Quality Estimation with $k$-nearest Neighbors and Automatic Evaluation for Model-specific Quality Estimation

0
📈
Sign in to get full access
Overview
- Proposed a new unsupervised quality estimation (QE) approach called $k$NN-QE that extracts information from machine translation (MT) model training data using $k$-nearest neighbors
- Developed an automatic evaluation method for model-specific QE approaches that uses quality scores from reference-based metrics as a gold standard
- Found that the reference-based MetricX-23 is best for evaluating model-specific QE systems
Plain English Explanation
When using machine translation (MT) systems, it's important to know how reliable the translations are. The paper proposes a new approach called $k$NN-QE to estimate the quality of MT output without needing human-provided reference translations. This $k$NN-QE method looks at the MT model's training data to get clues about the translation quality.
Evaluating these model-specific QE approaches is tricky, since they provide quality scores on their own MT output, not on a standard test set. [The researchers developed a new automatic evaluation method that uses quality scores from reference-based metrics, like MetricX-23, instead of human evaluations.](https://aimodels.fyi/papers/arxiv/evaluating-generative-language-models-information-extraction-as) This allows them to more easily test and compare different QE approaches.
Overall, the paper shows a new way to estimate translation quality without human references, and a new method to automatically evaluate these quality estimation systems.
Technical Explanation
The paper proposes a model-specific, unsupervised Quality Estimation (QE) approach called $k$NN-QE. This method extracts information from the MT model's training data using $k$-nearest neighbors to predict the quality of the model's own translations.
Evaluating the performance of model-specific QE approaches is challenging, as they provide quality scores on their own MT output, rather than on a standard benchmark QE test set with human-assigned quality scores. To address this, the researchers developed an automatic evaluation method that uses quality scores from reference-based metrics (like MetricX-23) as a "gold standard" instead of human evaluations.
Through their experiments, the authors conclude that this automatic evaluation method is sufficient, and that the MetricX-23 reference-based metric is the best choice for evaluating model-specific QE systems.
Critical Analysis
The paper presents a novel approach to QE and a new method for evaluating model-specific QE systems. However, the authors acknowledge that their automatic evaluation approach has limitations, as the reference-based metrics may not fully capture human judgments of translation quality.
Additionally, the $k$NN-QE method relies on the availability of high-quality training data for the MT model, which may not always be the case in real-world scenarios. Further research is needed to explore the performance of this approach with different types of MT models and training data.
The authors also note that their analyses focus on a specific language pair and MT model, so the generalizability of their findings to other settings remains to be seen. [Conducting replicable human evaluations across a wider range of scenarios could help validate and expand the insights from this research.](https://aimodels.fyi/papers/arxiv/quality-quantity-machine-translation-references-automatic-metrics)
Conclusion
This paper presents a novel unsupervised approach for Quality Estimation (QE) of machine translations, called $k$NN-QE, that leverages information from the MT model's training data. The researchers also developed an automatic evaluation method for model-specific QE approaches that uses reference-based metrics as a gold standard.
The authors' findings suggest that this automatic evaluation method is sufficient, and that the MetricX-23 reference-based metric is the best choice for evaluating model-specific QE systems. This work contributes to the ongoing efforts to improve the reliability and transparency of machine translation systems, which is crucial for their widespread adoption and real-world impact.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
Quality Estimation with $k$-nearest Neighbors and Automatic Evaluation for Model-specific Quality Estimation
Tu Anh Dinh, Tobias Palzer, Jan Niehues
Providing quality scores along with Machine Translation (MT) output, so-called reference-free Quality Estimation (QE), is crucial to inform users about the reliability of the translation. We propose a model-specific, unsupervised QE approach, termed $k$NN-QE, that extracts information from the MT model's training data using $k$-nearest neighbors. Measuring the performance of model-specific QE is not straightforward, since they provide quality scores on their own MT output, thus cannot be evaluated using benchmark QE test sets containing human quality scores on premade MT output. Therefore, we propose an automatic evaluation method that uses quality scores from reference-based metrics as gold standard instead of human-generated ones. We are the first to conduct detailed analyses and conclude that this automatic method is sufficient, and the reference-based MetricX-23 is best for the task.
Read more4/30/2024

0
Don't Rank, Combine! Combining Machine Translation Hypotheses Using Quality Estimation
Giorgos Vernikos, Andrei Popescu-Belis
Neural machine translation systems estimate probabilities of target sentences given source sentences, yet these estimates may not align with human preferences. This work introduces QE-fusion, a method that synthesizes translations using a quality estimation metric (QE), which correlates better with human judgments. QE-fusion leverages a pool of candidates sampled from a model, combining spans from different candidates using a QE metric such as CometKiwi. We compare QE-fusion against beam search and recent reranking techniques, such as Minimum Bayes Risk decoding or QE-reranking. Our method consistently improves translation quality in terms of COMET and BLEURT scores when applied to large language models (LLMs) used for translation (PolyLM, XGLM, Llama2, Mistral, ALMA, and Tower) and to multilingual translation models (NLLB), over five language pairs. Notably, QE-fusion exhibits larger improvements for LLMs due to their ability to generate diverse outputs. We demonstrate that our approach generates novel translations in over half of the cases and consistently outperforms other methods across varying numbers of candidates (5-200). Furthermore, we empirically establish that QE-fusion scales linearly with the number of candidates in the pool.
Read more6/7/2024

