An Empirical Study of Validating Synthetic Data for Formula Generation

0

Sign in to get full access
Overview
- This paper presents an empirical study on validating synthetic data for formula generation.
- The researchers explored the use of large language models (LLMs) to generate synthetic mathematical formulas and investigated techniques to evaluate the quality and fidelity of the generated data.
- The study provides insights into the challenges and best practices for leveraging synthetic data in formula-related applications, such as formula generation and mathematical reasoning.
Plain English Explanation
The researchers in this study looked at using large language models (LLMs) to generate artificial or "synthetic" mathematical formulas. These synthetic formulas could potentially be used to train machine learning models for tasks like formula generation or mathematical reasoning.
The key idea is that by generating a large amount of synthetic formulas, you can create a dataset that can be used to train these models, potentially overcoming the challenge of obtaining enough real-world formulas. However, the researchers wanted to understand how to validate and ensure the quality of the synthetic formulas, so that the models trained on this data would perform well.
They explored different techniques to evaluate the synthetic formulas, looking at factors like how realistic they are, how well they cover the distribution of real formulas, and whether models trained on the synthetic data can perform well on real-world tasks. The insights from this study provide guidance on best practices for effectively leveraging synthetic data in formula-related applications.
Technical Explanation
The researchers conducted an empirical study to investigate methods for validating synthetic data generated using large language models (LLMs) for the task of formula generation. They explored various techniques to evaluate the quality and fidelity of the synthetic formulas, including:
- Comparing the statistical properties (e.g., token frequencies, formula lengths) of the synthetic and real formulas to assess how well the synthetic data matches the distribution of real-world data.
- Evaluating the semantic and structural correctness of the generated formulas using rule-based and machine learning-based approaches.
- Assessing the performance of models trained on the synthetic data when applied to real-world formula-related tasks, such as formula generation and mathematical reasoning.
The researchers found that while LLMs can generate a large number of synthetic formulas, validating the quality and fidelity of the data is crucial for ensuring the models trained on this data perform well on real-world tasks. They also identified key challenges and potential pitfalls in using synthetic data, and provided best practices and lessons learned from their study.
Critical Analysis
The paper provides a comprehensive and rigorous investigation of the challenges and best practices for validating synthetic data generated using LLMs for formula-related applications. The researchers have acknowledged the limitations of their study, such as the need for more diverse datasets and the potential biases introduced by the LLM training process.
One potential concern is the generalizability of the findings, as the study was focused on a specific domain of mathematical formulas. It would be valuable to see similar investigations in other domains, such as natural language processing or computer vision, to better understand the broader implications of using synthetic data generated by LLMs.
Furthermore, the paper does not explore the potential impact of using synthetic data on the fairness and ethical considerations of the resulting models. This is an important area for future research, as the use of synthetic data may introduce new biases or amplify existing ones.
Conclusion
This empirical study provides valuable insights into the challenges and best practices for validating synthetic data generated using large language models for formula-related applications. The researchers have demonstrated the importance of thoroughly evaluating the quality and fidelity of synthetic data to ensure that models trained on this data can perform well on real-world tasks.
The findings from this study can inform the development of robust synthetic data generation and validation techniques, ultimately contributing to the advancement of formula-related applications and the broader field of machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
An Empirical Study of Validating Synthetic Data for Formula Generation
Usneek Singh, Jos'e Cambronero, Sumit Gulwani, Aditya Kanade, Anirudh Khatry, Vu Le, Mukul Singh, Gust Verbruggen
Large language models (LLMs) can be leveraged to help with writing formulas in spreadsheets, but resources on these formulas are scarce, impacting both the base performance of pre-trained models and limiting the ability to fine-tune them. Given a corpus of formulas, we can use a(nother) model to generate synthetic natural language utterances for fine-tuning. However, it is important to validate whether the NL generated by the LLM is indeed accurate to be beneficial for fine-tuning. In this paper, we provide empirical results on the impact of validating these synthetic training examples with surrogate objectives that evaluate the accuracy of the synthetic annotations. We demonstrate that validation improves performance over raw data across four models (2 open and 2 closed weight). Interestingly, we show that although validation tends to prune more challenging examples, it increases the complexity of problems that models can solve after being fine-tuned on validated data.
Read more7/24/2024

0
Data Generation using Large Language Models for Text Classification: An Empirical Case Study
Yinheng Li, Rogerio Bonatti, Sara Abdali, Justin Wagle, Kazuhito Koishida
Using Large Language Models (LLMs) to generate synthetic data for model training has become increasingly popular in recent years. While LLMs are capable of producing realistic training data, the effectiveness of data generation is influenced by various factors, including the choice of prompt, task complexity, and the quality, quantity, and diversity of the generated data. In this work, we focus exclusively on using synthetic data for text classification tasks. Specifically, we use natural language understanding (NLU) models trained on synthetic data to assess the quality of synthetic data from different generation approaches. This work provides an empirical analysis of the impact of these factors and offers recommendations for better data generation practices.
