Query Performance Prediction using Relevance Judgments Generated by Large Language Models
2404.01012
0
0
Abstract
Query performance prediction (QPP) aims to estimate the retrieval quality of a search system for a query without human relevance judgments. Previous QPP methods typically return a single scalar value and do not require the predicted values to approximate a specific information retrieval (IR) evaluation measure, leading to certain drawbacks: (i) a single scalar is insufficient to accurately represent different IR evaluation measures, especially when metrics do not highly correlate, and (ii) a single scalar limits the interpretability of QPP methods because solely using a scalar is insufficient to explain QPP results. To address these issues, we propose a QPP framework using automatically generated relevance judgments (QPP-GenRE), which decomposes QPP into independent subtasks of predicting the relevance of each item in a ranked list to a given query. This allows us to predict any IR evaluation measure using the generated relevance judgments as pseudo-labels. This also allows us to interpret predicted IR evaluation measures, and identify, track and rectify errors in generated relevance judgments to improve QPP quality. We predict an item's relevance by using open-source large language models (LLMs) to ensure scientific reproducibility. We face two main challenges: (i) excessive computational costs of judging an entire corpus for predicting a metric considering recall, and (ii) limited performance in prompting open-source LLMs in a zero-/few-shot manner. To solve the challenges, we devise an approximation strategy to predict an IR measure considering recall and propose to fine-tune open-source LLMs using human-labeled relevance judgments. Experiments on the TREC 2019-2022 deep learning tracks show that QPP-GenRE achieves state-of-the-art QPP quality for both lexical and neural rankers.
Create account to get full access
Overview
- This paper explores the use of large language models (LLMs) to generate relevance judgments for query performance prediction.
- The researchers investigate whether LLM-generated relevance judgments can be used to accurately predict search query performance, which is an important task in information retrieval.
- The paper presents experiments on several benchmark datasets and compares the performance of LLM-based approaches to traditional methods for query performance prediction.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. In this research, the authors explore how LLMs can be used to assess the quality of search engine results.
When you search for something online, search engines try to return the most relevant information. But measuring how well a search query performs, or "query performance prediction," is a challenging task. The researchers wanted to see if LLMs could help with this problem.
The idea is that LLMs could analyze the search results and provide "relevance judgments" - assessments of how well each result matches the original query. The researchers then tested whether these LLM-generated relevance judgments could be used to accurately predict how well a search query performed, compared to traditional methods.
The experiments showed promising results, suggesting that LLMs can be a useful tool for improving search engine performance and helping users find the information they're looking for more effectively. By leveraging the language understanding capabilities of LLMs, this research opens up new possibilities for enhancing online search and information retrieval.
Technical Explanation
The paper presents a novel approach to query performance prediction that leverages relevance judgments generated by large language models (LLMs).
The researchers first fine-tuned a pre-trained LLM on a dataset of human-annotated relevance judgments. This allowed the LLM to learn how to assess the relevance of search results to a given query. They then used this fine-tuned LLM to generate relevance judgments for additional search result datasets.
Next, the paper explores how these LLM-generated relevance judgments can be used to predict query performance. The authors experimented with several machine learning models that take the LLM-generated relevance scores as input and output a prediction of the query's performance.
The results show that the LLM-based approach outperforms traditional query performance prediction methods across multiple benchmark datasets. This suggests that the language understanding capabilities of large language models can provide valuable insights for information retrieval tasks like predicting searcher satisfaction and consolidating relevance predictions.
Critical Analysis
The paper presents a compelling approach, but there are a few caveats to consider. First, the performance of the LLM-based method is still dependent on the quality of the initial human-annotated relevance judgments used for fine-tuning. If this training data is biased or incomplete, it could limit the LLM's ability to accurately assess relevance.
Additionally, the paper only evaluates the approach on English-language datasets. It would be valuable to see how well the LLM-based method performs on other languages, as language models can sometimes struggle with linguistic and cultural nuances outside their primary training domain.
Finally, the paper does not explore the interpretability of the LLM-generated relevance judgments. Understanding the reasoning behind the model's assessments could be important for building user trust and transparency in real-world search applications.