0
Can Automatic Metrics Assess High-Quality Translations?
Sweta Agrawal, Ant'onio Farinhas, Ricardo Rei, Andr'e F. T. Martins
Automatic metrics for evaluating translation quality are typically validated by measuring how well they correlate with human assessments. However, correlation methods tend to capture only the ability of metrics to differentiate between good and bad source-translation pairs, overlooking their reliability in distinguishing alternative translations for the same source. In this paper, we confirm that this is indeed the case by showing that current metrics are insensitive to nuanced differences in translation quality. This effect is most pronounced when the quality is high and the variance among alternatives is low. Given this finding, we shift towards detecting high-quality correct translations, an important problem in practical decision-making scenarios where a binary check of correctness is prioritized over a nuanced evaluation of quality. Using the MQM framework as the gold standard, we systematically stress-test the ability of current metrics to identify translations with no errors as marked by humans. Our findings reveal that current metrics often over or underestimate translation quality, indicating significant room for improvement in automatic evaluation methods.
Read more5/29/2024
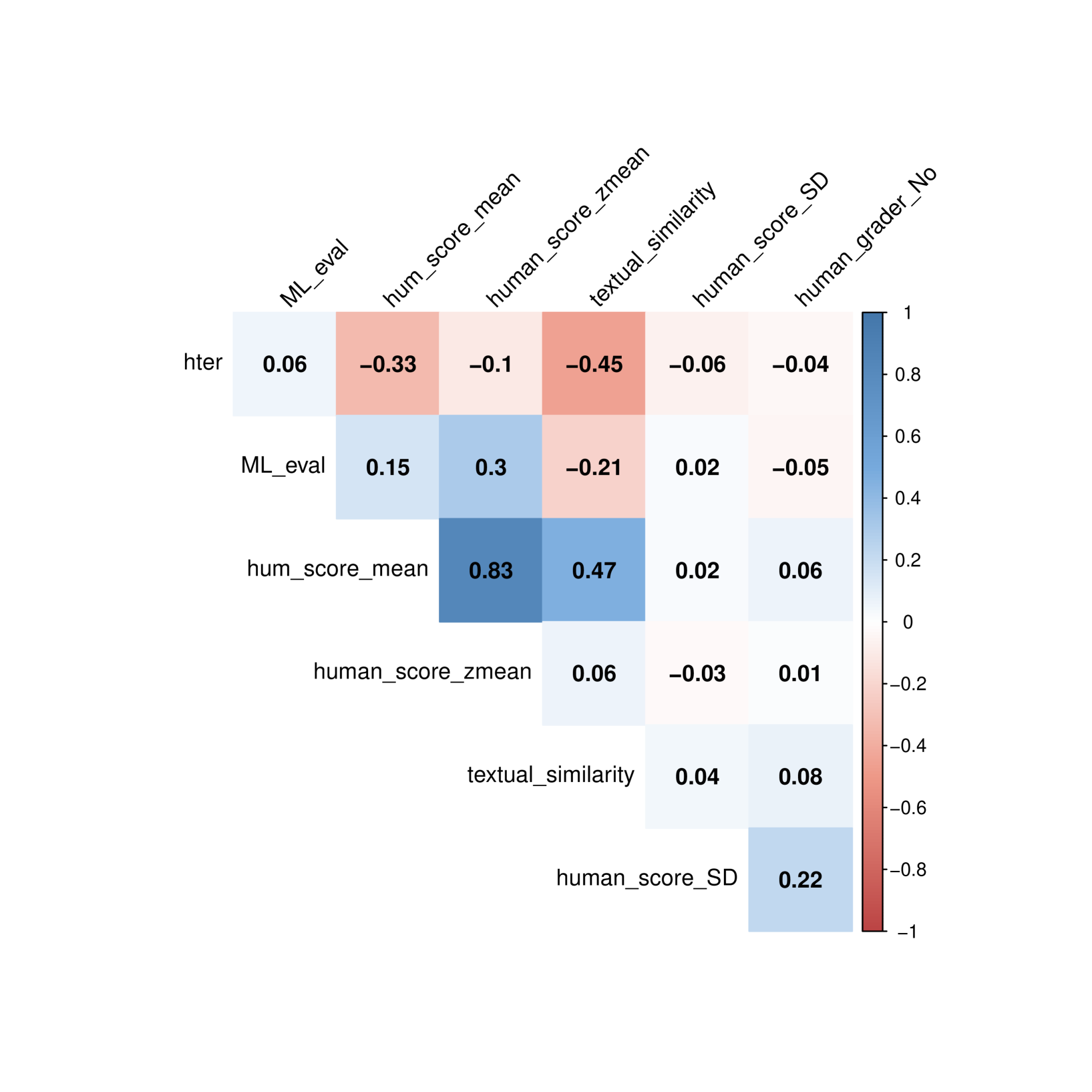
0
Textual Similarity as a Key Metric in Machine Translation Quality Estimation
Kun Sun, Rong Wang
Machine Translation (MT) Quality Estimation (QE) assesses translation reliability without reference texts. This study introduces textual similarity as a new metric for QE, using sentence transformers and cosine similarity to measure semantic closeness. Analyzing data from the MLQE-PE dataset, we found that textual similarity exhibits stronger correlations with human scores than traditional metrics (hter, model evaluation, sentence probability etc.). Employing GAMMs as a statistical tool, we demonstrated that textual similarity consistently outperforms other metrics across multiple language pairs in predicting human scores. We also found that hter actually failed to predict human scores in QE. Our findings highlight the effectiveness of textual similarity as a robust QE metric, recommending its integration with other metrics into QE frameworks and MT system training for improved accuracy and usability.
Read more7/2/2024