Read more7/23/2024
0
On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation: A Survey
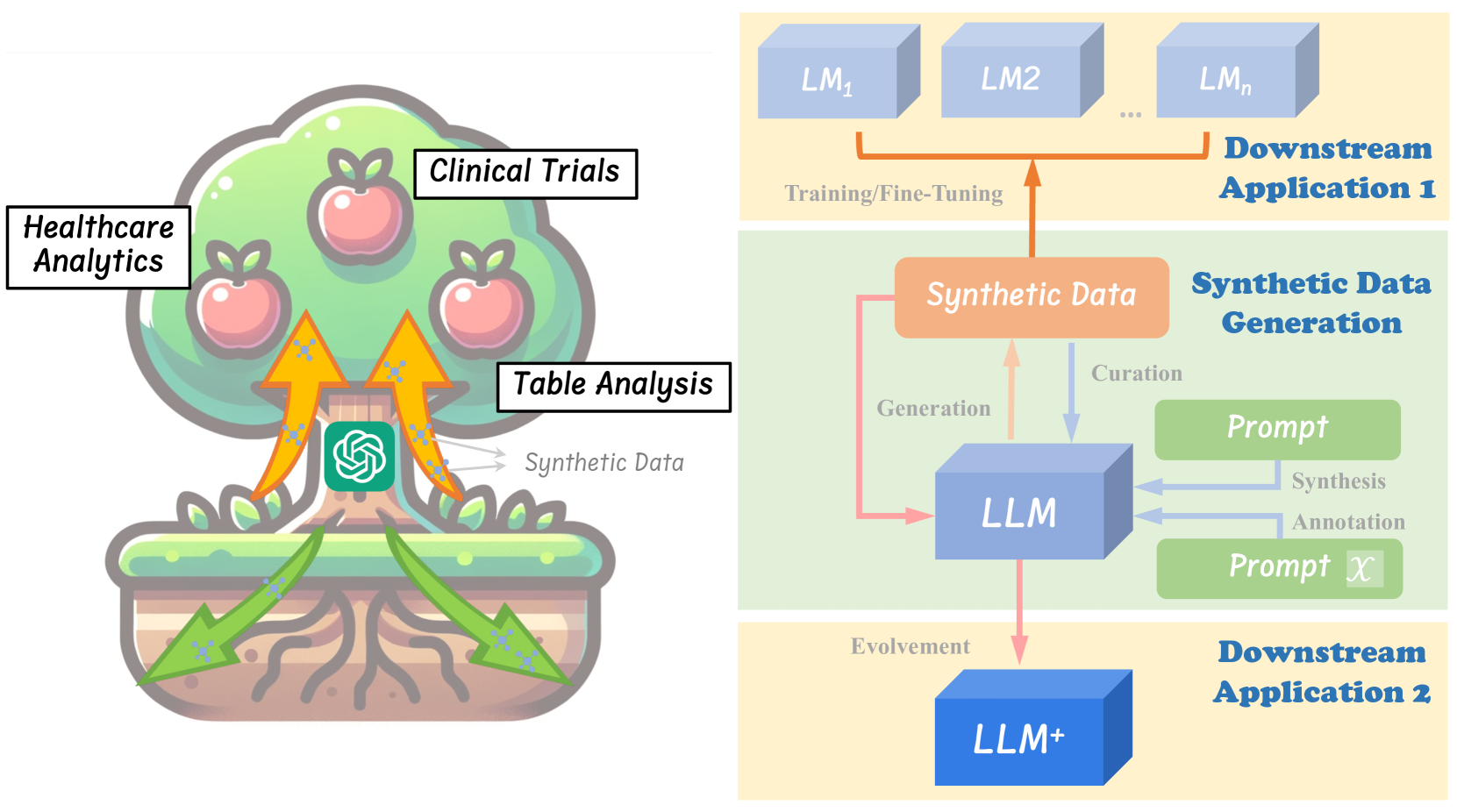
Lin Long, Rui Wang, Ruixuan Xiao, Junbo Zhao, Xiao Ding, Gang Chen, Haobo Wang
Within the evolving landscape of deep learning, the dilemma of data quantity and quality has been a long-standing problem. The recent advent of Large Language Models (LLMs) offers a data-centric solution to alleviate the limitations of real-world data with synthetic data generation. However, current investigations into this field lack a unified framework and mostly stay on the surface. Therefore, this paper provides an organization of relevant studies based on a generic workflow of synthetic data generation. By doing so, we highlight the gaps within existing research and outline prospective avenues for future study. This work aims to shepherd the academic and industrial communities towards deeper, more methodical inquiries into the capabilities and applications of LLMs-driven synthetic data generation.