Overall, this research represents an exciting step forward in leveraging the power of large language models for information retrieval tasks. With further exploration and refinement, the techniques presented in this paper could lead to significant improvements in search engine performance and user satisfaction.
Conclusion
This paper demonstrates that large language models can be effectively leveraged to generate relevance judgments for search queries, which can then be used to accurately predict query performance.
By fine-tuning LLMs on human-annotated relevance data, the researchers were able to develop models that can assess the relevance of search results in a way that correlates well with traditional query performance metrics. This suggests that LLMs can provide valuable insights for enhancing information retrieval systems and helping users find the information they need more effectively.
While there are some limitations to the current approach, this research opens up new avenues for using advanced language AI to tackle challenging problems in search and content discovery. As LLMs continue to evolve, we can expect to see more innovative applications of these powerful models across a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
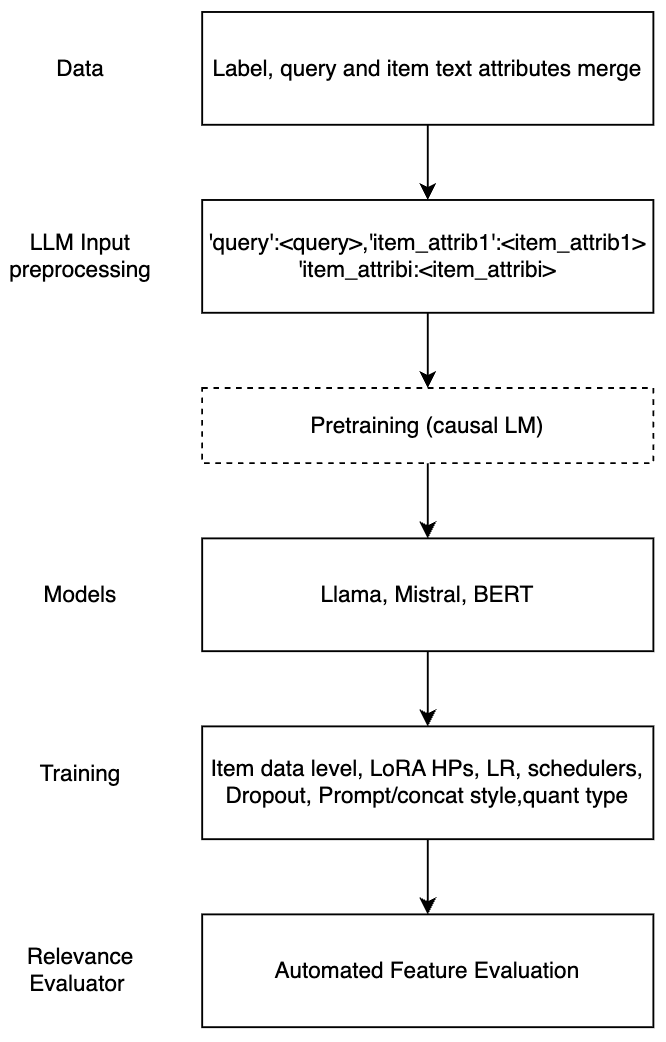
Large Language Models for Relevance Judgment in Product Search
Navid Mehrdad, Hrushikesh Mohapatra, Mossaab Bagdouri, Prijith Chandran, Alessandro Magnani, Xunfan Cai, Ajit Puthenputhussery, Sachin Yadav, Tony Lee, ChengXiang Zhai, Ciya Liao
0
0
High relevance of retrieved and re-ranked items to the search query is the cornerstone of successful product search, yet measuring relevance of items to queries is one of the most challenging tasks in product information retrieval, and quality of product search is highly influenced by the precision and scale of available relevance-labelled data. In this paper, we present an array of techniques for leveraging Large Language Models (LLMs) for automating the relevance judgment of query-item pairs (QIPs) at scale. Using a unique dataset of multi-million QIPs, annotated by human evaluators, we test and optimize hyper parameters for finetuning billion-parameter LLMs with and without Low Rank Adaption (LoRA), as well as various modes of item attribute concatenation and prompting in LLM finetuning, and consider trade offs in item attribute inclusion for quality of relevance predictions. We demonstrate considerable improvement over baselines of prior generations of LLMs, as well as off-the-shelf models, towards relevance annotations on par with the human relevance evaluators. Our findings have immediate implications for the growing field of relevance judgment automation in product search.
