Efficacy of Synthetic Data as a Benchmark

0
📊
Sign in to get full access
Overview
- The paper examines the efficacy of using synthetic data as a benchmark for evaluating machine learning models, particularly in the context of natural language processing (NLP).
- It investigates whether models trained on synthetic data can generalize to real-world data and how this compares to models trained on real data.
- The researchers propose a rigorous evaluation protocol and apply it to several NLP tasks, using both synthetic and real data.
Plain English Explanation
The research paper explores the use of synthetic data as a way to test and evaluate machine learning models, particularly those focused on natural language processing (NLP). Synthetic data is data that is artificially generated, rather than collected from real-world sources.
The key question the paper aims to answer is: Can models trained on synthetic data perform well on real-world data, or do they only work well on the synthetic data they were trained on? In other words, does training on synthetic data lead to models that can generalize well, or are they overly specialized to the synthetic data?
To investigate this, the researchers developed a structured evaluation protocol. They tested several NLP models, training some on synthetic data and others on real-world data, and then comparing how well each model performed on both synthetic and real-world test sets. This allowed them to assess the generalization capabilities of the models.
Technical Explanation
The paper first outlines the setup and evaluation protocol used in the study. This includes details on the synthetic data generation process, the NLP tasks evaluated, and the specific metrics used to assess model performance.
The researchers then present the results of their experiments, which cover several common NLP tasks such as text classification, named entity recognition, and natural language inference. They compare the performance of models trained on synthetic data versus those trained on real data, both on the synthetic test sets and the real-world test sets.
The key finding is that while models trained on synthetic data can perform well on the synthetic test sets, they often struggle to generalize to real-world data. In contrast, models trained on real-world data tend to perform better on both synthetic and real-world test sets.
Critical Analysis
The paper acknowledges several limitations and areas for further research. For example, the synthetic data generation process may not fully capture the complexity and nuances of real-world language, which could limit the generalization ability of models trained on synthetic data.
Additionally, the paper does not explore the impact of different synthetic data generation techniques or the potential benefits of combining synthetic and real-world data during training. There may be ways to improve the efficacy of synthetic data as a benchmark by addressing these factors.
The researchers also note that the specific results may vary depending on the NLP task, the model architecture, and other experimental factors. Further research is needed to understand the broader applicability and limitations of using synthetic data as a benchmark.
Conclusion
This paper provides important insights into the use of synthetic data as a benchmark for evaluating NLP models. While synthetic data can be a useful tool, the research suggests that caution is warranted when relying solely on synthetic data to assess model performance.
The findings highlight the importance of evaluating models on real-world data to ensure they can generalize beyond the specific synthetic environments they were trained on. As the use of large language models (LLMs) and synthetic data generation continues to grow, this paper offers valuable guidance on best practices and the limitations of these approaches.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Efficacy of Synthetic Data as a Benchmark
Gaurav Maheshwari, Dmitry Ivanov, Kevin El Haddad
Large language models (LLMs) have enabled a range of applications in zero-shot and few-shot learning settings, including the generation of synthetic datasets for training and testing. However, to reliably use these synthetic datasets, it is essential to understand how representative they are of real-world data. We investigate this by assessing the effectiveness of generating synthetic data through LLM and using it as a benchmark for various NLP tasks. Our experiments across six datasets, and three different tasks, show that while synthetic data can effectively capture performance of various methods for simpler tasks, such as intent classification, it falls short for more complex tasks like named entity recognition. Additionally, we propose a new metric called the bias factor, which evaluates the biases introduced when the same LLM is used to both generate benchmarking data and to perform the tasks. We find that smaller LLMs exhibit biases towards their own generated data, whereas larger models do not. Overall, our findings suggest that the effectiveness of synthetic data as a benchmark varies depending on the task, and that practitioners should rely on data generated from multiple larger models whenever possible.
Read more9/19/2024

0
Best Practices and Lessons Learned on Synthetic Data for Language Models
Ruibo Liu, Jerry Wei, Fangyu Liu, Chenglei Si, Yanzhe Zhang, Jinmeng Rao, Steven Zheng, Daiyi Peng, Diyi Yang, Denny Zhou, Andrew M. Dai
The success of AI models relies on the availability of large, diverse, and high-quality datasets, which can be challenging to obtain due to data scarcity, privacy concerns, and high costs. Synthetic data has emerged as a promising solution by generating artificial data that mimics real-world patterns. This paper provides an overview of synthetic data research, discussing its applications, challenges, and future directions. We present empirical evidence from prior art to demonstrate its effectiveness and highlight the importance of ensuring its factuality, fidelity, and unbiasedness. We emphasize the need for responsible use of synthetic data to build more powerful, inclusive, and trustworthy language models.
Read more8/13/2024