Read more6/24/2024
0
A Multi-Faceted Evaluation Framework for Assessing Synthetic Data Generated by Large Language Models
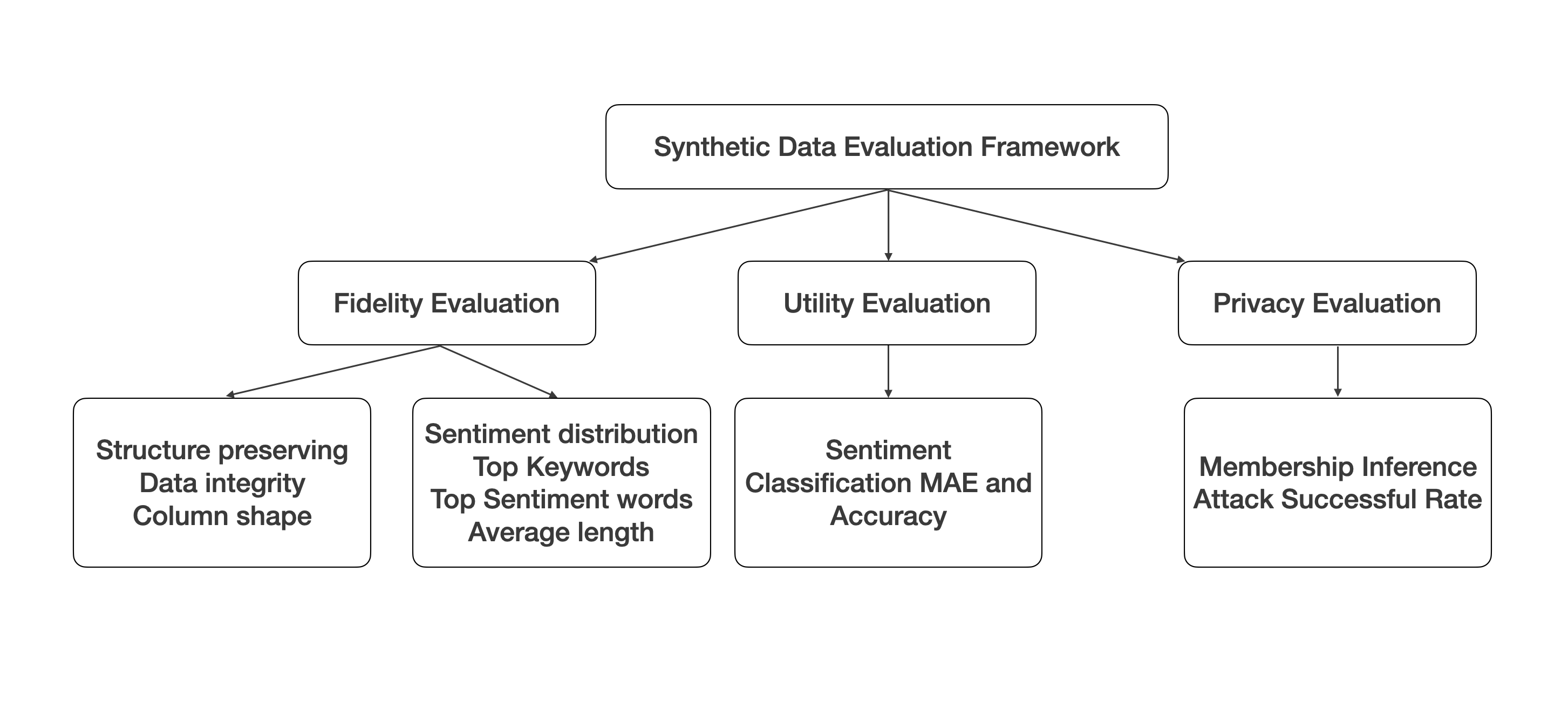
Yefeng Yuan, Yuhong Liu, Liang Cheng
The rapid advancements in generative AI and large language models (LLMs) have opened up new avenues for producing synthetic data, particularly in the realm of structured tabular formats, such as product reviews. Despite the potential benefits, concerns regarding privacy leakage have surfaced, especially when personal information is utilized in the training datasets. In addition, there is an absence of a comprehensive evaluation framework capable of quantitatively measuring the quality of the generated synthetic data and their utility for downstream tasks. In response to this gap, we introduce SynEval, an open-source evaluation framework designed to assess the fidelity, utility, and privacy preservation of synthetically generated tabular data via a suite of diverse evaluation metrics. We validate the efficacy of our proposed framework - SynEval - by applying it to synthetic product review data generated by three state-of-the-art LLMs: ChatGPT, Claude, and Llama. Our experimental findings illuminate the trade-offs between various evaluation metrics in the context of synthetic data generation. Furthermore, SynEval stands as a critical instrument for researchers and practitioners engaged with synthetic tabular data,, empowering them to judiciously determine the suitability of the generated data for their specific applications, with an emphasis on upholding user privacy.
Read more4/24/2024