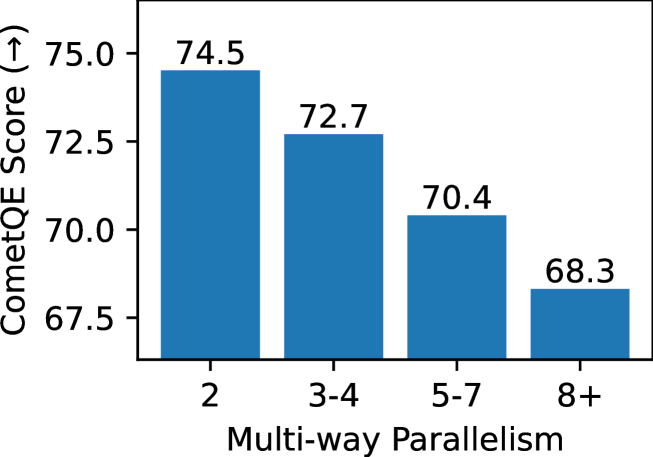
We show that content on the web is often translated into many languages, and the low quality of these multi-way translations indicates they were likely created using Machine Translation (MT). Multi-way parallel, machine generated content not only dominates the translations in lower resource languages; it also constitutes a large fraction of the total web content in those languages. We also find evidence of a selection bias in the type of content which is translated into many languages, consistent with low quality English content being translated en masse into many lower resource languages, via MT. Our work raises serious concerns about training models such as multilingual large language models on both monolingual and bilingual data scraped from the web.
Read more6/7/2024

0
On the Evaluation Practices in Multilingual NLP: Can Machine Translation Offer an Alternative to Human Translations?
Rochelle Choenni, Sara Rajaee, Christof Monz, Ekaterina Shutova
While multilingual language models (MLMs) have been trained on 100+ languages, they are typically only evaluated across a handful of them due to a lack of available test data in most languages. This is particularly problematic when assessing MLM's potential for low-resource and unseen languages. In this paper, we present an analysis of existing evaluation frameworks in multilingual NLP, discuss their limitations, and propose several directions for more robust and reliable evaluation practices. Furthermore, we empirically study to what extent machine translation offers a {reliable alternative to human translation} for large-scale evaluation of MLMs across a wide set of languages. We use a SOTA translation model to translate test data from 4 tasks to 198 languages and use them to evaluate three MLMs. We show that while the selected subsets of high-resource test languages are generally sufficiently representative of a wider range of high-resource languages, we tend to overestimate MLMs' ability on low-resource languages. Finally, we show that simpler baselines can achieve relatively strong performance without having benefited from large-scale multilingual pretraining.
Read more6/21/2024
0
How Multilingual Are Large Language Models Fine-Tuned for Translation?
Aquia Richburg, Marine Carpuat
A new paradigm for machine translation has recently emerged: fine-tuning large language models (LLM) on parallel text has been shown to outperform dedicated translation systems trained in a supervised fashion on much larger amounts of parallel data (Xu et al., 2024a; Alves et al., 2024). However, it remains unclear whether this paradigm can enable massively multilingual machine translation or whether it requires fine-tuning dedicated models for a small number of language pairs. How does translation fine-tuning impact the MT capabilities of LLMs for zero-shot languages, zero-shot language pairs, and translation tasks that do not involve English? To address these questions, we conduct an extensive empirical evaluation of the translation quality of the TOWER family of language models (Alves et al., 2024) on 132 translation tasks from the multi-parallel FLORES-200 data. We find that translation fine-tuning improves translation quality even for zero-shot languages on average, but that the impact is uneven depending on the language pairs involved. These results call for further research to effectively enable massively multilingual translation with LLMs.
Read more6/3/2024
🔄
0
To Translate or Not to Translate: A Systematic Investigation of Translation-Based Cross-Lingual Transfer to Low-Resource Languages
Benedikt Ebing, Goran Glavav{s}
Perfect machine translation (MT) would render cross-lingual transfer (XLT) by means of multilingual language models (mLMs) superfluous. Given, on the one hand, the large body of work on improving XLT with mLMs and, on the other hand, recent advances in massively multilingual MT, in this work, we systematically evaluate existing and propose new translation-based XLT approaches for transfer to low-resource languages. We show that all translation-based approaches dramatically outperform zero-shot XLT with mLMs -- with the combination of round-trip translation of the source-language training data and the translation of the target-language test instances at inference -- being generally the most effective. We next show that one can obtain further empirical gains by adding reliable translations to other high-resource languages to the training data. Moreover, we propose an effective translation-based XLT strategy even for languages not supported by the MT system. Finally, we show that model selection for XLT based on target-language validation data obtained with MT outperforms model selection based on the source-language data. We believe our findings warrant a broader inclusion of more robust translation-based baselines in XLT research.
Read more7/11/2024