Quality Matters: Evaluating Synthetic Data for Tool-Using LLMs

0

Sign in to get full access
Overview
- The paper evaluates the use of synthetic data for training large language models (LLMs) that can perform tool-using tasks.
- It examines the quality and efficacy of synthetic data compared to real-world data for benchmarking LLM performance.
- The researchers conducted experiments to assess how well LLMs trained on synthetic data can perform on real-world tool-using tasks.
Plain English Explanation
The paper looks at using artificial or computer-generated data to train large language models (LLMs) that can complete tasks involving tools. The researchers wanted to see how well these LLMs trained on synthetic data performed on real-world tool-using challenges, compared to LLMs trained on actual data.
The key idea is that synthetic data could be a useful alternative to real-world data for benchmarking and training LLMs in certain situations. However, the quality of the synthetic data is crucial - if it doesn't accurately reflect real-world conditions, the LLMs may not perform well on real tasks.
The paper presents experiments that evaluate the ability of LLMs trained on synthetic data to handle real-world tool-using challenges. This provides insights into the effectiveness and limitations of using synthetic data to develop capable, robust LLM systems.
Technical Explanation
The researchers conducted a series of experiments to assess the performance of LLMs trained on synthetic data versus real-world data for tool-using tasks. They generated high-quality synthetic data depicting tool interactions and used it to train LLM models.
These synthetic-data-trained LLMs were then evaluated on a benchmark of real-world tool-using challenges. The paper analyzes the LLMs' performance on these tasks, comparing it to the results of LLMs trained on actual data.
The findings suggest that while synthetic data can be a useful supplement, the quality and fidelity of the synthetic data is crucial. LLMs trained solely on synthetic data struggled to match the performance of those trained on real-world data, especially for more complex or nuanced tool-using tasks.
Critical Analysis
The paper acknowledges some limitations of the synthetic data approach. The researchers note that the synthetic data, while high-quality, may not fully capture the richness and diversity of real-world tool interactions. There may be subtle aspects of tool usage that are difficult to simulate accurately in a synthetic environment.
Additionally, the paper suggests that a hybrid approach leveraging both synthetic and real-world data may be optimal for training capable, robust LLMs for tool-using tasks. Further research is needed to explore techniques for effectively combining these data sources.
Overall, the study provides important insights into the potential and pitfalls of using synthetic data for training LLMs. It highlights the need to carefully evaluate the quality and representational fidelity of synthetic data to ensure LLMs can generalize effectively to real-world scenarios.
Conclusion
This paper examines the use of synthetic data for training LLMs that can perform tool-using tasks. The key finding is that while synthetic data can be a valuable supplement, the quality and realism of the synthetic data is crucial for ensuring LLMs trained on it can handle real-world tool-using challenges.
The research suggests that a hybrid approach combining synthetic and real-world data may be the most effective way to develop capable, robust LLM systems for tool-using applications. As the use of synthetic data becomes more prevalent in AI development, this study provides important guidance on how to leverage synthetic data effectively while accounting for its limitations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Quality Matters: Evaluating Synthetic Data for Tool-Using LLMs
Shadi Iskander, Nachshon Cohen, Zohar Karnin, Ori Shapira, Sofia Tolmach
Training large language models (LLMs) for external tool usage is a rapidly expanding field, with recent research focusing on generating synthetic data to address the shortage of available data. However, the absence of systematic data quality checks poses complications for properly training and testing models. To that end, we propose two approaches for assessing the reliability of data for training LLMs to use external tools. The first approach uses intuitive, human-defined correctness criteria. The second approach uses a model-driven assessment with in-context evaluation. We conduct a thorough evaluation of data quality on two popular benchmarks, followed by an extrinsic evaluation that showcases the impact of data quality on model performance. Our results demonstrate that models trained on high-quality data outperform those trained on unvalidated data, even when trained with a smaller quantity of data. These findings empirically support the significance of assessing and ensuring the reliability of training data for tool-using LLMs.
Read more9/27/2024
📊
0
Efficacy of Synthetic Data as a Benchmark
Gaurav Maheshwari, Dmitry Ivanov, Kevin El Haddad
Large language models (LLMs) have enabled a range of applications in zero-shot and few-shot learning settings, including the generation of synthetic datasets for training and testing. However, to reliably use these synthetic datasets, it is essential to understand how representative they are of real-world data. We investigate this by assessing the effectiveness of generating synthetic data through LLM and using it as a benchmark for various NLP tasks. Our experiments across six datasets, and three different tasks, show that while synthetic data can effectively capture performance of various methods for simpler tasks, such as intent classification, it falls short for more complex tasks like named entity recognition. Additionally, we propose a new metric called the bias factor, which evaluates the biases introduced when the same LLM is used to both generate benchmarking data and to perform the tasks. We find that smaller LLMs exhibit biases towards their own generated data, whereas larger models do not. Overall, our findings suggest that the effectiveness of synthetic data as a benchmark varies depending on the task, and that practitioners should rely on data generated from multiple larger models whenever possible.