6/4/2024
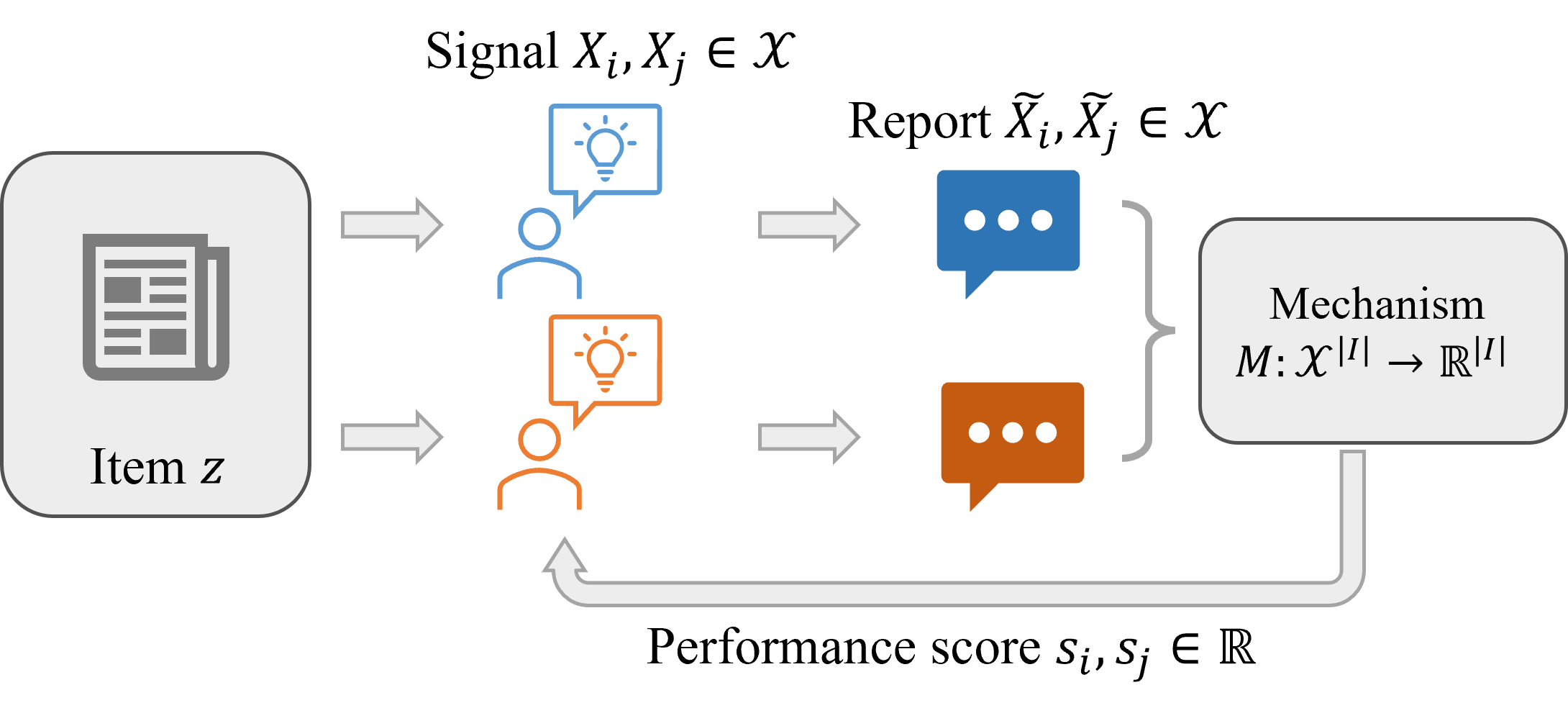
Eliciting Informative Text Evaluations with Large Language Models
Yuxuan Lu, Shengwei Xu, Yichi Zhang, Yuqing Kong, Grant Schoenebeck
0
0
Peer prediction mechanisms motivate high-quality feedback with provable guarantees. However, current methods only apply to rather simple reports, like multiple-choice or scalar numbers. We aim to broaden these techniques to the larger domain of text-based reports, drawing on the recent developments in large language models. This vastly increases the applicability of peer prediction mechanisms as textual feedback is the norm in a large variety of feedback channels: peer reviews, e-commerce customer reviews, and comments on social media. We introduce two mechanisms, the Generative Peer Prediction Mechanism (GPPM) and the Generative Synopsis Peer Prediction Mechanism (GSPPM). These mechanisms utilize LLMs as predictors, mapping from one agent's report to a prediction of her peer's report. Theoretically, we show that when the LLM prediction is sufficiently accurate, our mechanisms can incentivize high effort and truth-telling as an (approximate) Bayesian Nash equilibrium. Empirically, we confirm the efficacy of our mechanisms through experiments conducted on two real datasets: the Yelp review dataset and the ICLR OpenReview dataset. We highlight the results that on the ICLR dataset, our mechanisms can differentiate three quality levels -- human-written reviews, GPT-4-generated reviews, and GPT-3.5-generated reviews in terms of expected scores. Additionally, GSPPM penalizes LLM-generated reviews more effectively than GPPM.
5/29/2024

Consolidating Ranking and Relevance Predictions of Large Language Models through Post-Processing
Le Yan, Zhen Qin, Honglei Zhuang, Rolf Jagerman, Xuanhui Wang, Michael Bendersky, Harrie Oosterhuis
0
0
The powerful generative abilities of large language models (LLMs) show potential in generating relevance labels for search applications. Previous work has found that directly asking about relevancy, such as ``How relevant is document A to query Q?, results in sub-optimal ranking. Instead, the pairwise ranking prompting (PRP) approach produces promising ranking performance through asking about pairwise comparisons, e.g., ``Is document A more relevant than document B to query Q?. Thus, while LLMs are effective at their ranking ability, this is not reflected in their relevance label generation. In this work, we propose