QuantFactor REINFORCE: Mining Steady Formulaic Alpha Factors with Variance-bounded REINFORCE

0
Sign in to get full access
Overview
- This paper proposes a reinforcement learning-based method called "QuantFactor REINFORCE" for mining steady, formulaic alpha factors for quantitative trading.
- The key ideas are to use a variance-bounded REINFORCE algorithm to learn stable, interpretable factor formulas, and to enforce steady factor performance over time.
- The authors demonstrate the effectiveness of their approach on real-world financial datasets, showing that it can outperform traditional factor engineering and machine learning methods.
Plain English Explanation
The paper introduces a new reinforcement learning technique called "QuantFactor REINFORCE" that can be used to automatically discover profitable trading strategies, or "alpha factors," for quantitative finance.
The main challenge in quantitative trading is finding reliable patterns in financial data that can be turned into profitable trading rules. Traditionally, this has involved a lot of manual feature engineering and optimization by human experts. The QuantFactor REINFORCE method aims to automate this process using reinforcement learning.
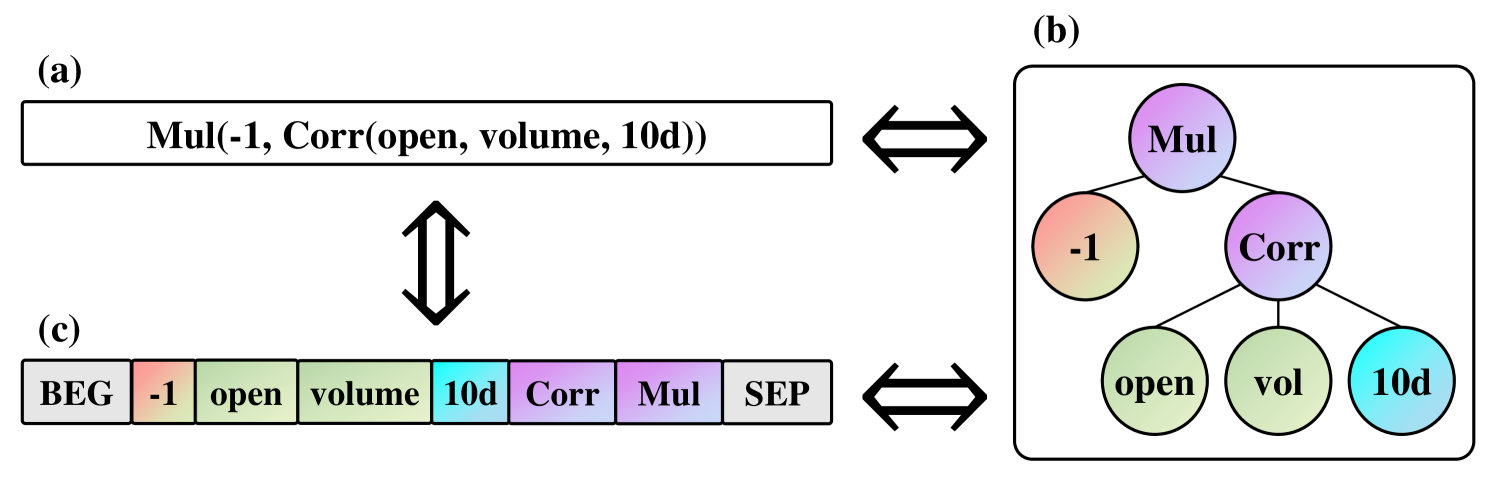
The key idea is to set up the problem as a Markov Decision Process, where the agent (the trading algorithm) learns to construct a profitable formula from a set of basic financial indicators. The REINFORCE algorithm is used to guide this learning process, but with an added constraint to encourage the agent to find "steady" formulas - ones that maintain consistent performance over time rather than just optimizing for short-term profits.
By incorporating this stability objective, the authors show that QuantFactor REINFORCE can uncover trading strategies that are not only profitable, but also interpretable and reliable in real-world deployment. The experiments demonstrate that this approach outperforms traditional quantitative trading methods on several financial datasets.