0
Quality Matters: Evaluating Synthetic Data for Tool-Using LLMs
Shadi Iskander, Nachshon Cohen, Zohar Karnin, Ori Shapira, Sofia Tolmach
Training large language models (LLMs) for external tool usage is a rapidly expanding field, with recent research focusing on generating synthetic data to address the shortage of available data. However, the absence of systematic data quality checks poses complications for properly training and testing models. To that end, we propose two approaches for assessing the reliability of data for training LLMs to use external tools. The first approach uses intuitive, human-defined correctness criteria. The second approach uses a model-driven assessment with in-context evaluation. We conduct a thorough evaluation of data quality on two popular benchmarks, followed by an extrinsic evaluation that showcases the impact of data quality on model performance. Our results demonstrate that models trained on high-quality data outperform those trained on unvalidated data, even when trained with a smaller quantity of data. These findings empirically support the significance of assessing and ensuring the reliability of training data for tool-using LLMs.
Read more9/27/2024
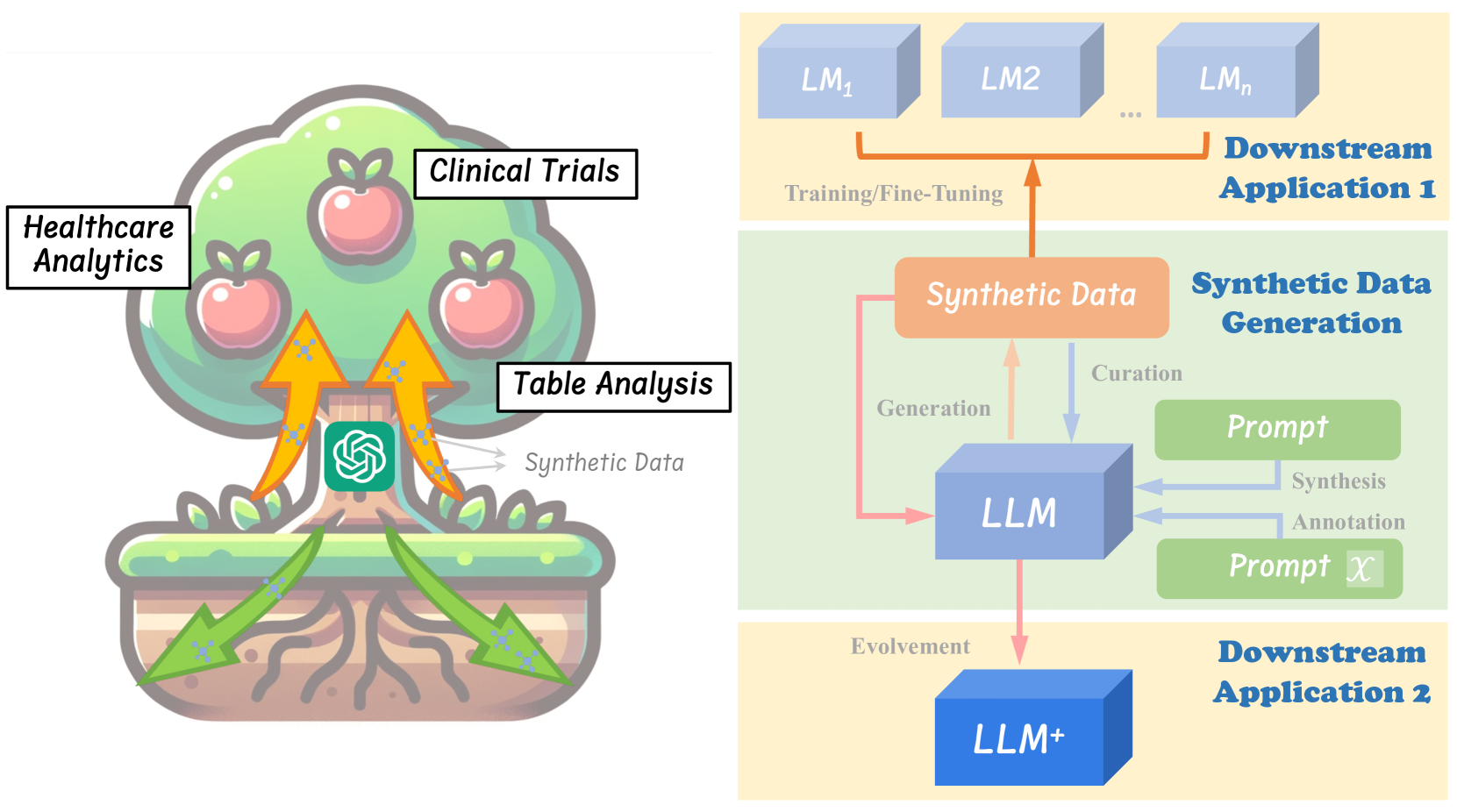
0
On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation: A Survey
Lin Long, Rui Wang, Ruixuan Xiao, Junbo Zhao, Xiao Ding, Gang Chen, Haobo Wang
Within the evolving landscape of deep learning, the dilemma of data quantity and quality has been a long-standing problem. The recent advent of Large Language Models (LLMs) offers a data-centric solution to alleviate the limitations of real-world data with synthetic data generation. However, current investigations into this field lack a unified framework and mostly stay on the surface. Therefore, this paper provides an organization of relevant studies based on a generic workflow of synthetic data generation. By doing so, we highlight the gaps within existing research and outline prospective avenues for future study. This work aims to shepherd the academic and industrial communities towards deeper, more methodical inquiries into the capabilities and applications of LLMs-driven synthetic data generation.
Read more6/24/2024