a post-processing method to consolidate the relevance labels generated by an LLM with its powerful ranking abilities. Our method takes both LLM generated relevance labels and pairwise preferences. The labels are then altered to satisfy the pairwise preferences of the LLM, while staying as close to the original values as possible. Our experimental results indicate that our approach effectively balances label accuracy and ranking performance. Thereby, our work shows it is possible to combine both the ranking and labeling abilities of LLMs through post-processing.
4/19/2024
Large language models can accurately predict searcher preferences
Paul Thomas, Seth Spielman, Nick Craswell, Bhaskar Mitra
0
0
Relevance labels, which indicate whether a search result is valuable to a searcher, are key to evaluating and optimising search systems. The best way to capture the true preferences of users is to ask them for their careful feedback on which results would be useful, but this approach does not scale to produce a large number of labels. Getting relevance labels at scale is usually done with third-party labellers, who judge on behalf of the user, but there is a risk of low-quality data if the labeller doesn't understand user needs. To improve quality, one standard approach is to study real users through interviews, user studies and direct feedback, find areas where labels are systematically disagreeing with users, then educate labellers about user needs through judging guidelines, training and monitoring. This paper introduces an alternate approach for improving label quality. It takes careful feedback from real users, which by definition is the highest-quality first-party gold data that can be derived, and develops an large language model prompt that agrees with that data. We present ideas and observations from deploying language models for large-scale relevance labelling at Bing, and illustrate with data from TREC. We have found large language models can be effective, with accuracy as good as human labellers and similar capability to pick the hardest queries, best runs, and best groups. Systematic changes to the prompts make a difference in accuracy, but so too do simple paraphrases. To measure agreement with real searchers needs high-quality gold labels, but with these we find that models produce better labels than third-party workers, for a fraction of the cost, and these labels let us train notably better rankers.
5/20/2024