Technical Explanation
The core of the QuantFactor REINFORCE approach is a reinforcement learning framework for automatically generating profitable trading factor formulas. The authors model this as a Markov Decision Process (MDP), where the agent's actions correspond to selecting financial indicators and combining them into a factor formula.
The reward function for the agent is designed to optimize for both profitability and stability of the learned factors. Specifically, the reward incorporates the Sharpe ratio of the factor's returns, as well as a "variance-bounded" term that penalizes factors with high variance in their performance over time.
The REINFORCE algorithm is used to train the agent to navigate this MDP and discover high-performing, stable factor formulas. REINFORCE is a policy gradient method that updates the agent's action selection probabilities based on the rewards it receives.
The authors also introduce several enhancements to the basic REINFORCE algorithm, such as using importance sampling to reduce variance in the gradient estimates and incorporating an entropy regularization term to encourage exploration.
Experiments on real-world financial datasets show that QuantFactor REINFORCE is able to discover profitable alpha factors that outperform both traditional factor engineering approaches and generic machine learning methods. The learned factors also exhibit more consistent performance over time compared to these baselines.
Critical Analysis
The QuantFactor REINFORCE method represents an interesting application of reinforcement learning to the problem of quantitative trading. By incorporating a stability objective into the reward function, the authors are able to uncover factor formulas that are not only profitable, but also reliable and interpretable.
One potential limitation is that the MDP formulation may struggle to capture higher-order interactions between financial indicators. An alternative approach could be to use a more expressive function approximator, such as a neural network, to represent the factor formulas.
Another area for further research could be to investigate how QuantFactor REINFORCE performs on datasets with different properties, such as higher-frequency trading or more complex, non-linear patterns.
Finally, the authors do not explore the potential for multi-agent or hierarchical reinforcement learning approaches, which could allow the discovery of more sophisticated trading strategies.
Overall, the QuantFactor REINFORCE method represents a promising step forward in the application of reinforcement learning to quantitative finance, and the authors' focus on stability and interpretability is a valuable contribution to the field.
Conclusion
The QuantFactor REINFORCE paper proposes a new reinforcement learning-based approach for automatically discovering profitable and stable trading factor formulas. By incorporating a variance-bounded reward function, the method is able to uncover interpretable strategies that maintain consistent performance over time, outperforming traditional quantitative trading methods.
This work demonstrates the potential of reinforcement learning to automate the challenging task of quantitative trading, and could have significant implications for the finance industry. As financial markets become increasingly complex, the ability to rapidly discover reliable trading strategies could give firms a significant competitive edge.
Moving forward, further research into more advanced reinforcement learning techniques, as well as their application to a wider range of financial datasets and problems, could lead to even more powerful and impactful tools for quantitative finance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
QuantFactor REINFORCE: Mining Steady Formulaic Alpha Factors with Variance-bounded REINFORCE
Junjie Zhao, Chengxi Zhang, Min Qin, Peng Yang
The goal of alpha factor mining is to discover indicative signals of investment opportunities from the historical financial market data of assets. Deep learning based alpha factor mining methods have shown to be powerful, which, however, lack of the interpretability, making them unacceptable in the risk-sensitive real markets. Alpha factors in formulaic forms are more interpretable and therefore favored by market participants, while the search space is complex and powerful explorative methods are urged. Recently, a promising framework is proposed for generating formulaic alpha factors using deep reinforcement learning, and quickly gained research focuses from both academia and industries. This paper first argues that the originally employed policy training method, i.e., Proximal Policy Optimization (PPO), faces several important issues in the context of alpha factors mining, making it ineffective to explore the search space of the formula. Herein, a novel reinforcement learning based on the well-known REINFORCE algorithm is proposed. Given that the underlying state transition function adheres to the Dirac distribution, the Markov Decision Process within this framework exhibit minimal environmental variability, making REINFORCE algorithm more appropriate than PPO. A new dedicated baseline is designed to theoretically reduce the commonly suffered high variance of REINFORCE. Moreover, the information ratio is introduced as a reward shaping mechanism to encourage the generation of steady alpha factors that can better adapt to changes in market volatility. Experimental evaluations on various real assets data show that the proposed algorithm can increase the correlation with asset returns by 3.83%, and a stronger ability to obtain excess returns compared to the latest alpha factors mining methods, which meets the theoretical results well.