Read more9/19/2024
0
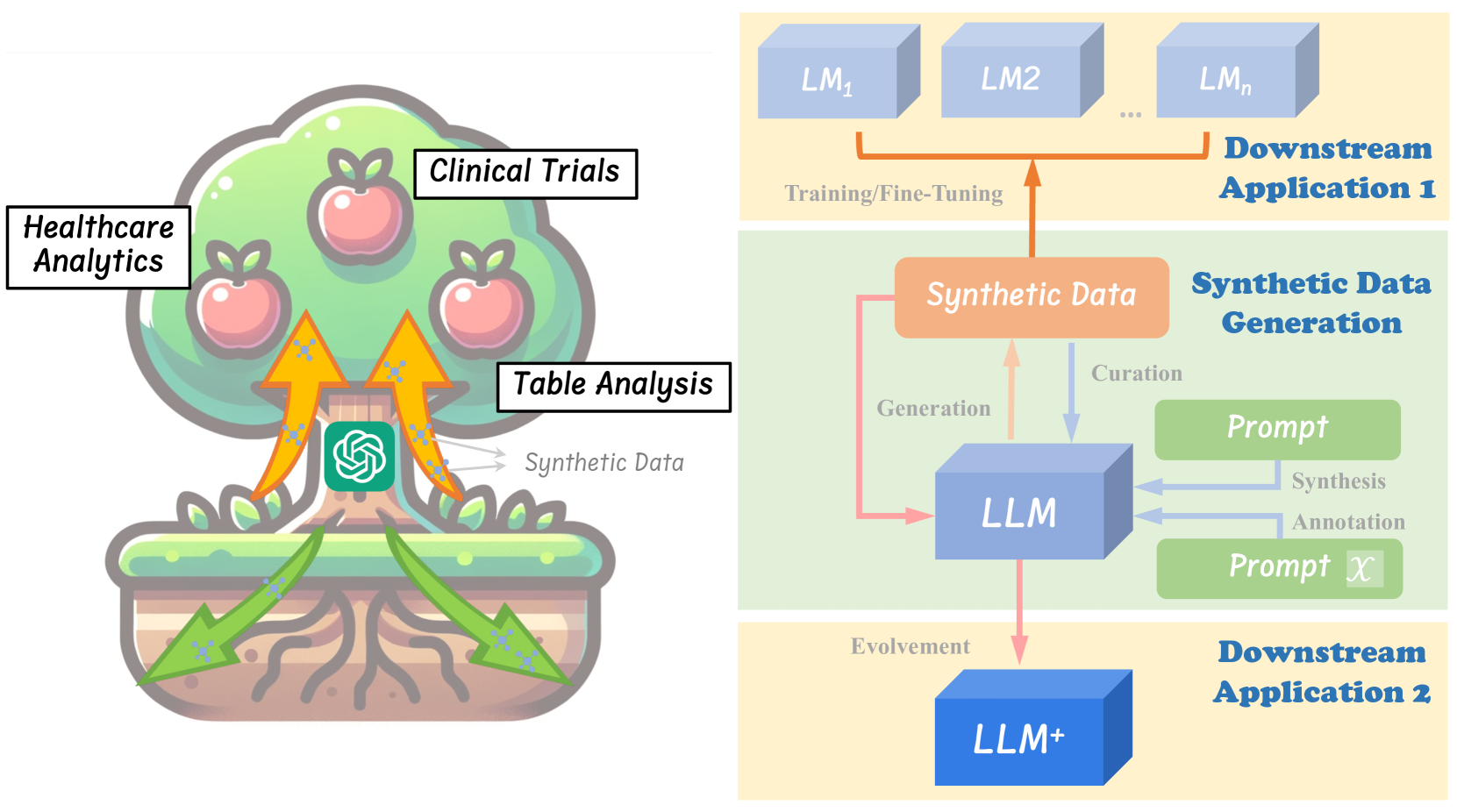
On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation: A Survey
Lin Long, Rui Wang, Ruixuan Xiao, Junbo Zhao, Xiao Ding, Gang Chen, Haobo Wang
Within the evolving landscape of deep learning, the dilemma of data quantity and quality has been a long-standing problem. The recent advent of Large Language Models (LLMs) offers a data-centric solution to alleviate the limitations of real-world data with synthetic data generation. However, current investigations into this field lack a unified framework and mostly stay on the surface. Therefore, this paper provides an organization of relevant studies based on a generic workflow of synthetic data generation. By doing so, we highlight the gaps within existing research and outline prospective avenues for future study. This work aims to shepherd the academic and industrial communities towards deeper, more methodical inquiries into the capabilities and applications of LLMs-driven synthetic data generation.
Read more6/24/2024
📉
0
Towards Faithful and Robust LLM Specialists for Evidence-Based Question-Answering
Tobias Schimanski, Jingwei Ni, Mathias Kraus, Elliott Ash, Markus Leippold
Advances towards more faithful and traceable answers of Large Language Models (LLMs) are crucial for various research and practical endeavors. One avenue in reaching this goal is basing the answers on reliable sources. However, this Evidence-Based QA has proven to work insufficiently with LLMs in terms of citing the correct sources (source quality) and truthfully representing the information within sources (answer attributability). In this work, we systematically investigate how to robustly fine-tune LLMs for better source quality and answer attributability. Specifically, we introduce a data generation pipeline with automated data quality filters, which can synthesize diversified high-quality training and testing data at scale. We further introduce four test sets to benchmark the robustness of fine-tuned specialist models. Extensive evaluation shows that fine-tuning on synthetic data improves performance on both in- and out-of-distribution. Furthermore, we show that data quality, which can be drastically improved by proposed quality filters, matters more than quantity in improving Evidence-Based QA.
Read more6/4/2024