Read more9/10/2024

0
Synergistic Formulaic Alpha Generation for Quantitative Trading based on Reinforcement Learning
Hong-Gi Shin, Sukhyun Jeong, Eui-Yeon Kim, Sungho Hong, Young-Jin Cho, Yong-Hoon Choi
Mining of formulaic alpha factors refers to the process of discovering and developing specific factors or indicators (referred to as alpha factors) for quantitative trading in stock market. To efficiently discover alpha factors in vast search space, reinforcement learning (RL) is commonly employed. This paper proposes a method to enhance existing alpha factor mining approaches by expanding a search space and utilizing pretrained formulaic alpha set as initial seed values to generate synergistic formulaic alpha. We employ information coefficient (IC) and rank information coefficient (Rank IC) as performance evaluation metrics for the model. Using CSI300 market data, we conducted real investment simulations and observed significant performance improvement compared to existing techniques.
Read more7/9/2024

0
AlphaForge: A Framework to Mine and Dynamically Combine Formulaic Alpha Factors
Hao Shi, Weili Song, Xinting Zhang, Jiahe Shi, Cuicui Luo, Xiang Ao, Hamid Arian, Luis Seco
The complexity of financial data, characterized by its variability and low signal-to-noise ratio, necessitates advanced methods in quantitative investment that prioritize both performance and interpretability.Transitioning from early manual extraction to genetic programming, the most advanced approach in the alpha factor mining domain currently employs reinforcement learning to mine a set of combination factors with fixed weights. However, the performance of resultant alpha factors exhibits inconsistency, and the inflexibility of fixed factor weights proves insufficient in adapting to the dynamic nature of financial markets. To address this issue, this paper proposes a two-stage formulaic alpha generating framework AlphaForge, for alpha factor mining and factor combination. This framework employs a generative-predictive neural network to generate factors, leveraging the robust spatial exploration capabilities inherent in deep learning while concurrently preserving diversity. The combination model within the framework incorporates the temporal performance of factors for selection and dynamically adjusts the weights assigned to each component alpha factor. Experiments conducted on real-world datasets demonstrate that our proposed model outperforms contemporary benchmarks in formulaic alpha factor mining. Furthermore, our model exhibits a notable enhancement in portfolio returns within the realm of quantitative investment and real money investment.
Read more8/29/2024

0
$text{Alpha}^2$: Discovering Logical Formulaic Alphas using Deep Reinforcement Learning
Feng Xu, Yan Yin, Xinyu Zhang, Tianyuan Liu, Shengyi Jiang, Zongzhang Zhang
Alphas are pivotal in providing signals for quantitative trading. The industry highly values the discovery of formulaic alphas for their interpretability and ease of analysis, compared with the expressive yet overfitting-prone black-box alphas. In this work, we focus on discovering formulaic alphas. Prior studies on automatically generating a collection of formulaic alphas were mostly based on genetic programming (GP), which is known to suffer from the problems of being sensitive to the initial population, converting to local optima, and slow computation speed. Recent efforts employing deep reinforcement learning (DRL) for alpha discovery have not fully addressed key practical considerations such as alpha correlations and validity, which are crucial for their effectiveness. In this work, we propose a novel framework for alpha discovery using DRL by formulating the alpha discovery process as program construction. Our agent, $text{Alpha}^2$, assembles an alpha program optimized for an evaluation metric. A search algorithm guided by DRL navigates through the search space based on value estimates for potential alpha outcomes. The evaluation metric encourages both the performance and the diversity of alphas for a better final trading strategy. Our formulation of searching alphas also brings the advantage of pre-calculation dimensional analysis, ensuring the logical soundness of alphas, and pruning the vast search space to a large extent. Empirical experiments on real-world stock markets demonstrates $text{Alpha}^2$'s capability to identify a diverse set of logical and effective alphas, which significantly improves the performance of the final trading strategy. The code of our method is available at https://github.com/x35f/alpha2.
Read more6/27/2024